
How? KPI를 최적화하는 패턴 찾기
분류 규칙 기능을 통해 임의의 KPI를 최적화할 수 있는 실행 가능한 규칙을 발견할 수 있습니다.
여기서 말하는 KPI는, 분석의 목표가 되는 변수를 뜻합니다. 즉, 꼭 KPI로 등록되어 있지 않아도 모든 변수를 분류 규칙의 목표 변수로 설정할 수 있습니다. 1. 분류 규칙이란?
사람들은 항상 업무 최적화를 위해 고민합니다.
만약 어느 기업의 마케팅 담당자가 마케팅 캠페인을 전개할 때, 이 캠페인에 적극적으로 반응할 그룹/반응하지 않을 그룹을 구분하는 규칙을 찾아냈다고 생각해볼까요? 그렇다면, 그 기업은 앞으로 반응할 가능성이 높은 집단만 골라 효율적으로 타겟팅을 할 수 있게 됩니다.
이렇게 내가 원하는 목표를 최적화할 수 있는 방법을 자동으로 알아낼 수 있다면 어떨까요?
HEARTCOUNT는 KPI를 최적화할 수 있는 규칙을 자동으로 발견하여, 어떤 조건으로 실행하는 것이 가장 적합한지 추천해주는 분류 규칙 기능을 제공하고 있습니다. 분류 규칙 기능은 의사결정나무(decision tree) 즉, 서로 다른 두 집단을 분류하는(classify) 규칙을 만들어내는 대표적인 기계학습 알고리즘을 사용합니다.
의사결정나무란?
2. 분류 규칙 활용하기
아래 예시는 할인마트의 이익을 최적화하는 규칙을 자동으로 찾아내는 과정을 보여주는 예시입니다. 이와 같이 특정 KPI의 최적화 규칙을 분류 규칙 기능을 활용하여 찾는 방법을 함께 알아보겠습니다.
(1) 최적화 규칙 찾기
1.
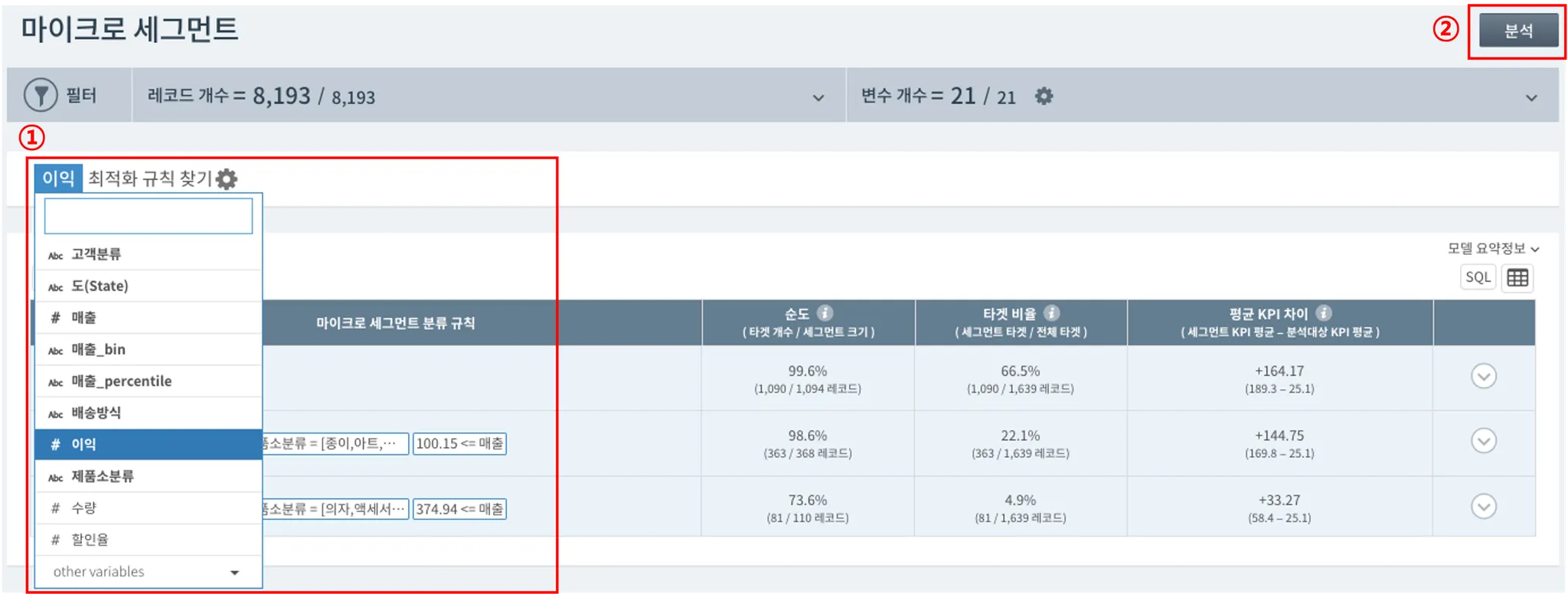
먼저 최적화하고자 하는 변수를 선택해주세요. (예시에서는 [이익]을 변수로 설정) 그리고 나서 우측 상단의 분석 버튼을 클릭하면 자동으로 테이블에 top 20%와 bottom 20%을 분류하는 규칙이 제시됩니다.
 분류 규칙 기능은, 목표 변수가 수치형 변수일 때는 자동으로 상위/하위 그룹을 나누어 ‘최적화 규칙’을, 범주형 변수일 때는 두 그룹의 ‘분류 규칙’을 찾아드립니다. 범주형 변수는 아래와 같이 설정 가능합니다.
분류 규칙 기능은, 목표 변수가 수치형 변수일 때는 자동으로 상위/하위 그룹을 나누어 ‘최적화 규칙’을, 범주형 변수일 때는 두 그룹의 ‘분류 규칙’을 찾아드립니다. 범주형 변수는 아래와 같이 설정 가능합니다.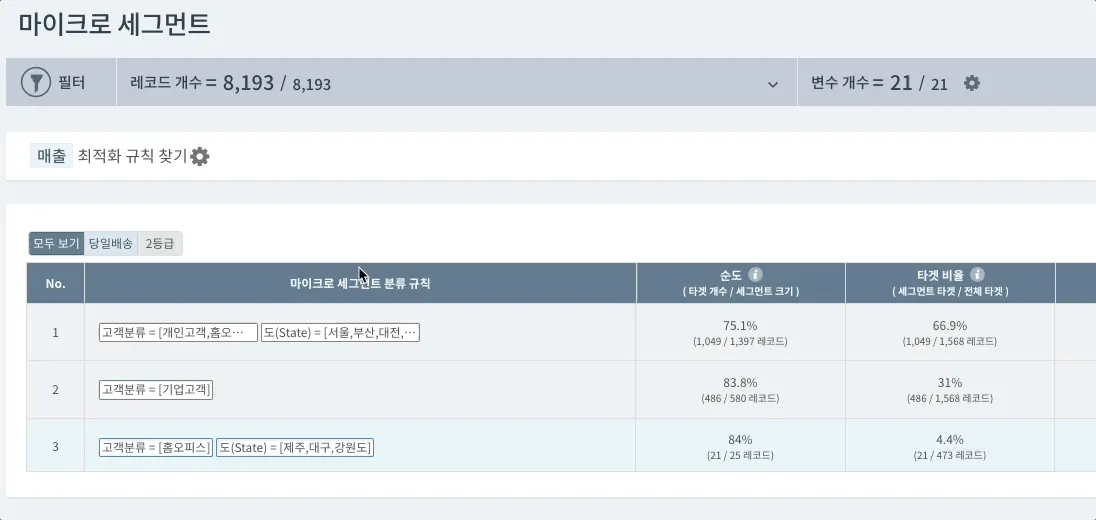
2.
(선택 사항) 분류 규칙의 기본 원리는 두 가지 타겟 집단을 구분하여 두 집단이 분류되는 '규칙'을 찾아내는 것입니다. 사용자는 디폴트로 제공되는 상위 20% / 하위 20% 집단 외에도 다양한 타겟 집단을 직접 설정할 수 있습니다. 톱니바퀴를 클릭하여 분류 규칙을 만들고자 하는 두 집단의 range를 직접 마우스로 조정하거나 수치를 입력할 수도 있습니다.
를 클릭하여 분류 규칙을 만들고자 하는 두 집단의 range를 직접 마우스로 조정하거나 수치를 입력할 수도 있습니다. 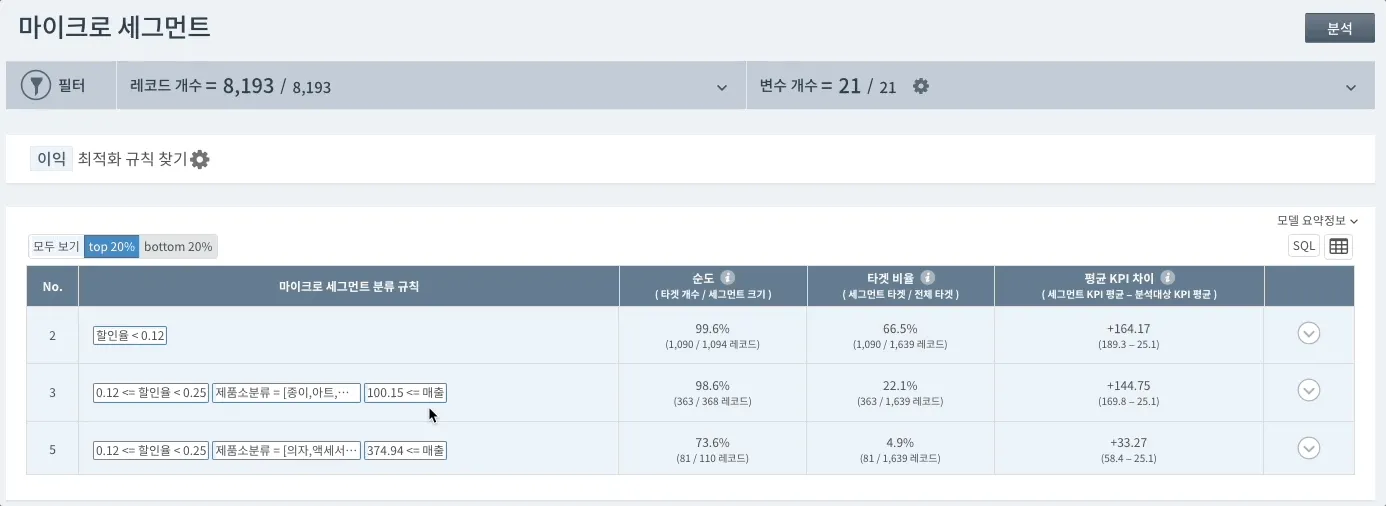
3.
테이블의 각 항목을 자세히 살펴볼까요? 참고로, 테이블의 규칙은 타겟 비율이 높은 순서대로 내림차순 정렬되어 있습니다.
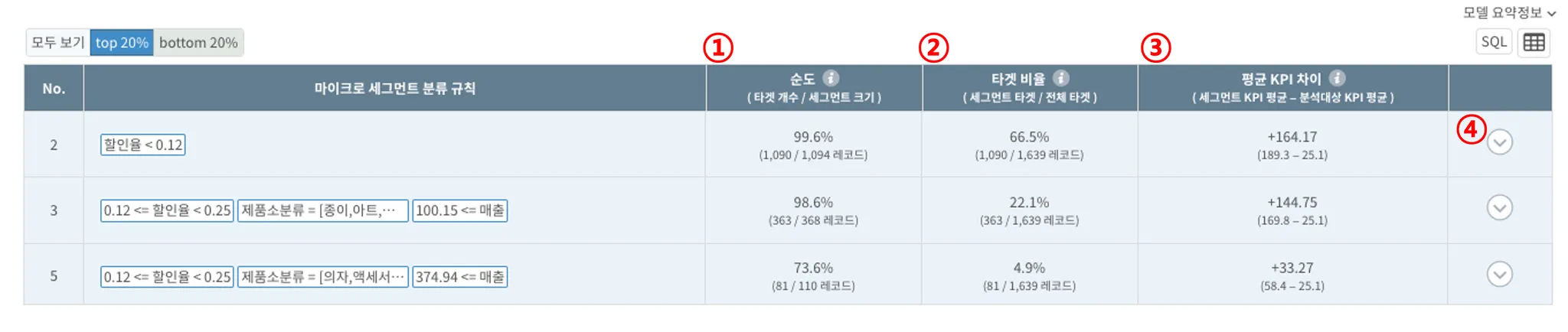
① 순도 : 분류 규칙이 해당되는 집단에서 타겟 집단이 차지하는 비율, 해당 분류 규칙이 얼마나 정확한 지 알 수 있음
(ex. '할인율이 12% 미만인 전체 집단'에서 '할인율 12% 미만 + 이익 상위 20%인 집단'이 차지하는 비율)
② 타겟 비율 : 타겟 집단에서 개별 분류 규칙이 해당되는 집단이 차지하는 비율
(ex. '이익이 상위 20%인 전체 집단'에서 '할인율이 12% 미만인 집단'이 차지하는 비율)
③ 평균 KPI 차이 : 개별 분류 규칙이 해당되는 세그먼트와 타겟으로 설정한 변수의 전체 평균의 차이
④ ▽ (스마트 서치) : 각 행의 우측에 위치한 ▽를 클릭하면 각 규칙에 해당하는 개별 레코드(데이터)를 더 자세히 탐험할 수 있는 '스마트서치' 메뉴로 이동합니다
4.
예측 모델에 대한 요약 정보도 확인해보세요.
아래 그림의 빨간 Box로 표시해둔 부분의 화살표 ∨ 을 클릭해주시면,
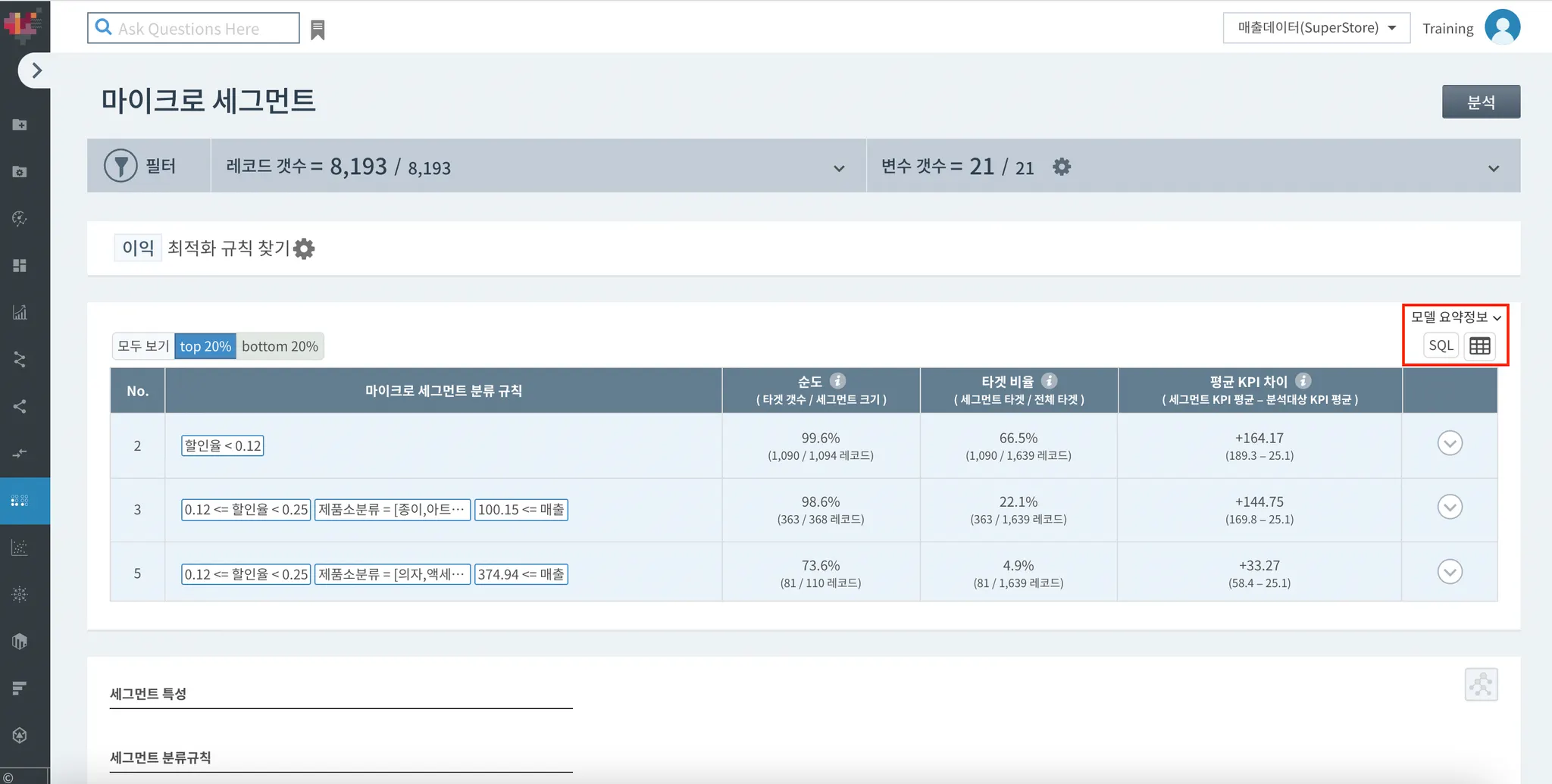
디폴트로 제공되는 두 타겟 집단 혹은 사용자가 직접 설정한 타겟 집단에 대한 요약 정보를 확인할 수 있습니다.
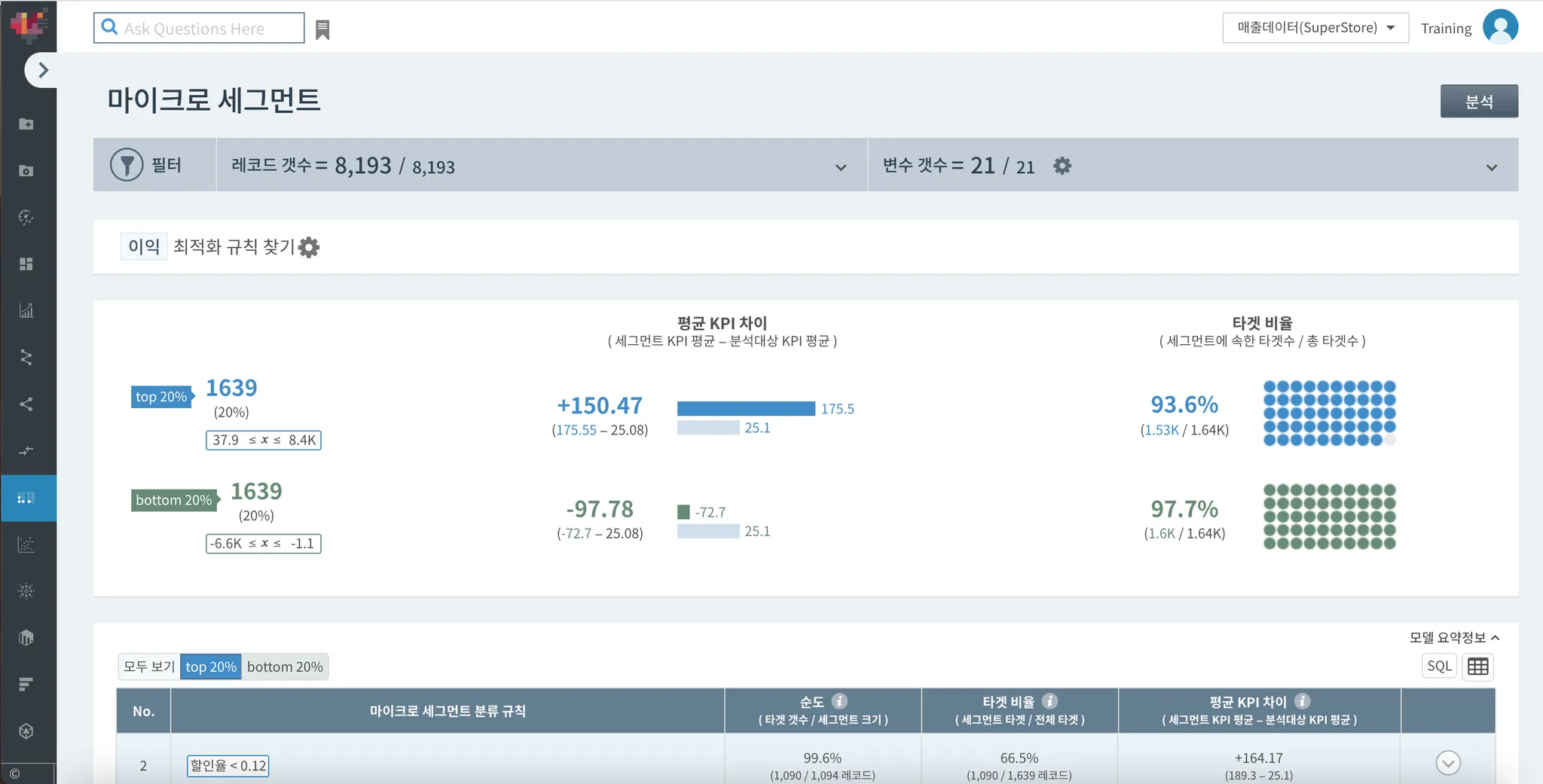 요약 정보의 타겟 비율은 위에서 설명했던 각 세그먼트의 타겟 비율과는 다릅니다.
분모인 전체 타겟은 동일하지만, 분자인 세그먼트 타겟수가 다르기 때문인데요.요약 정보에서는 도출된 모든 규칙 세그먼트를 합하여 총 타겟수에서 나눕니다. 이익 상위 20% 집단의 경우 총 1.64k의 크기이며 도출된 모든 세그먼트의 크기는 1.53k네요. 즉, 이익이 상위 20%인 집단 중 93.6%가 괄목할만한 규칙을 가지고 있다는 뜻으로 해석 가능합니다.
요약 정보의 타겟 비율은 위에서 설명했던 각 세그먼트의 타겟 비율과는 다릅니다.
분모인 전체 타겟은 동일하지만, 분자인 세그먼트 타겟수가 다르기 때문인데요.요약 정보에서는 도출된 모든 규칙 세그먼트를 합하여 총 타겟수에서 나눕니다. 이익 상위 20% 집단의 경우 총 1.64k의 크기이며 도출된 모든 세그먼트의 크기는 1.53k네요. 즉, 이익이 상위 20%인 집단 중 93.6%가 괄목할만한 규칙을 가지고 있다는 뜻으로 해석 가능합니다.(2) 시각화 그래프
사용자가 테이블에 제시된 규칙을 좀 더 쉽게 이해할 수 있도록, 아래의 화면처럼 시각화된 그래프를 통해 최적화 규칙에 대해 세부적으로 파악할 수 있습니다.
아래 그림은 '이익 최적화'를 기준으로 도출된 규칙들 중 테이블 맨 상단에 있는 규칙인 할인율 < 0.12 조건에 해당하는 시각화 그래프/세그먼트 특성을 나타내는 그림입니다.
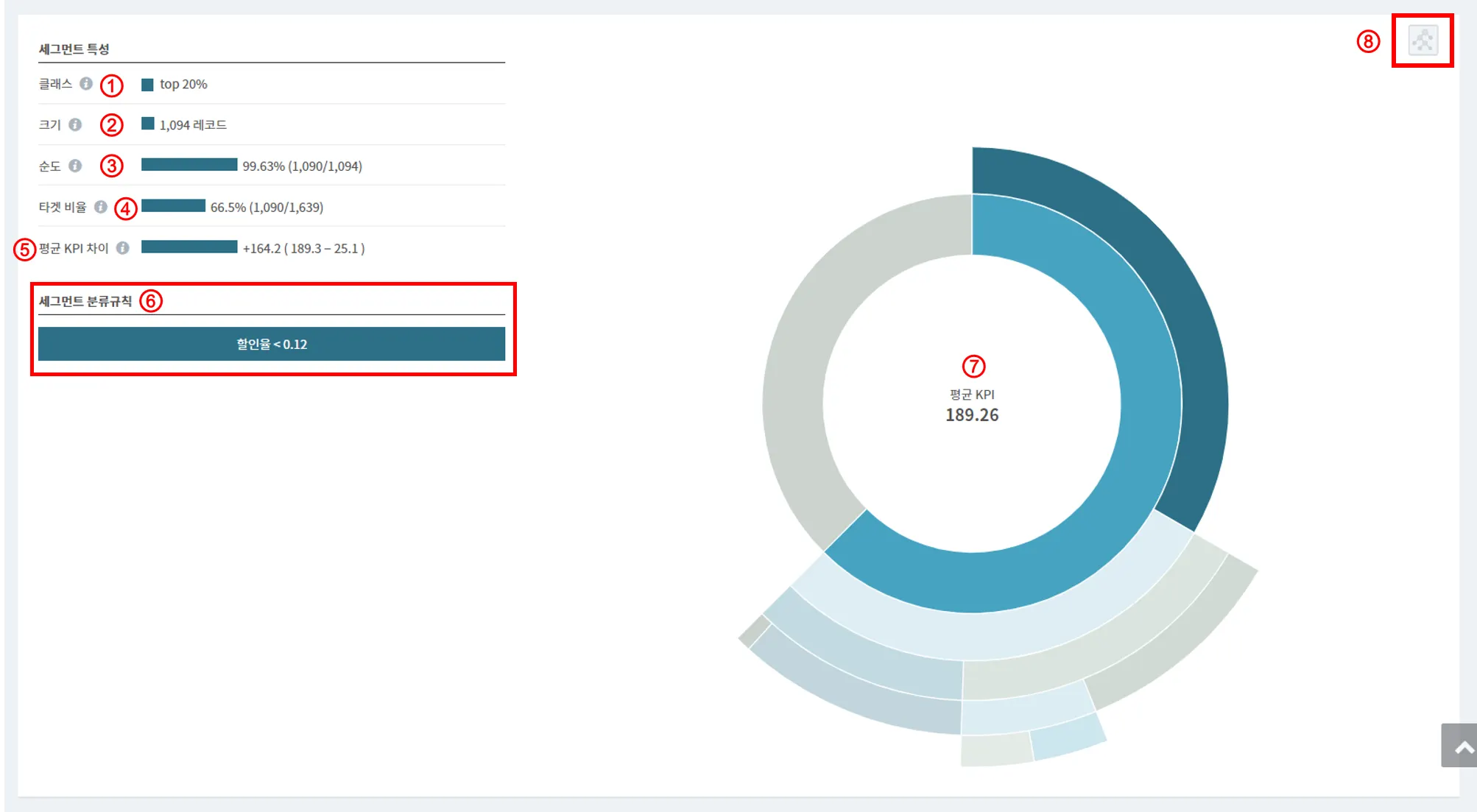
① 클래스 : 해당 조건인 할인율 < 0.12로 분류되는 레코드의 다수가 이익 Top 20%에 해당한다는 의미입니다.
② 크기 : 해당 조건을 만족하는 레코드 개수(1,094 레코드)
③ 순도 : 해당 조건을 만족하는 세그먼트 크기 1,094개 중 1,090개(99.63%)가 판매 이익 상위 20%에 해당한다는 의미입니다. 순도가 높으면 높을수록 분석 결과에 대한 신뢰도도 높아집니다. 쉽게 말하면, 해당 분류 규칙이 얼마나 정확하게 예측하는지 알려주는 척도입니다.
④ 타겟 비율 : 판매 이익 상위 20%에 속하는 총 레코드 숫자(1,639개) 중 1,090개(66.5%)가 해당 세그먼트에 속한다는 의미입니다. (recall/재현율이라고도 함)
⑤ 평균 KPI 차이 : 해당 세그먼트에 속한 레코드의 평균 KPI와 분석대상 전체 평균 KPI의 차이(전체 이익 평균-25.1, 해당 조건의 레코드 평균 이익-189.3, 평균 KPI 차이 = +164.2)
⑥ 세그먼트 분류규칙 : 위 그림 상단의 첫 번째 테이블에 해당하는 분류 규칙을 상세하게 표시한 것입니다.
⑦ 시각화 그래프 : 도출된 이익 최적화 조건을 그래프로 표현한 것입니다. 파란색으로 선명하게 표시된 영역이 해당 분류 규칙의 영역입니다.
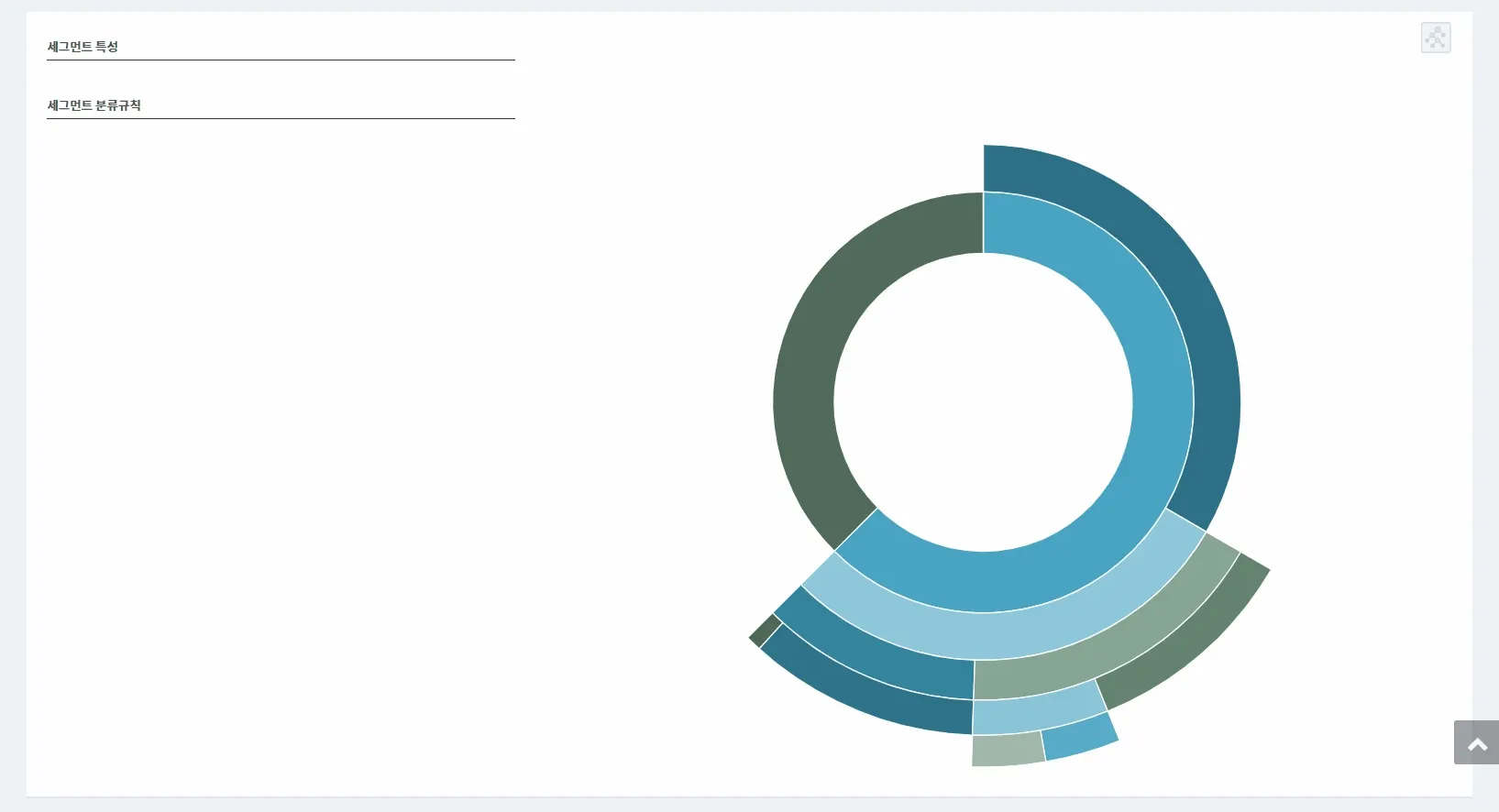
⑧ Decision Tree : 아이콘을 클릭하면 아래 그림과 같이 분류 규칙이 트리 형태로 표현됩니다.
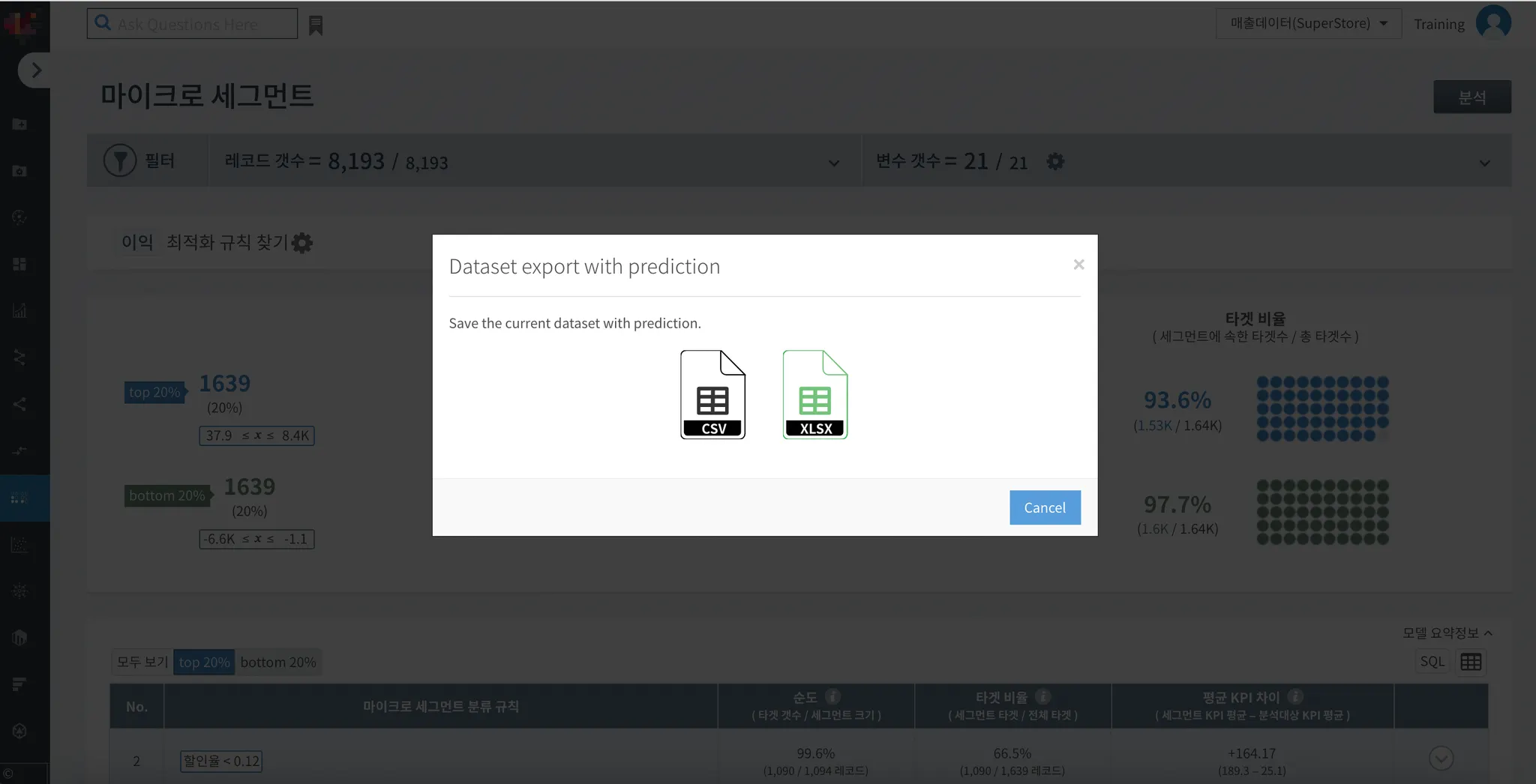
(3) File로 내보내기

•
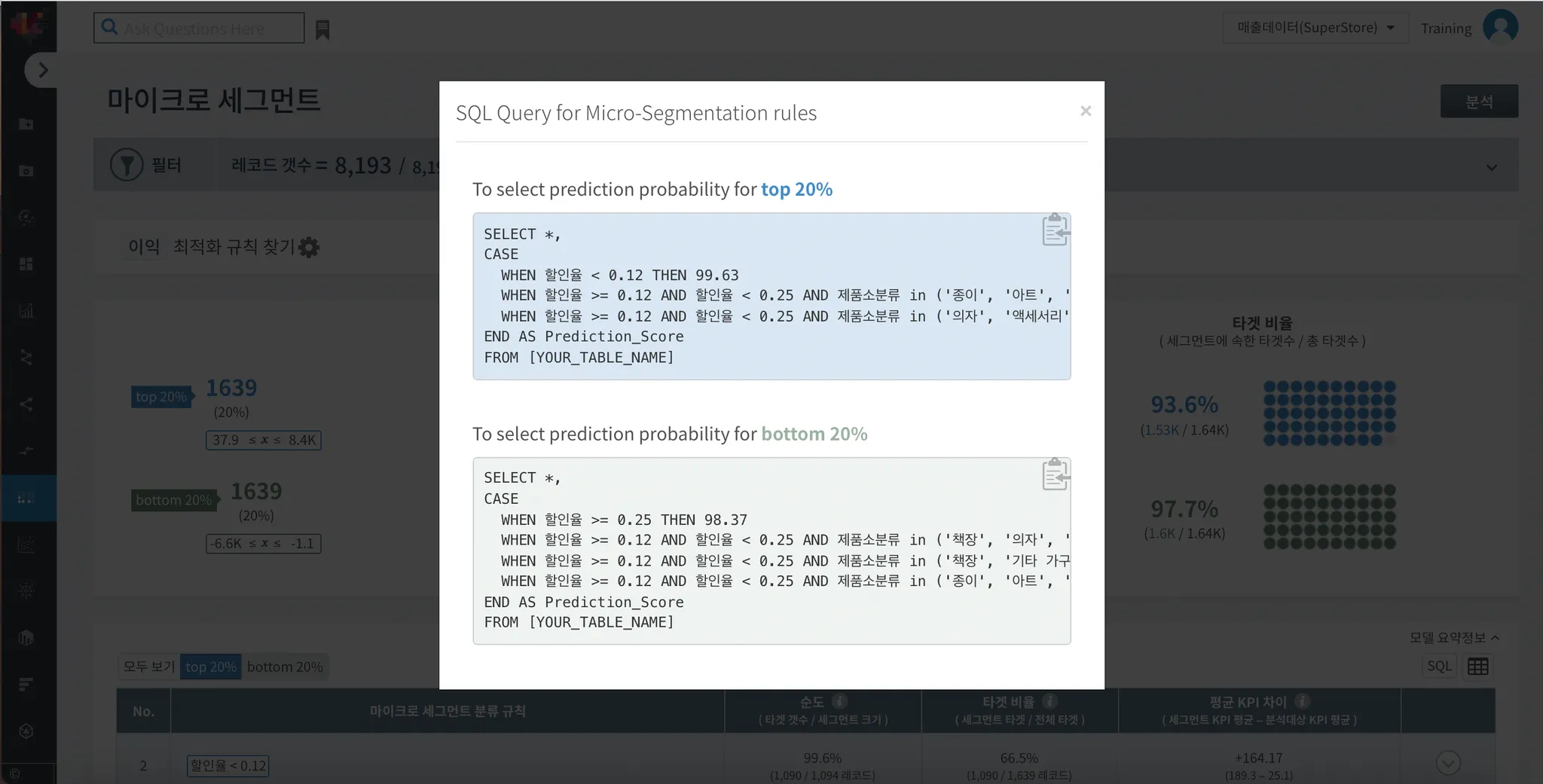
SQL 을 클릭하면 예측 모델을 아래와 같은 쿼리로 확인할 수 있습니다.
•
테이블 그림을 클릭하면 예측 모델을 csv 혹은 xlsx 파일로 저장할 수 있습니다.