


Intro: HR Analytics란?
HR은 조직 내 사람을 관리하는 분야입니다. 그렇다면 HR Analytics란 무엇일까요?
쉽게 말해, HR 관련 업무를 데이터를 기반으로 접근하는 방식을 말합니다.
오늘날 빅데이터, AI 등 새로운 기술의 발전으로 기업은 인재를 확보하고 활용하는 방식에 큰 변화를 만들어내고 있습니다. HR 분야에서 데이터 및 통계 분석을 통해 좀 더 객관적이고 합리적인 방식으로 인재와 관련된 의사결정에 HR Analytics를 활용하고 있으며 이를 통해 데이터에 기반한 의사결정을 내림으로 보다 올바른 판단을 할 수 있게 되는 것이지요.
이번 글에서는 실습용 HR 데이터셋을 활용하여 HR Analytics의 예시를 보여드리고자 합니다.
Dataset : HR(인사) 데이터셋
HR 데이터라면 떠올리실 수 있는, 가장 흔하게 보실 수 있는 HR 변수들로 구성된 샘플 데이터입니다.
주요 변수를 살펴보면,
•
채용 경로 : 공채, 인턴, 산학, 해외
•
팀구분: 마케팅팀, 기술팀, 생산팀, 사업팀 등
•
퇴직구분: Yes, No
•
근속 기간
•
성과 점수
데이터셋 다운로드 받기
Analysis in HEARTCOUNT
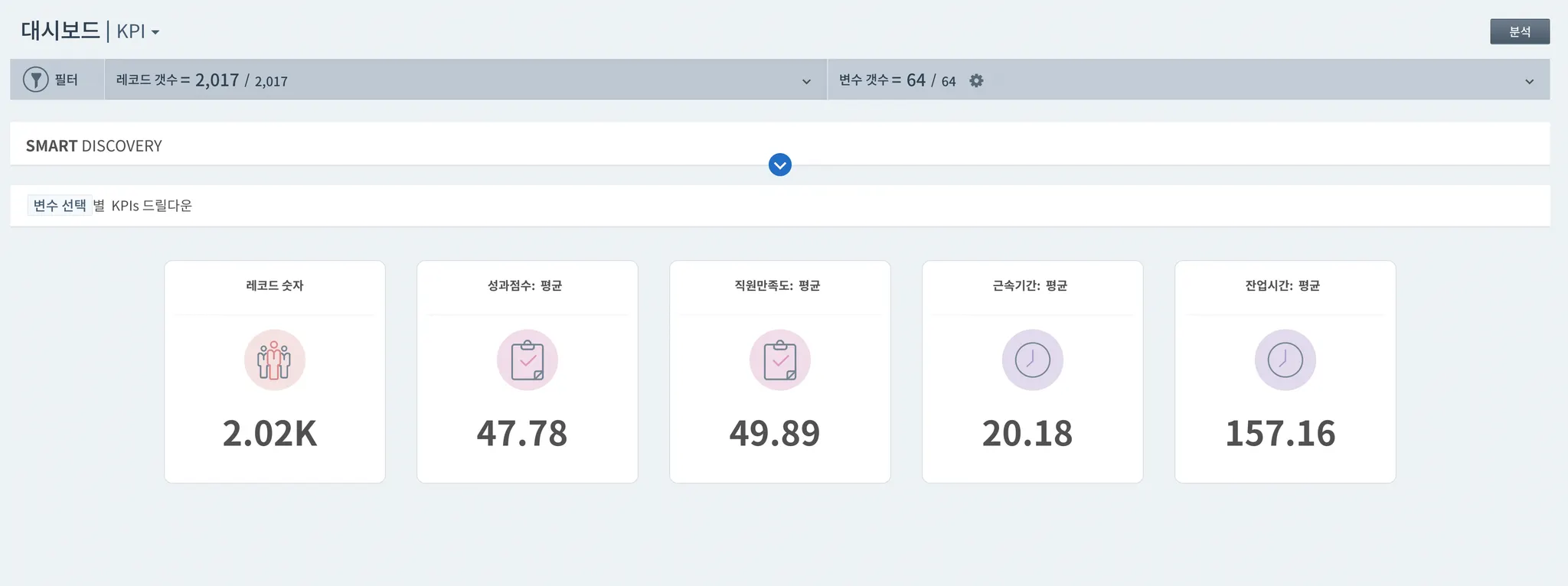
업무에 필요한 변수만 요약된, 대시보드 구성하기 Premium 기능
대시보드에서는 사용자가 등록한 KPI의 평균 등 요약 정보를 확인할 수 있습니다.
레시피
KPI 관리> 대시보드 > 설정한 KPI의 평균, 총합, 비율 등 요약 결과를 확인할 수 있습니다.
(*. K는 1,000을 뜻합니다.)
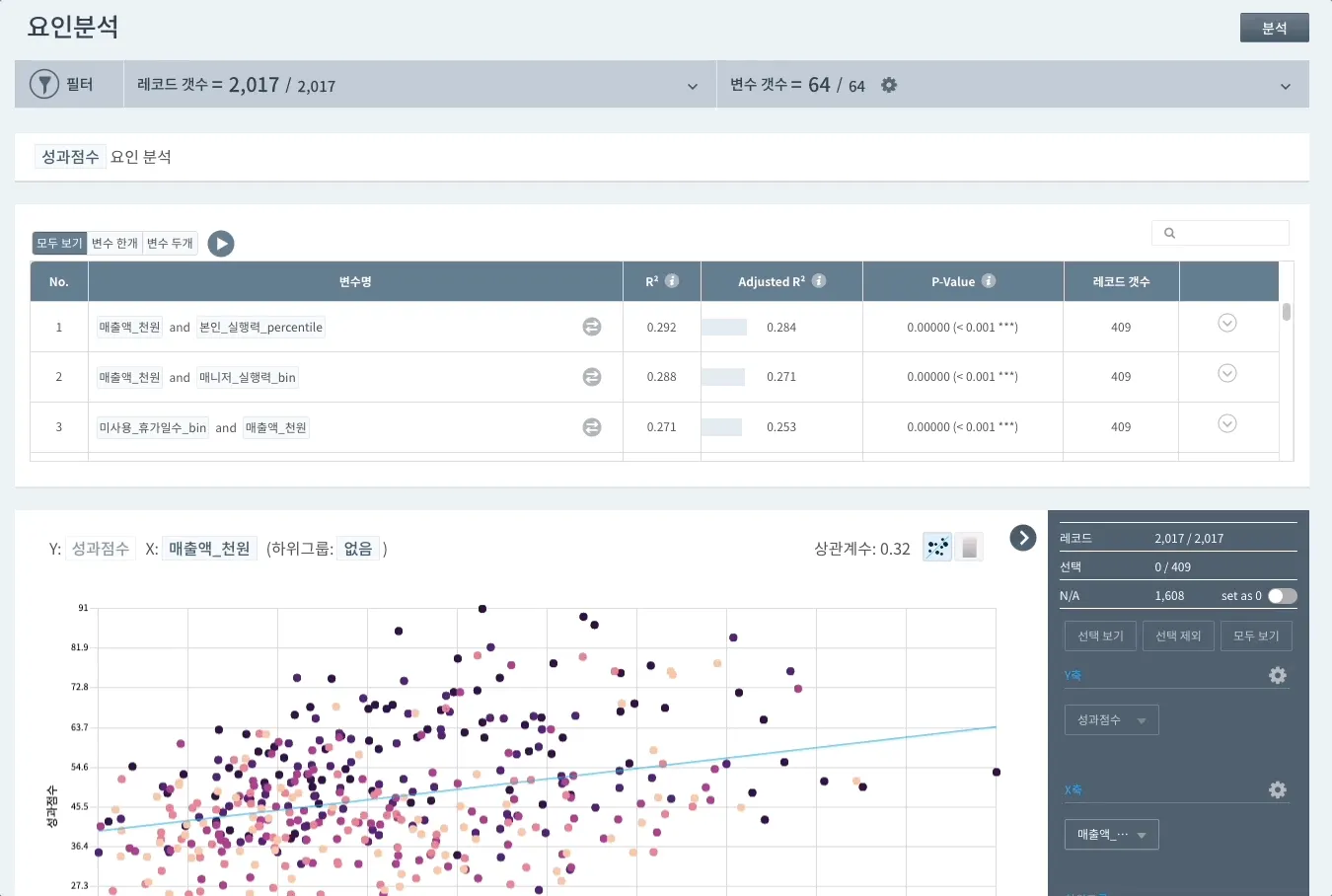
직원만족도에 어떤 요인이 가장 컸을까? Premium 기능
레시피
•
요인분석에서 KPI(직원만족도)를 선택 후 [분석] 버튼을 클릭합니다.
•
가 높은 순서대로 어떤 독립변수가 종속변수(KPI, 직원만족도)에 영향을 많이 미쳤는지 확인할 수 있습니다.
•
요인이 되는 변수 1개 혹은 변수 2개의 조합으로 회귀 분석 결과를 확인할 수 있습니다.
R^2 : 독립 변수가 종속 변수의 변화를 얼마나 잘 설명하는지 나타내는 수치.
1에 가까울수록 설명력이 높음.
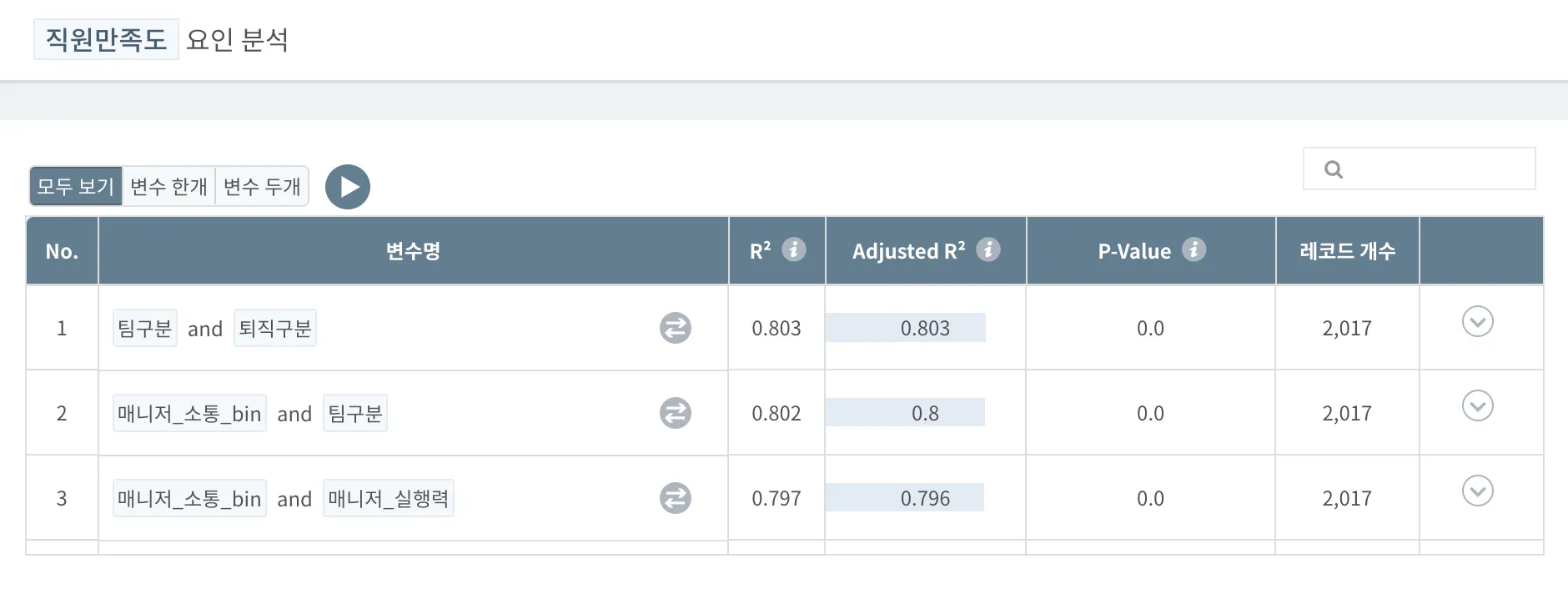
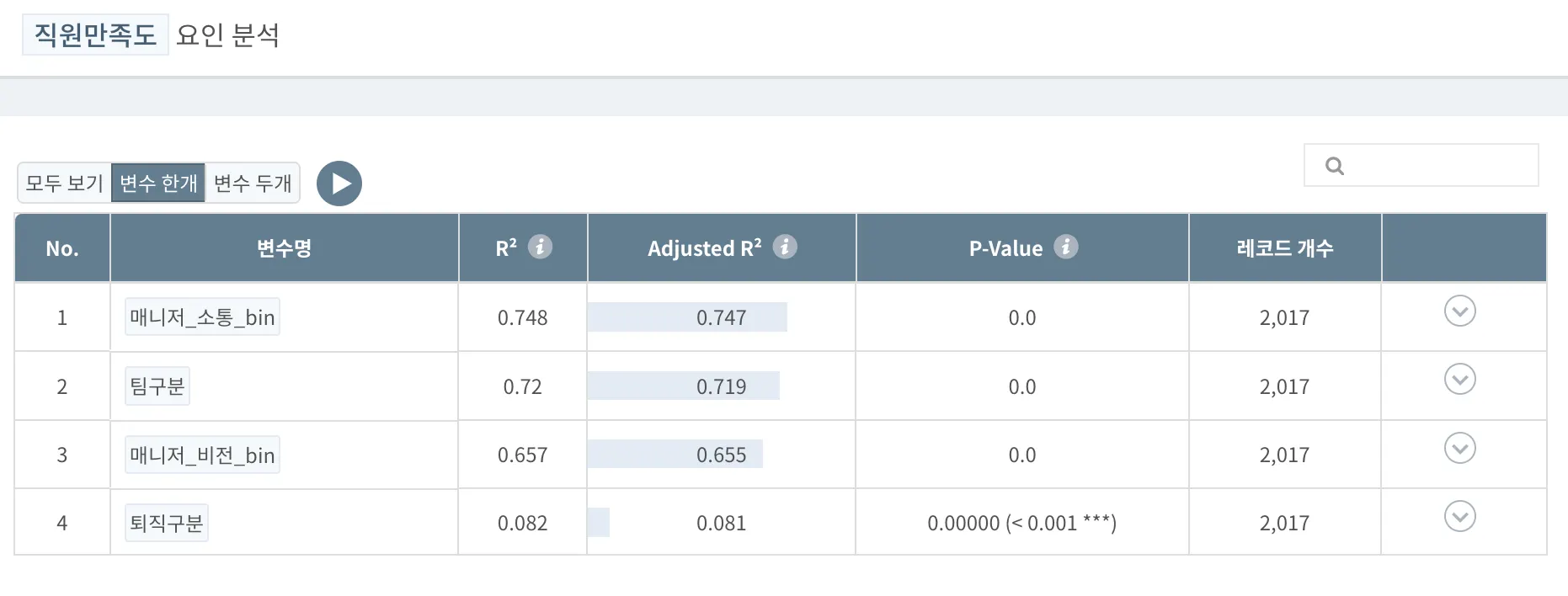
분석 결과 해석
•
[직원만족도]를 가장 잘 설명하는 것은 이 0.803으로 가장 높은 [팀구분]과 [퇴직구분]변수이며, [직원만족도]의 차이(변화량) 중 80%를 [팀구분]과 [퇴직구분]으로 설명할 수 있습니다.
→ “우리 회사 직원들 만족도에 가장 영향을 많이 끼친 것은 ‘어느 팀에 속해 있냐’와 ‘퇴직 여부’이구나!”
•
요인이 되는 독립변수가 한 개만 있는 단순회귀분석의 경우, [매니저_소통_bin]이 가장 설명력이 높다는 것을 알 수 있습니다. (74%)
•
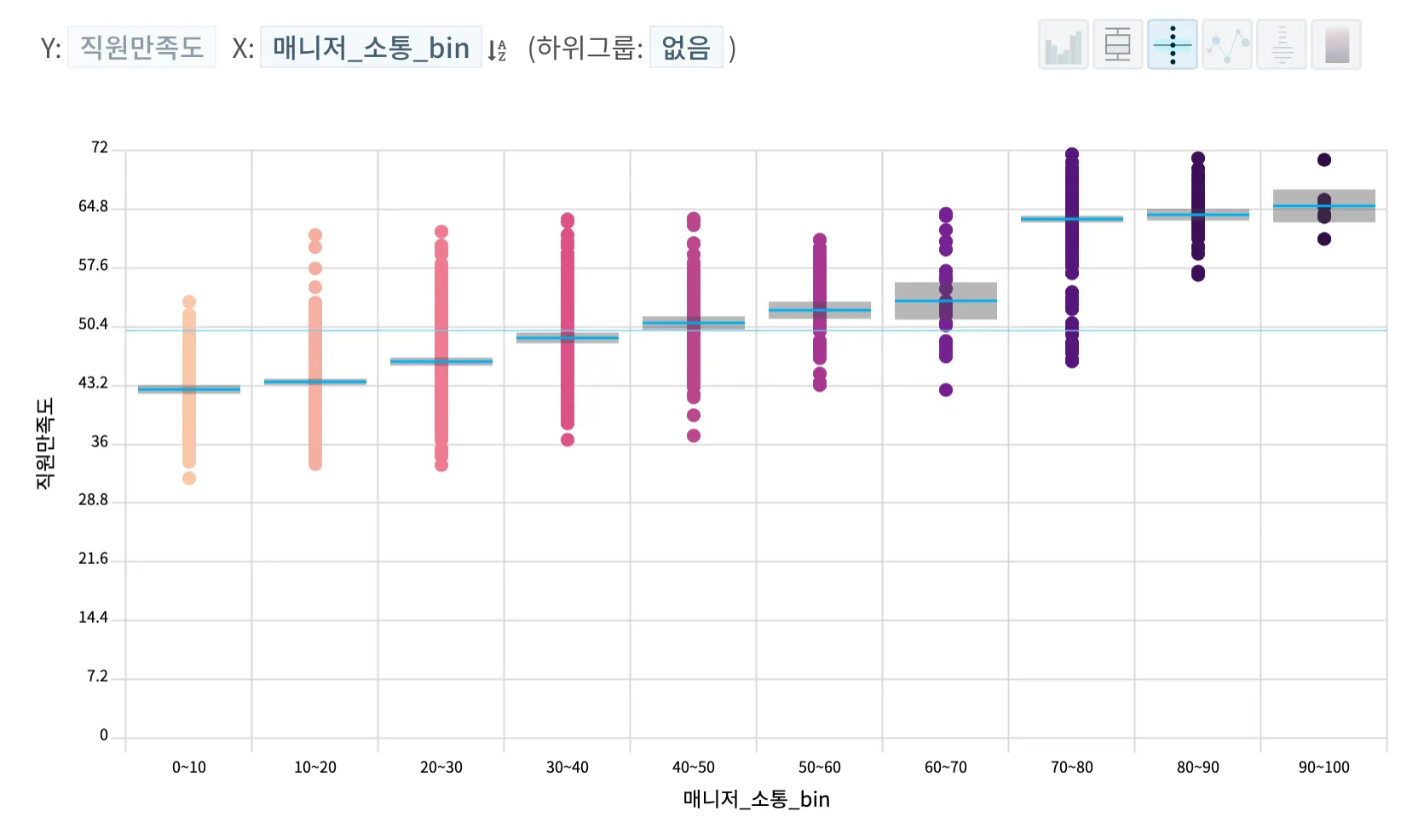
더 자세히 알아보고 싶은 분석 결과를 클릭하면, 아래에 해당 시각화 화면이 나타납니다. 참고하여 해당 변수가 구체적으로 KPI에 어떤 변화를 주었는지, 패턴을 발견할 수 있습니다. 아래 스크린샷을 보면, 매니저의 소통력이 높은 구간일수록 직원만족도가 상승하는 것을 알 수 있습니다.
성과점수를 최적화시킬 수 있는 규칙 알아보기 Premium 기능
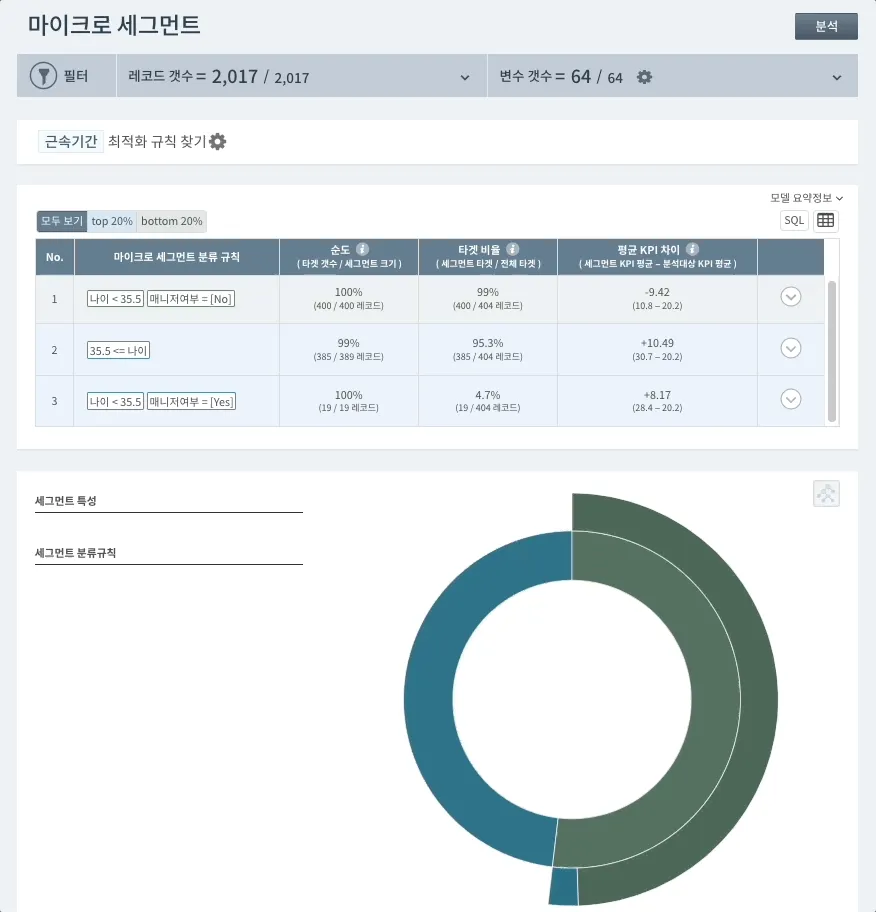
직원들의 성과점수를 최적화시키고 싶다면, 양극단에 있는 성과점수 상위 모범 그룹과 하위 그룹의 통계적 특징을 비교하여 패턴을 발견하는 것을 추천드립니다. 마이크로 세그먼트에서 자동으로 제시되는 비교하고자 하는 두 집단이 구분되는 규칙들을 신뢰도(순도)가 높은 순서대로 참고해보세요.
레시피
•
•
자동으로 성과점수 top 20% 그룹과 bottom 20% 그룹이 생성됩니다. (*. 사용자가 직접 타겟 그룹을 세부 설정하는 것도 가능합니다.)
분석 결과 해석
•
성과점수 상위 20%로 분류되는 규칙 미사용_휴가일수 < 12.5, 직원만족도 ≥ 44.6, 본인_인내력 ≥ 71.5, 직군 = [연구개발, 마케팅영업]
미사용_휴가일수 < 12.5, 직원만족도 ≥ 44.6, 본인_인내력 ≥ 71.5, 직군 = [연구개발, 마케팅영업] •
성과점수 하위 20%로 분류되는 규칙 미사용_휴가일수 ≥ 12.5, 사업장위치 = [일본, 중국, 미국, 서울(본사), 베트남], 대학구분 = [국립, 해외, 수도권, top5, top8]
미사용_휴가일수 ≥ 12.5, 사업장위치 = [일본, 중국, 미국, 서울(본사), 베트남], 대학구분 = [국립, 해외, 수도권, top5, top8]•
시각화 그래프를 통해, 상위 20%(파란색)와 하위 20%(초록색) 그룹의 규칙을 계층적으로 확인할 수 있습니다.
•
의사결정나무란? 스무고개처럼, 조건을 만족하는 집단끼리 구획하는 기계학습 알고리즘
성과점수 상위 그룹과 하위 그룹의 주요 특성은 무엇일까? Premium 기능
위에서 비교한 두 집단을 더 가시성있게 비교해보겠습니다. 비교분석 기능을 통해, 두 집단이 어느 변수에서 유독 다른지, 각 집단의 주요 특성은 무엇인지 한 눈에 확인할 수 있습니다.
레시피
•
비교분석에서 통계적 특성을 비교할 임의의 두 그룹을(그룹 A와 그룹 B) 설정합니다.
•
•
우측 상단의 비교 버튼 클릭하면, 분석 조건에서 설정된 두 그룹 간의 가장 큰 통계적 특성 차이를 보이는 변수와 해당 변수와 관련된 각 그룹의 주요 특성이 내림차순으로 표시됩니다.
분석 결과 해석
•
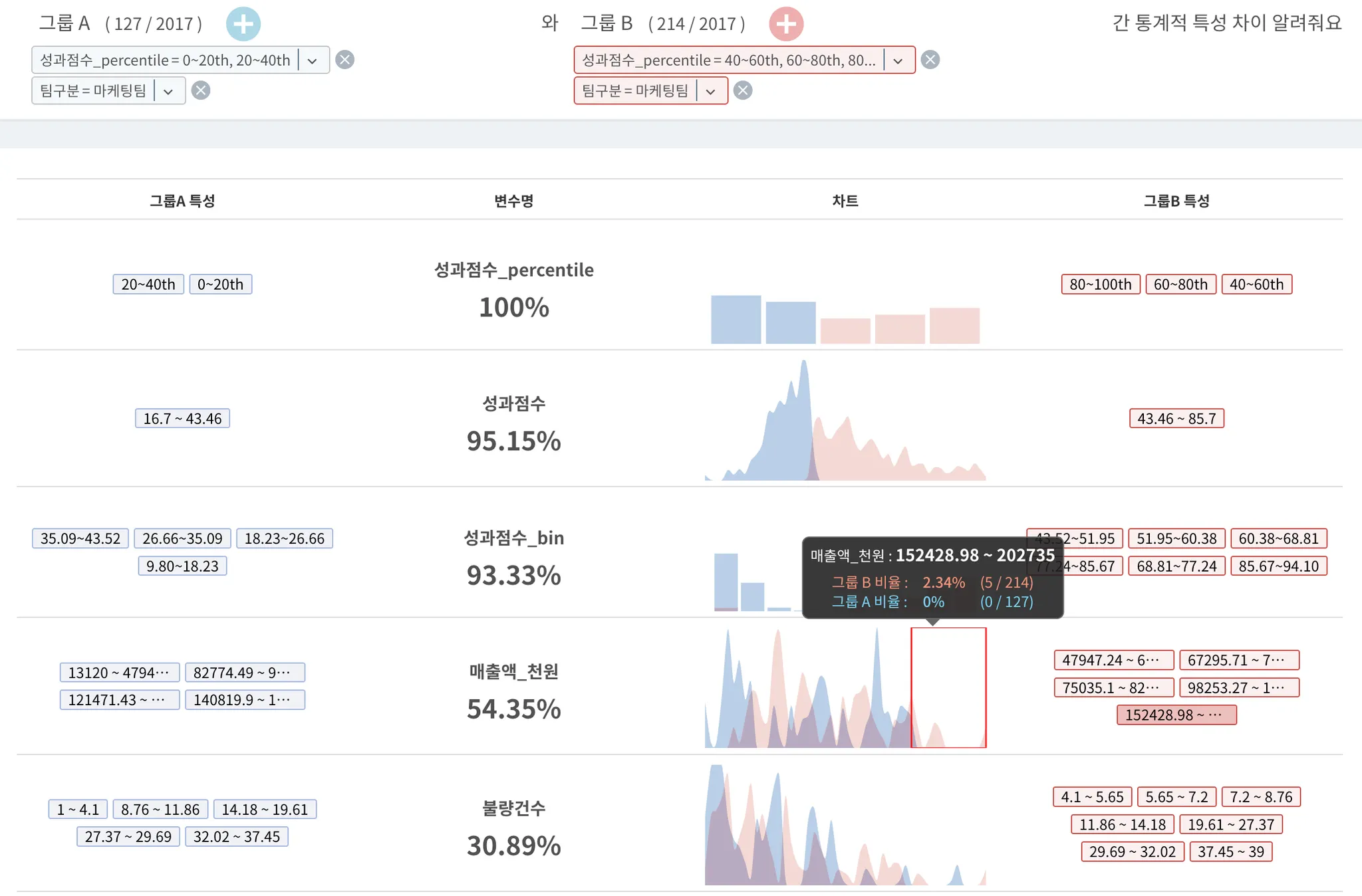
그룹 A는 파란색, 그룹 B는 핑크색으로 표현된 그래프를 통해, 두 그룹이 어느 구간에서 겹치는지 쉽게 확인할 수 있네요.
•
퍼센테이지로 나타나는 수치(두 색상의 그래프가 겹치지 않는 범위)를 통해, 두 그룹이 해당 변수에서 얼마나 다른지 알 수 있습니다.
•
양 쪽의 특성 칼럼을 통해 그룹 A와 B는 해당 변수에서 각각 어떤 특성을 더 지니고 있는지 확인할 수 있습니다.
•
아래 예시를 보면, 마케팅팀에서 성과점수 하위 그룹과 상위 그룹을 비교 분석했을 때 [매출액] 전체에서 54.35% 서로 겹치지 않았으며 실제로 매출이 낮은(좌측) 구간에서는 성과 점수 하위 그룹인 파란색 그래프가 많이 차지하는 것을 확인할 수 있습니다.
직원만족도와 성과점수는 어떤 상관관계가 있을까? 그래프로 구현해보기
레시피
•
스마트 플롯에서 X축에 성과점수, Y축에는 직원만족도를 설정합니다.
•
x축과 y축 모두 수치형 변수이기 때문에 추세선과 히트맵을 통해 개별 레코드(점)들의 분포와 상관관계를 확인할 수 있습니다.
분석 결과 해석
•
상관계수를 통해, 두 변수가 서로에게 어떤 영향을 주는지(선형적 관계에 가까운지) 알 수 있습니다. 상관계수(r)는 절대값이 1에 가까울 수록 두 변수간의 상관관계가 높고 비례하여 증가 혹은 감소하는 선형적 관계를 뜻합니다.
•
직원만족도와 성과점수는 상관계수가 0.21로 보통의 양의 상관관계를 보이고 있네요.
•
히트맵을 통해, 레코드의 분포 상태를 확인할 수 있습니다. (레코드 개수가 많을 수록 색이 진해짐)
