

데이터 히어로의 Original 시리즈, 데이터 시각화(EDA) 기초 블로그 더 보기
Bar Chart : 데이터로 양적 크기와 차이에 대해 이야기해야 할 때
시계열 분석 : 시간의 흐름에 따른 지표의 변화를 이해하고자 할 때
분포 : 개별 레코드 수준의 시각화를 통해 불확실성을 말해야 할 때

데이터 시각화란?
데이터 시각화는 - 담백하게 정의하자면 - 숫자를 점, 선, 면(도형)을 활용해서 크기, 위치, 색상으로 표현하는 일이다. 데이터 시각화가 의미있는 근본적인 이유는 날것의 데이터/숫자보다 시각적 신호가 이해하고 기억하고 관련된 의사결정을 내리기 쉽기 때문이다.
사람의 뇌가 처리하는 시각 정보가 9Mb/sec 정도라고 하는데 사람의 두뇌는 시각적 정보를 잘 해석하도록 진화해 왔다. 한편, 엑셀을 볼 때는 cortisol이라는 스트레스 호르몬이 엄청 분비된다고 한다.

데이터 시각화(EDA) 시리즈를 시작하며 : 시각화 공부를 시작하기 전에 알아둘 것들
EDA 시각화 기초 블로그

데이터 시각화란?
데이터 시각화는 데이터의 양적(45.6년, 58.3년) 혹은 질적(북미, 아프리카 등) 값들을 시각적 요소로 전환하는 일이다. 바차트, 산점도, 파이 차트 등 제각각의 모양을 갖는 시각화 기법들도 결국엔 하나의 보편적인 문법에 기반하고 있고, 그 문법은 데이터가 담고 있는 값을 위치, 크기, 모양, 색상으로 대표되는 시각적 요소를 사용하여 표현하는 것이다.
양적 크기를 비교할 때의 시각화 방법

Bar Chart : 데이터로 양적 크기와 차이에 대해 이야기해야 할 때
EDA 시각화 기초 블로그

시계열 분석
시계열 분석(time-series analysis)은 일정 간격의 시간순으로 저장된 데이터에서 유의미한 정보를 뽑아 내는 작업으로, 과거의 행동을 이해하고 미래의 행동을 예측하는데 사용됩니다.
시계열은 데이터 분석의 중요한 갈래임에도 불구하고 그 분석 방법의 이론과 적용에 대한 기술적 장벽과 미래를 예측하는 일에 수반되는 여러 한계들 때문에 실무 관점의 데이터 활용에서 그 사용이 매우 제한적이었습니다.
하지만, 현업들이 의사결정에 활용할 수 있는 시계열 데이터가 증가하고 있고, 시계열 분석만이 제공할 수 있는 인사이트가 존재한다는 사실을 고려할 때, 더 많은 현업들이 더 자주 시계열 데이터를 활용해야 한다고 생각합니다.
아래 글과 강의 영상에서는
•
동영상 강의: 전통적 시계열 데이터 분석의 주요 개념과 AR(AutoRegressive; 자기회귀) 모델에 대해 설명하고, 최신 기계학습 기술을 활용한 시계열 분석도 가볍게 살펴보고
시계열 분석 : 시간의 흐름에 따른 지표의 변화를 이해하고자 할 때
EDA 시각화 기초 블로그
집계값(평균)이 아닌, 개별 레코드 수준에서 분석해야 하는 이유
아쉽게도 우리는 개별 레코드 수준의 시각화에 익숙하지 못하다. 바차트, 라인차트 등 데이터를 평균이나 총합으로 요약, 집계하여 보여주는 대시보드 차트에 너무 친숙해진 탓이다.

평균적 이해를 넘어서

분포 : 개별 레코드 수준의 시각화를 통해 불확실성을 말해야 할 때
EDA 시각화 기초 블로그
데이터 시각화, 정보 디자인 분야의 걸출한 학자이신 “Edward Tufte”는 그의 저서 “Envisioning Information”에서 “데이터 속에 담긴 정보를 제대로 그려내기 위해서는 평평한 2차원(종이, 화면)의 속박을 벗어나야 한다. 왜냐하면, 우리가 이해하고자 하는 모든 흥미로운 것들은 필연적으로 여러개의 변수들로 구성되어 있기 때문이다.”라고 말했습니다.
“Escaping this flatland is the essential task of envisioning information — for all the interesting worlds (physical, biological, imaginary, human) that we seek to understand are inevitably and happily multivariate in nature.”
한편, 현대적 의미의 데이터 시각화와 EDA(탐험적 데이터 분석)의 창시자로 추앙되는 존 튜키님이 “하나의 숫자가 모든 걸 말해줄 거라 기대하지 않듯이 하나의 차트가 모든 걸 보여줄 거라 기대하지 말자.”고 이야기했던 것은 복잡한 현실을 추상화하여 그 한 단면만을 보여주는 데이터 시각화에 대한 경계였을 터입니다.
There is no more reason to expect one graph to “tell all” than to expect one number to do the same. by John Tukey
이차원 공간에 놓인 하나의 창 속에 담긴 차트는 하나의 사실, 한가지 측면(단면/Facet)에 대해서만 말하게 하는 편이 옳습니다. 세상의 복잡성을 반영할 의도로, 너무 많은 범주(차원/Dimension)를 한 창에 표현하면 인지적 과부하(cognitive overload)가 올 수 있기 때문입니다.
하지만, 복잡다단한 현실의 반영인 데이터는 하나의 창 안에 두개의 차원(X, Y)을 사용하여 표현하기에는 너무 많은 변수를 포함하고 있기 쉽습니다. 이번 강의와 블로그에서는 여러 차원을 동시에 사용하여 데이터셋에 담긴 변수들 간의 복잡한 관계를 효과적으로 시각화하는 방법을 다루어 보겠습니다.
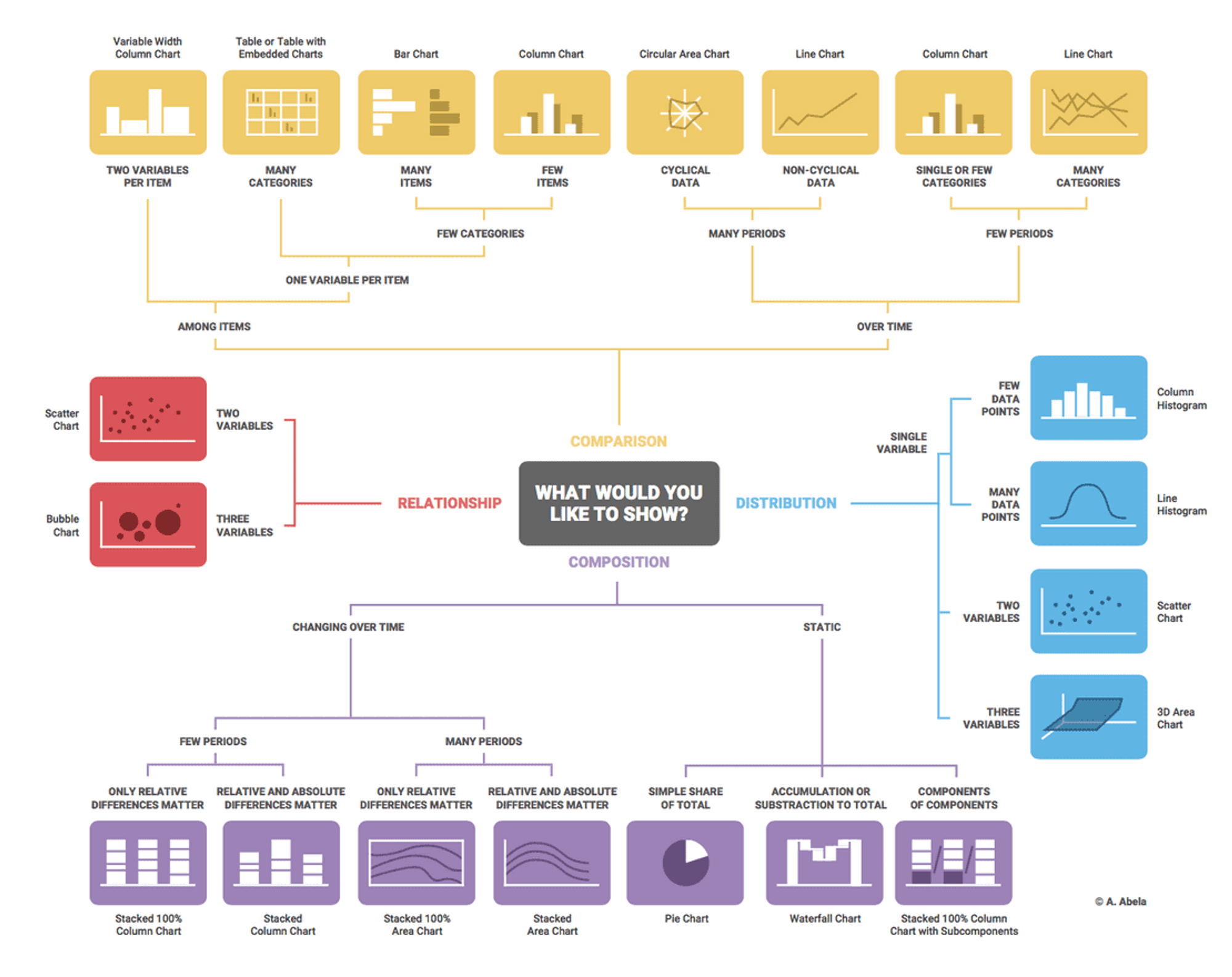

다변량 데이터 시각화 : 여러 변수(차원)들을 한 화면에 시각화하는 방법들
EDA 시각화 실전 블로그





