
Tidy Dataset이란?
Tidy dataset은 분석하기 좋은 형태로 구성된 데이터셋을 의미합니다. 이 개념은 Hadley Wickham이라는 데이터 과학자가 제시한 개념으로, 데이터를 가공, 집계, 시각화, 모델링하는 데에 용이한 형태로 정리된 데이터셋을 만드는 프레임워크입니다. Tidy dataset의 구조는 일정한 모양과 규칙을 따르며, 모든 분석하기 좋은 데이터셋은 동일한 구조를 갖습니다. Tidy dataset은 대부분의 데이터 시각화/분석 도구, 언어와 호환되며, 데이터의 가독성과 활용도를 높여주며 아래와 같은 장점이 있습니다.

본 글은 하트카운트 6월 웨비나에서 다룬 내용을 바탕으로 작성되었습니다.
자세한 내용이 궁금하다면 아래 VOD를 확인해보세요!
→ 다음 웨비나 사전 등록하기
왜 Tidy Dataset이 중요한가요?
1.
시각화와 EDA(탐색적 데이터 분석) 용이성: Tidy Dataset은 시각화와 탐색적 데이터 분석에 적합한 형태입니다. 그래프를 그리고 패턴을 찾는 등 데이터를 탐색하는 과정이 훨씬 간편해집니다.
2.
데이터 분석의 일반적 표준: Tidy Dataset은 데이터 분석 도구와 패키지들에서 주로 사용되는 표준입니다. R, 파이썬 등 다양한 도구에서 이러한 구조를 기반으로 한 기능들이 제공됩니다.
3.
데이터 통합의 용이성: 다양한 데이터 소스로부터 데이터를 통합해야 할 때, Tidy Dataset으로 변환하면 데이터 통합 작업이 훨씬 수월해집니다.
Tidy Dataset을 구성하는 방법
Tidy dataset을 만들기 위해서는 다음과 같은 규칙을 따라야 합니다.
1. 데이터셋 행과 열 구성
데이터셋을 분석하기 전에는 각각의 변수가 열(column)로 구성되어야 합니다. 독립적인 변수들은 각각 하나의 열로 존재해야 하며, 동일한 분석 대상에 대한 관측값들은 행(row)으로 구성되어야 합니다.
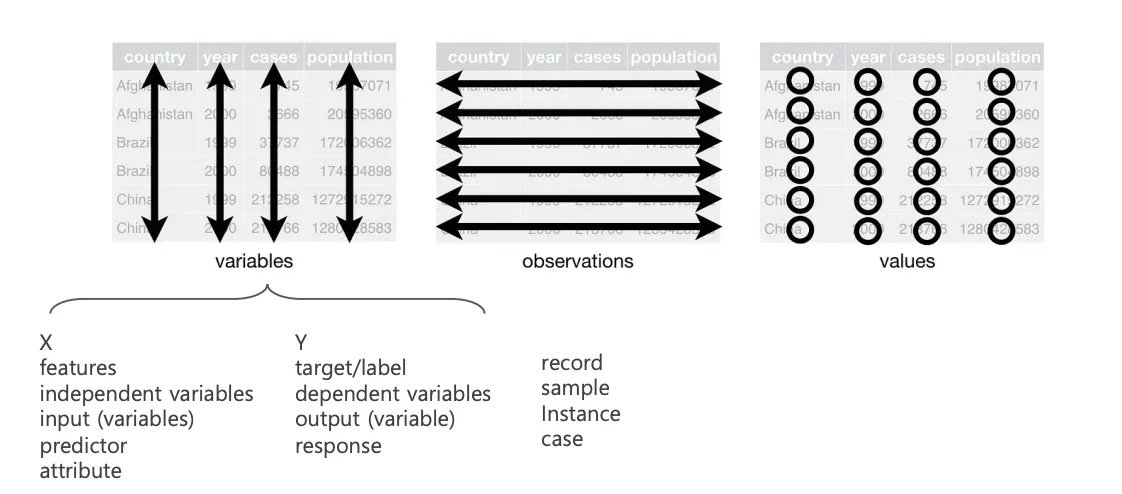
2. 독립적인 변수들의 구분
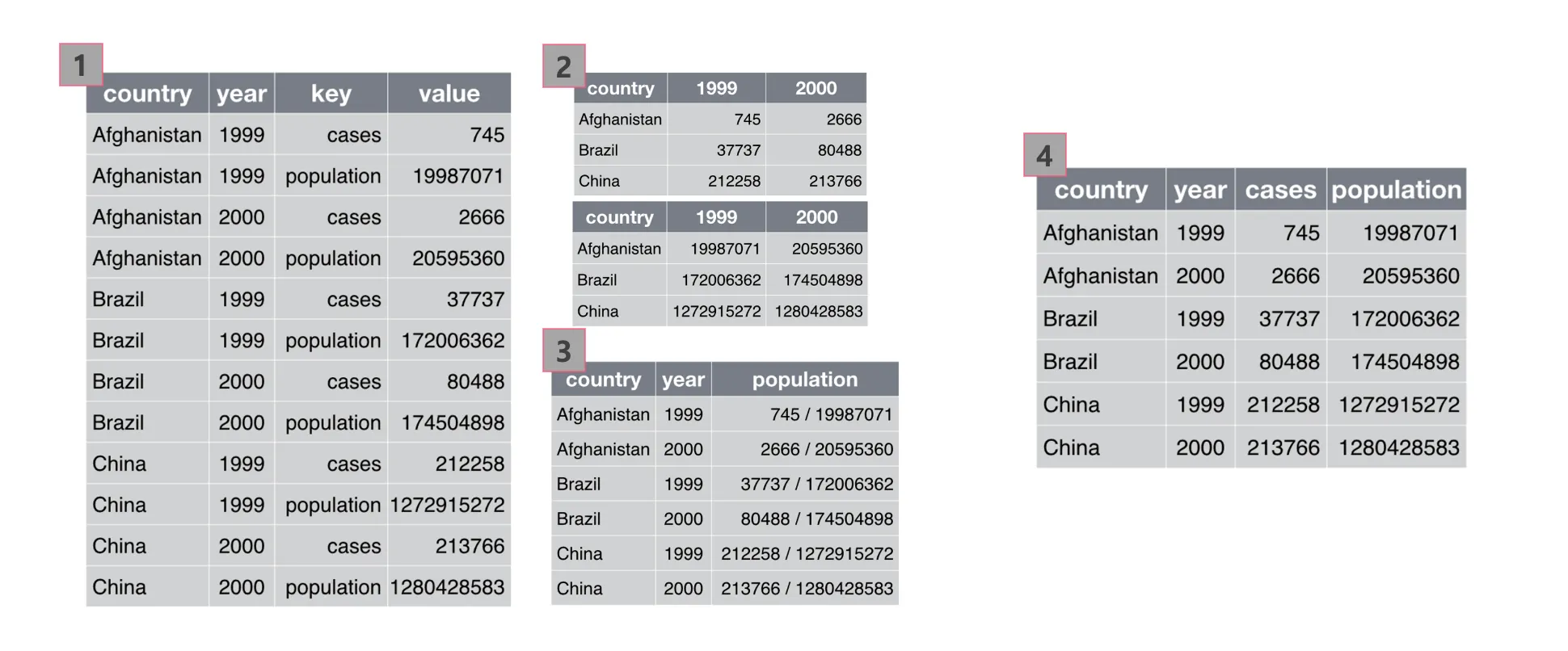
데이터셋에서 각 변수들은 독립적인 의미를 가져야 합니다. 예를 들어, 국가별로 결핵으로 사망한 환자 수와 해당 국가의 전체 인구를 비교한다면, "국가" 변수와 "결핵으로 사망한 환자 수" 변수, "전체 인구" 변수가 각각 독립적으로 구성되어야 합니다.
아래 그림에서는 “4”번째 표가 Tidy dataset의 문법을 잘 따르고 있습니다.
Wide 형태의 데이터셋을 Long 형태로 바꾸기 (melting)
아래 그림의 좌측과 같은 와이드 데이터셋(변수값들이 개별 칼럼으로 넓게 구성된 데이터셋)을 Tidy Dataset 형식을 따르는 롱 데이터셋으로 바꾸어야 하는 경우가 종종 있습니다. 롱 형식의 데이터셋은 개별 변수들을 별도의 열로 구성되기 때문에 데이터 구조가 단순해지고, 시각화 및 분석에 용이한 형태가 됩니다.
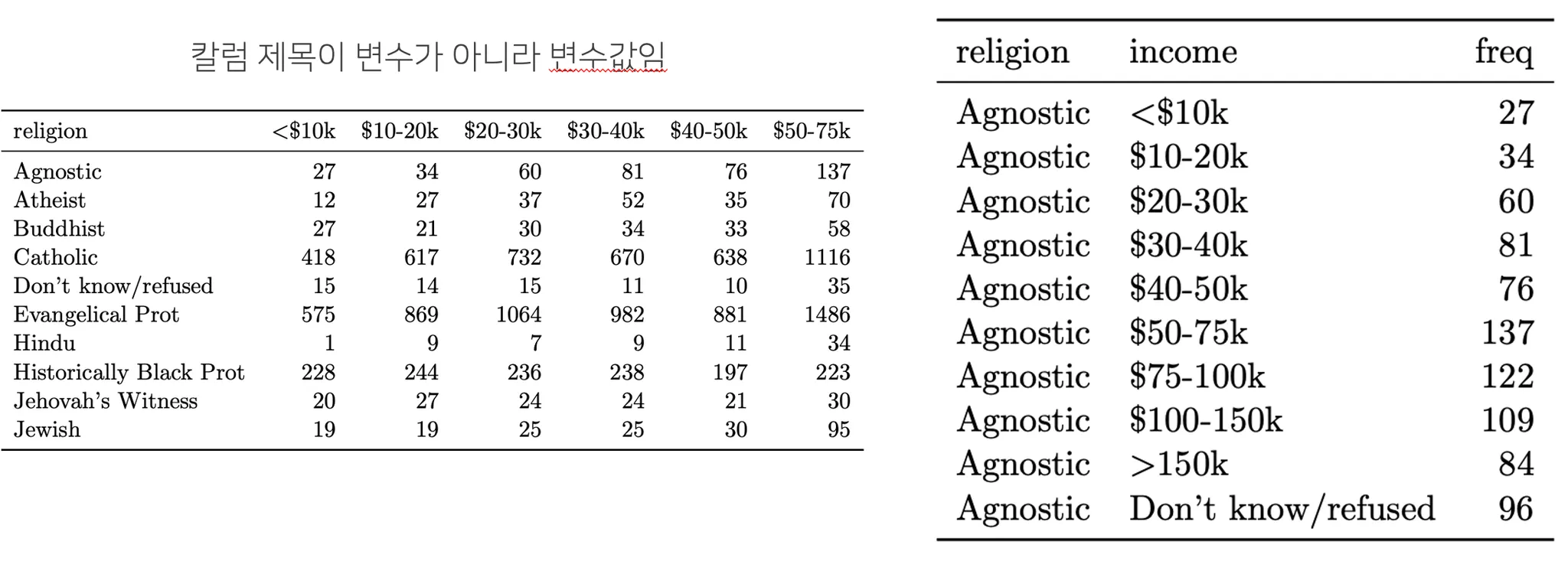
롱 형태로 변환하는 방법
와이드 데이터셋을 롱 데이터셋으로 변환하는 과정을 "멜팅(Melting)"이라고 합니다. 판다스(Pandas) 라이브러리에서는 melt() 함수를 사용하여 데이터프레임을 멜팅할 수 있습니다. 이 함수를 사용하면 지정한 변수들을 식별자 변수(identifier variable)로 유지하고, 나머지 변수들을 값 변수(value variable)로 변환합니다.
예를 들어, 다음과 같은 와이드 데이터셋이 있다고 가정해봅시다.
국가 | 1999년 환자 수 | 1999년 인구 | 2000년 환자 수 | 2000년 인구 |
한국 | 100 | 50000000 | 120 | 51000000 |
미국 | 200 | 300000000 | 230 | 310000000 |
일본 | 80 | 127000000 | 85 | 128000000 |
위와 같은 데이터를 롱 형태로 변환하면 다음과 같이 됩니다.
pythonCopy code
import pandas as pd
# 와이드 데이터셋 생성
data = {
'국가': ['한국', '미국', '일본'],
'1999년 환자 수': [100, 200, 80],
'1999년 인구': [50000000, 300000000, 127000000],
'2000년 환자 수': [120, 230, 85],
'2000년 인구': [51000000, 310000000, 128000000]
}
df_wide = pd.DataFrame(data)
# 멜팅 작업
df_long = pd.melt(df_wide, id_vars=['국가'], var_name='연도', value_name='값')
print(df_long)
Plain Text
복사
국가 | 연도 | 환자 수 | 인구 |
한국 | 1999 | 100 | 50000000 |
한국 | 2000 | 120 | 51000000 |
미국 | 1999 | 200 | 300000000 |
미국 | 2000 | 230 | 310000000 |
일본 | 1999 | 80 | 127000000 |
일본 | 2000 | 85 | 128000000 |
데이터셋으로 알 수 있는 것과 알 수 없는 것을 먼저 파악하는 것이 중요
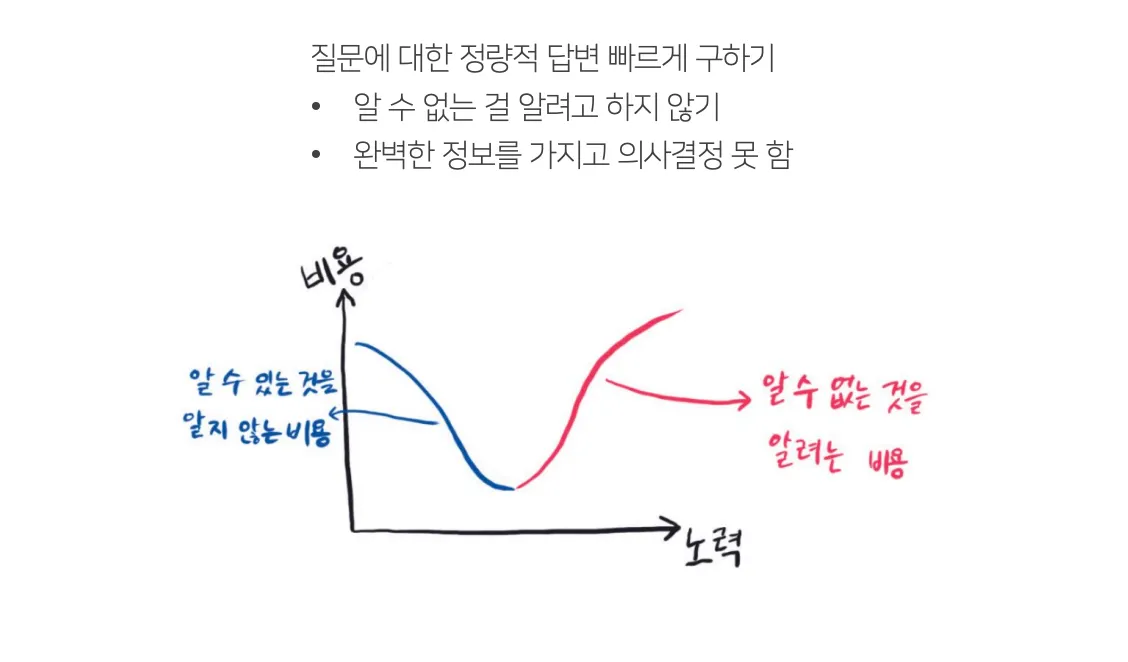
•
Tidy dataset이 준비되었다고 해도 모든 문제를 해결할 수는 없다는 걸 알아야 합니다. 우리가 그 데이터셋으로 말할 수 있는 것은 변수명으로 구성할 수 있는 최선의 문장을 벗어나지 못합니다.
•
예를 들면, ‘구매 시간’과 ‘상품명’, ‘연령대’, ‘취소율’이라는 변수들로 이루어진 홈쇼핑 매출 데이터셋이라면 우리가 완성할 수 있는 문장은 ‘특정 상품은 특정 시간대, 특정 연령대의 취소율이 가장 높았다.’ 입니다. 데이터셋에 담긴 변수가 많을 수록 특정 ‘OOO’와 같은 조건이 많아지며 답할 수 있는 질문도 많아집니다.
•
데이터셋에 담기지 않은 현상의 원인은 추가적인 추론, 해석, 또는 데이터 수집이 필요할 수 있습니다. 이 부분은 도메인 전문가의 판단력의 영역입니다.
•
그렇기 때문에 데이터 분석을 진행할 때에는 데이터셋에서 알 수 있는 것과 알 수 없는 것(한계)를 먼저 인식하는 것이 중요합니다. 이렇게 어떤 질문에 답할 수 있는지를 파악하고 그에 맞는 적절한 분석 방법과 시각화 기법을 선택하면 됩니다. 이를 통해 데이터 분석 또는 보고 과정에서 노력을 최소화하는 지점을 찾을 수 있습니다.
관련 콘텐츠



HEARTCOUNT는 실무자들을 위한 시각화 및 분석 도구입니다.
지금 구글 계정으로 로그인하여 무료로 사용해보세요.