Intro: 서베이 데이터 분석에 대해서
행동 데이터 vs 서베이 데이터
관찰(을 통한 행동) 데이터가 넘쳐나는 빅데이터 시대에 왜 관찰하지(Observing Behaviours) 않고 구태의연하게 서베이를 통해 물어 보냐(Asking Questions)고 묻는다면 (그냥 홍시맛이 나서 홍시라 생각했다는 장금이의 답변처럼) “물어볼 수 있어서 물었다”고 답해도 괜찮다는 이야기를 해보려고 합니다.
주변에 서베이 데이터를 대체할 수 있는 (직원들의) 행동 데이터가 흔하다 믿고 있는 분들이 서베이 데이터를 가치없다고 폄하하고 있다면 사회과학(Social Science) 진영의 오랜 연구전통과 방법론을 최근 데이터과학(Data Science)과 결합하여 돌파구를 찾아보는 것도 좋겠습니다.
사회 과학 + 데이터 과학(Social science + Data science)
최소한의 노력과 비용으로 르완다 전국의 소득수준 분포를 정확하게 확인하려면 어떻게 해야할까요?
2009년 Joshua Blumenstock(빈곤한 국가나 분쟁 지역에 사는 사람들의 사회적 경제적 처지를 데이터를 통해 설명하는 유익한 프로젝트를 수행하고 있는 UC Berkeley 대학의 조교수)은 이 문제를 달랑 856명에게 전화를 돌려 해결하였습니다.
그 내용을 간단히 요약하면, 르완다 1위 무선통신사업자가 보유한 150만여명 가입자들의 CDR(Call Detail Records; 어디 사는 누가 어디 사는 누구와 얼마 동안 통화했는지를 기록한 로그) 데이터와 전화 설문을 통해 확인한 소득/경제 수준에 대한 데이터를 결합하여 CDR 정보로 소득 수준을 예측하는 모형을 만들었던 것이죠.
서베이를 통해 확인한 850여명의 소득/경제수준(Y)과 이들의 모바일 전화통화 내역(X; CDR)을 기계학습 알고리즘을 사용하여 학습한 후, 예측모형을 만들어서 CDR 정보(X)만으로 소득/경제 수준(Y)을 예측하도록 했습니다.
사회과학 연구 방법인 서베이와 데이터과학을 결합하여 저렴하고 빠르게 유용한 정보를 얻은 훌륭한 사례입니다.
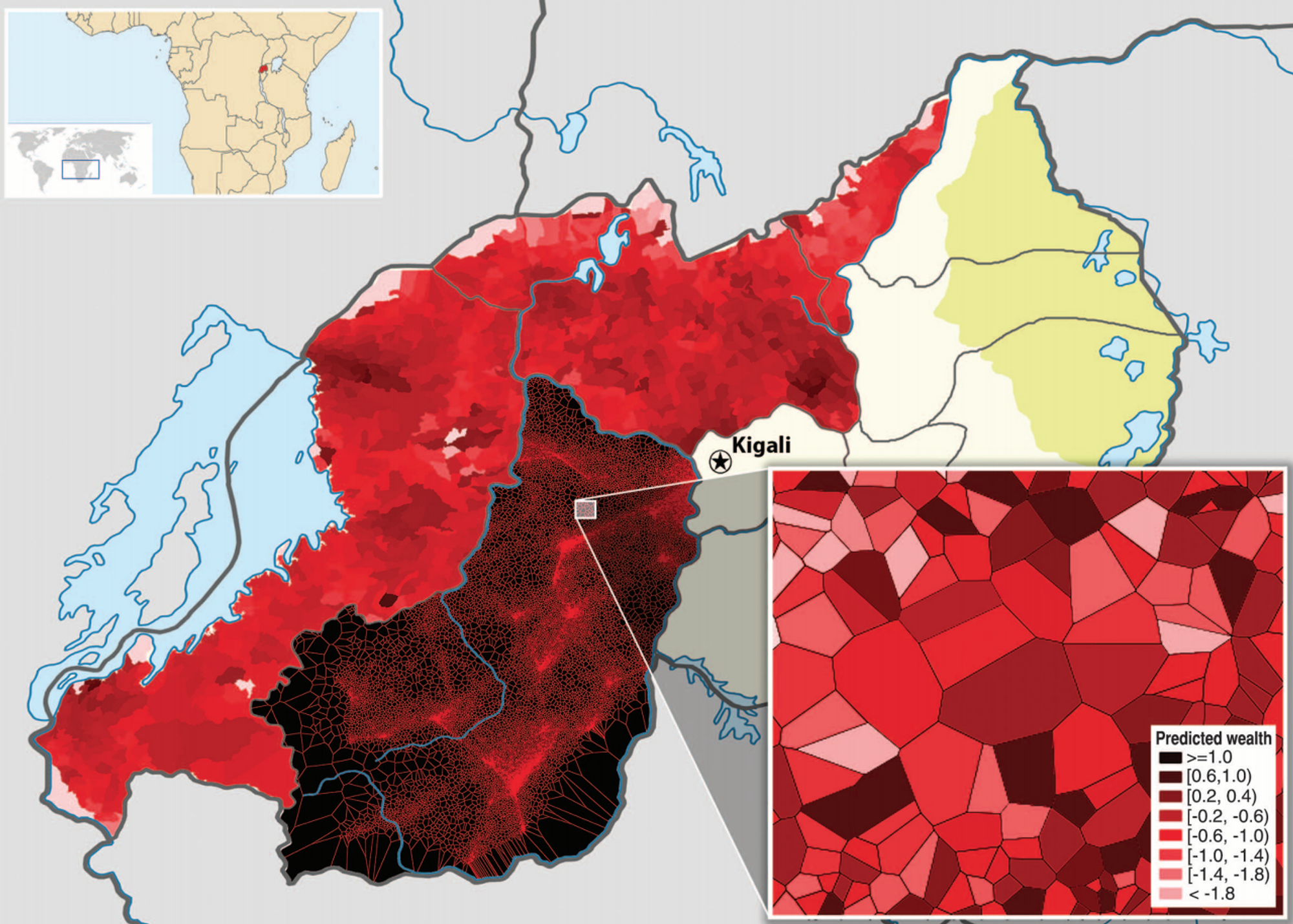
Call Record로 작성한 르완다 빈부 지도
참고) 해당 프로젝트에 대한 보다 자세한 내용:
서베이 데이터 분석 수행시 주의해야 할 점
초파리를 연구하는 사람들은 초파리를 더 잘 이해하기 위해서 초파리의 행동을 관찰하는 수밖에 없겠죠.
하지만, 사람을 연구하는 사람들은 사람의 행동을 관찰하는 것에 추가하여 사람에게 직접 궁금한 걸 물어볼 수 있습니다.
설문 조사 결과에는 일반적으로 두가지 오류가 있다고 알려져 있습니다.
•
Representation Error: 대표성 오류; 설문에 참가한 사람들의 답변을 가지고 모집단(population)에 대한 추론(일반화)을 하는 과정에서 발생하는 오류; *전직원을 대상으로 실시하는 서베이처럼 sample=population인 경우는 non-response(설문에 응하지 않은 사람들)가 어느 정도 random하게(고르게) 분포된 경우 대표성 오류는 무시해도 됨. [*저자의 주관적 의견임]
•
Measurement Error: 측정 오류; 말한 것으로부터 생각이나 행동을 추론하는 과정에서 발생하는 오류; 동일한 질문이라도 질문의 구조(묻는 방식)에 따라 답변이 달라짐. *기업 내 서베이의 경우 익명성이나 서베이 효용에 대한 불신으로 직원들이 건성으로 두루두루 좋게 답변하는 경향이 존재. [*저자의 주관적 의견임]
행동 데이터를 통해서는 절대 알 수 없는 것들
이러한 설문의 명백한 한계에도 불구하고 행동 데이터를 통해서는 절대 알 수 없는 것들이 있습니다.
예를 들면, 사람의 행위를 예측하는 요인(driver; cause)들은 대개 감정, 인식, 지식, 의견 등 내면의 상태(internal state)와 관련된 것들인데 우리 두개골에 꼭꼭 쌓여져 있는 내면의 상태를 알 수 있는 최선의, 그리고 현재로서 유일한, 방법은 여전히 물어보는 것입니다.
또한, 기업 환경 내에서 측정 가능한 직원들의 행동 데이터(예, 평균 이메일 발신 건수)는 많은 경우 우리가 이해/예측하고자 하는 행위(고성과)의 원인(cause)이기보다는 증상(symptoms)이기 쉽습니다.
예를 들면, 성과점수와 이메일 발신건수 사이에서 높은 상관관계가 발견되었을 때 이메일을 많이 보내서(cause) 고성과자(effect)라고 해석하기보다는 고성과자라서 일을 많이 해서 결과적으로 메일을 많이 보냈다고 해석하는 것이 더 타당합니다. 그리고, 르완다 사례에서 확인했듯이 설문 데이터를 행동 (빅)데이터와 결합하는 경우 행동 데이터만으로는 불가능했던 깊고 파급력있는 분석이 가능해 지기도 합니다.
실습

Dataset: 행복에 대한 설문 조사
공개된 서베이 데이터를 HeartCount(하트카운트)를 통해 분석해보겠습니다.
분석에 사용한 데이터는 2013년도에 영국의 한 통계수업에서 학생들에게 서베이를 실시한 결과입니다. 총 150개의 문항으로 구성되어 있으며 대부분은 5점 척도(Strongly disagree: 1점, Strongly agree; 5점) 중 하나를 선택하게 설계되었습니다.
질문을 구성하는 주요 항목들은:
•
음악/영화에 대한 선호도 (예, 나는 음악 듣기를 즐긴다.)
•
취미, 건강 습관, 소비 습관 (예, 나는 시 쓰는 것을 좋아한다.)
•
성격, 인생관, 무서워하는 것 (예, 나는 화났을 때 물건을 부순 적이 있다.)
•
인구통계학적 특성 (나이, 성별, 교육정도, 형제자매수 등)
원본 데이터와 관련 내용을 확인하려면:
문항 중 “Happines in Life: I am 100% happy with my life(행복도; 나는 내 인생에 완전 만족한다)”에 대한 답변과 다른 문항들 간의 관계를 통해 행복의 요인(What Drives Happiness)를 찾아 보겠습니다.
Analysis in Heartcount
Small Multiples: 전체를 한 눈에
우선, 하트카운트의 시각화 기능 중 하나인 Small Multiples에서 [Happiness in Life] 문항에 대한 답변 점수(5점 척도)와 다른 문항 답변 점수들 간의 상관관계(Correlation)를 내림차순으로 확인해보았습니다.
레시피
분석하고자 하는 변수를 Y축에 설정하고 ‘분석’을 클릭하면, 상관계수가 높은 순서대로 결과가 나타납니다.
상관계수 : 절대값이 1에 가까울수록 둘은 높은 선형적 관계를 가집니다.
선형적 관계 : x값과 y값이 직선으로 서로 비례(; 하나가 증가하면 다른 하나도 증가(양의 상관관계)하거나 다른 하나는 감소(음의 상관관계)
분석 결과 해석
상관계수의 절대값 크기 기준으로 상위 네가지를 살펴보면:
1위: “Energy Level: 나는 항상 에너지가 넘친다.”와 가장 큰 양의 상관관계 (+0.44)
2위: “Loneliness: 난 외롭다.”와 다음으로 큰 음의 상관관계 (-0.44)
3위: “Changing the past: 나는 과거로 돌아가 내가 한 일을 되돌리고 싶다.”와 음의 상관관계 (-0.35)
4위: “Number of Friends: 나는 친구가 많다.”와 양의 상관관계 (0.32)
여기서 Energy Level과 Loneliness는 (Un)Happy의 요인(Cause)이기 보다는 (Un)Happy의 증상(Symptoms)에 가깝습니다. 상관관계가 높은 다른 항목이 Cause냐 Symptom이냐에 대한 판단은 데이터 분석의 영역이 아니라 오히려 상식의 영역이라고 할 수 있습니다.
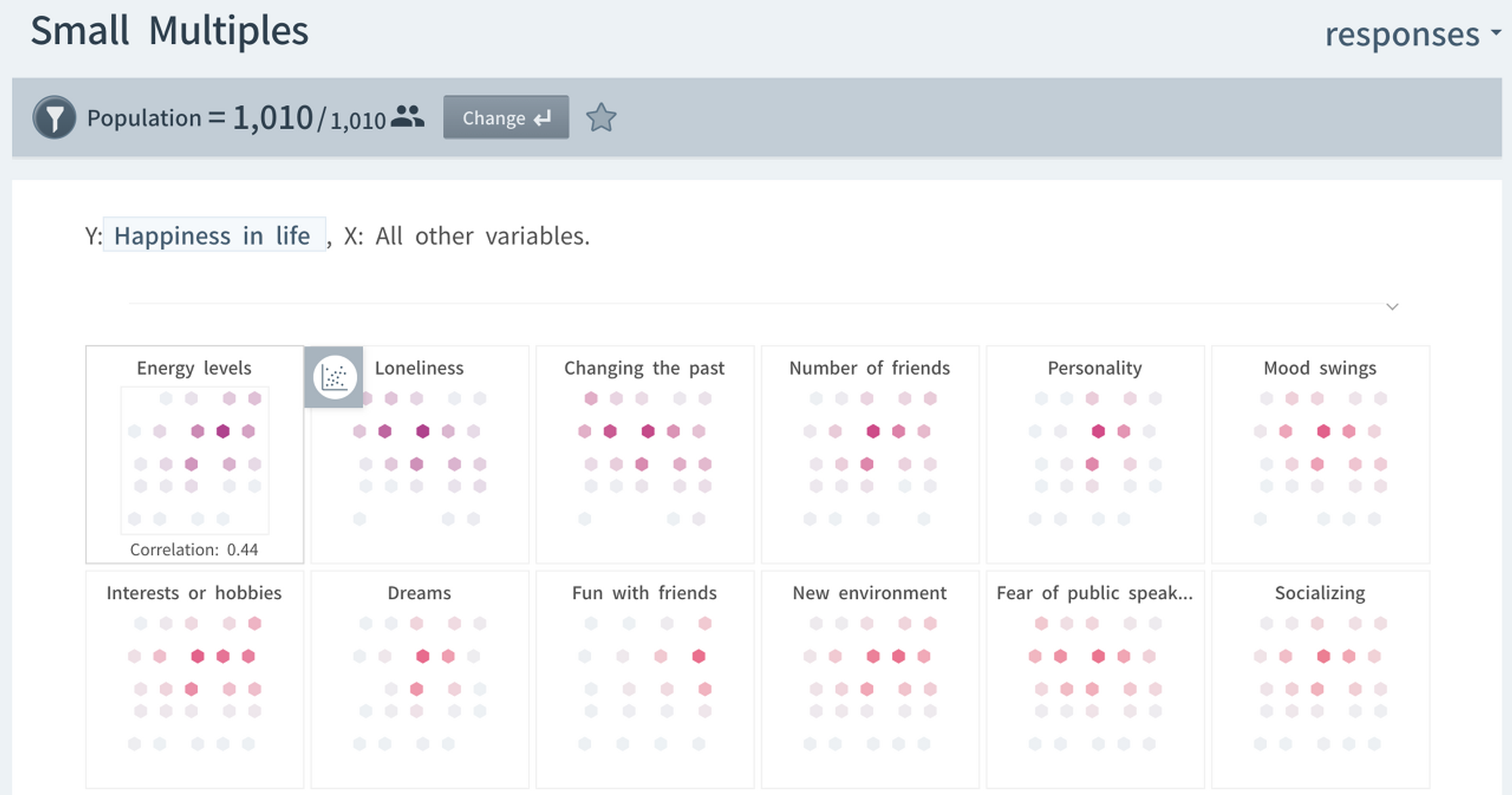
5점 척도 이외의 객관식 문항들 중 음주/흡연 습관에 대한 답변 유형별로 행복도 평균 점수를 비교해 보면,
(행복도 전체 평균점수 : 3.71)
•
음주 습관: 자주 많이 마신다(평균: 3.79) > 안 마신다(3.73) > 가끔 절제하며 마신다(3.67)
•
흡연 습관: 지금 흡연 중(평균: 3.78) > 핀 적 없다(3.72) > 과거에 폈으나 지금 끊었다(3.63)
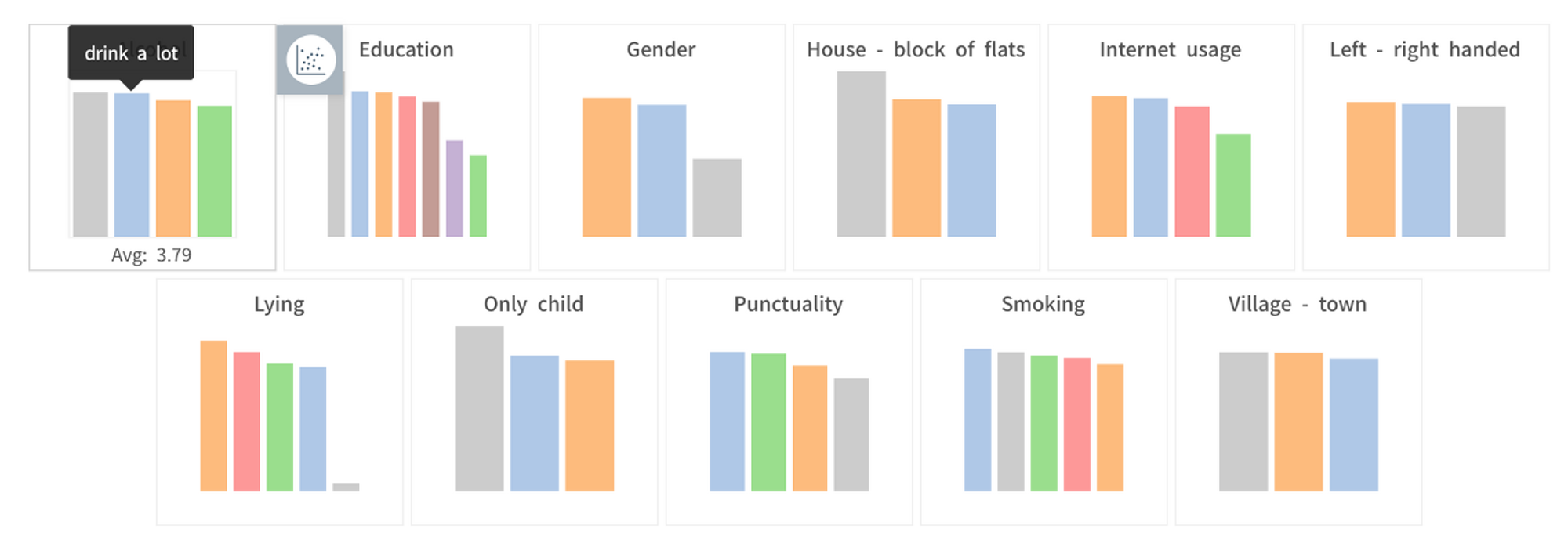
Drill-Down: 변수의 조합에 따른 랭킹
레시피
•
드릴다운에서 평균을 비교하고자 하는 변수를 선택합니다.
•
총 3가지 형태 중 마지막 형태를 선택하면 ‘전체 평균’ 기준으로 먼 순서대로 한 눈에 확인할 수 있습니다.
•
더 유의미한 분석을 위해, 아래 예시처럼 최소 레코드 개수를 설정할 수 있습니다.
•
드릴다운할 조건(변수의 조합)을 계속해서 추가할 수 있습니다.
분석 결과 해석
•
놀랍게도, 담배도 술도 입에 댄 적이 없는 집단이 평균 3.87점으로 제일 행복했고(우측의 첫번째 줄)
•
반면, 술은 마시지 않고 담배는 한 때 피웠으나 지금은 끊은 집단이 3.54점으로 제일 불행했다는 것을 알 수 있었습니다. (좌측 첫번째 줄).
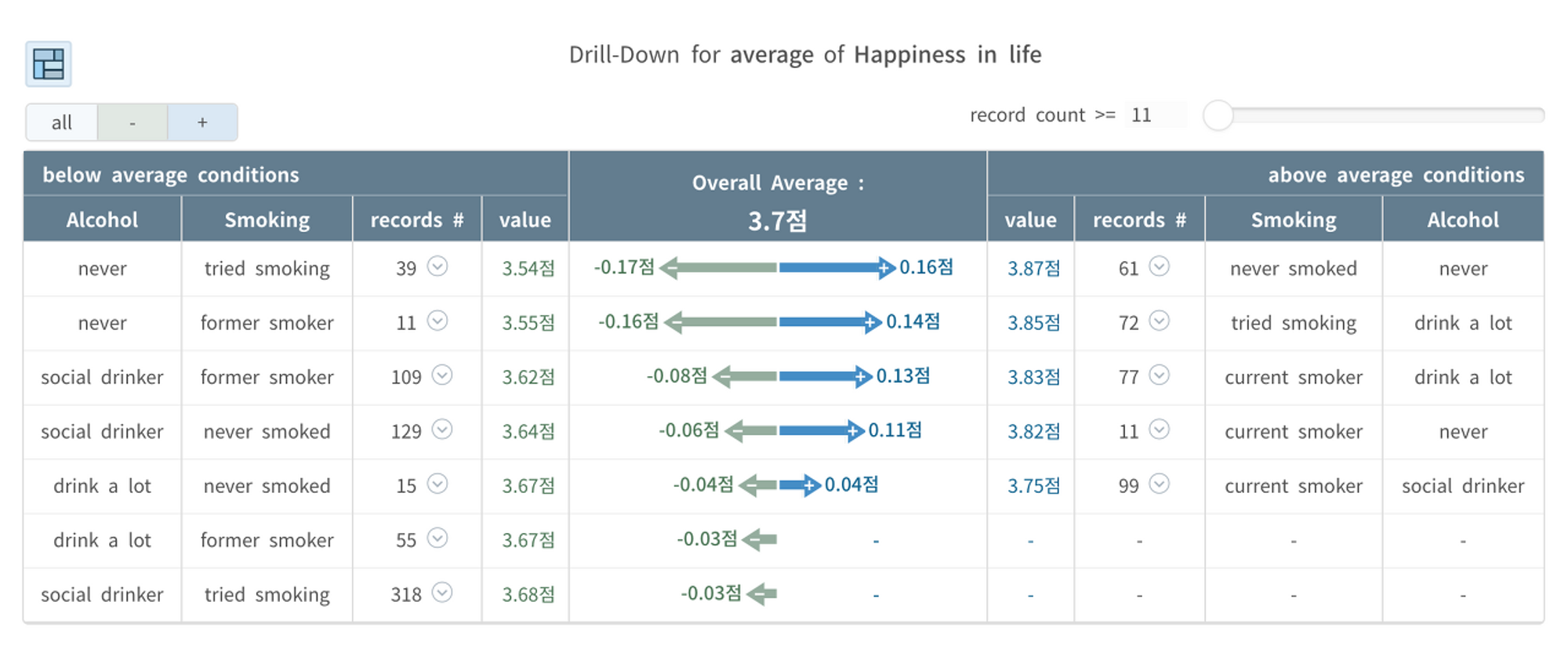
음주와 흡연 각각에 대해 하나의 관점(차원; 변수)으로 행복도의 평균을 비교했을 때와 결과가 너무 상이한 걸 알 수 있죠?
납득이 잘 안되어서 Gender(성별) 변수를 추가하여 세가지 관점의 조합으로 행복도 점수를 쪼개(Drill-Down) 보았습니다.
•
술, 담배 둘 다 절대 하지 않는 여자의 경우 행복도가 3.94로 매우 높음 (우측열 두번째 줄)
•
술, 담배 둘 다 절대 하지 않는 남자의 경우 행복도가 3.79로 평균을 살짝 상회 (우측 맨아래)
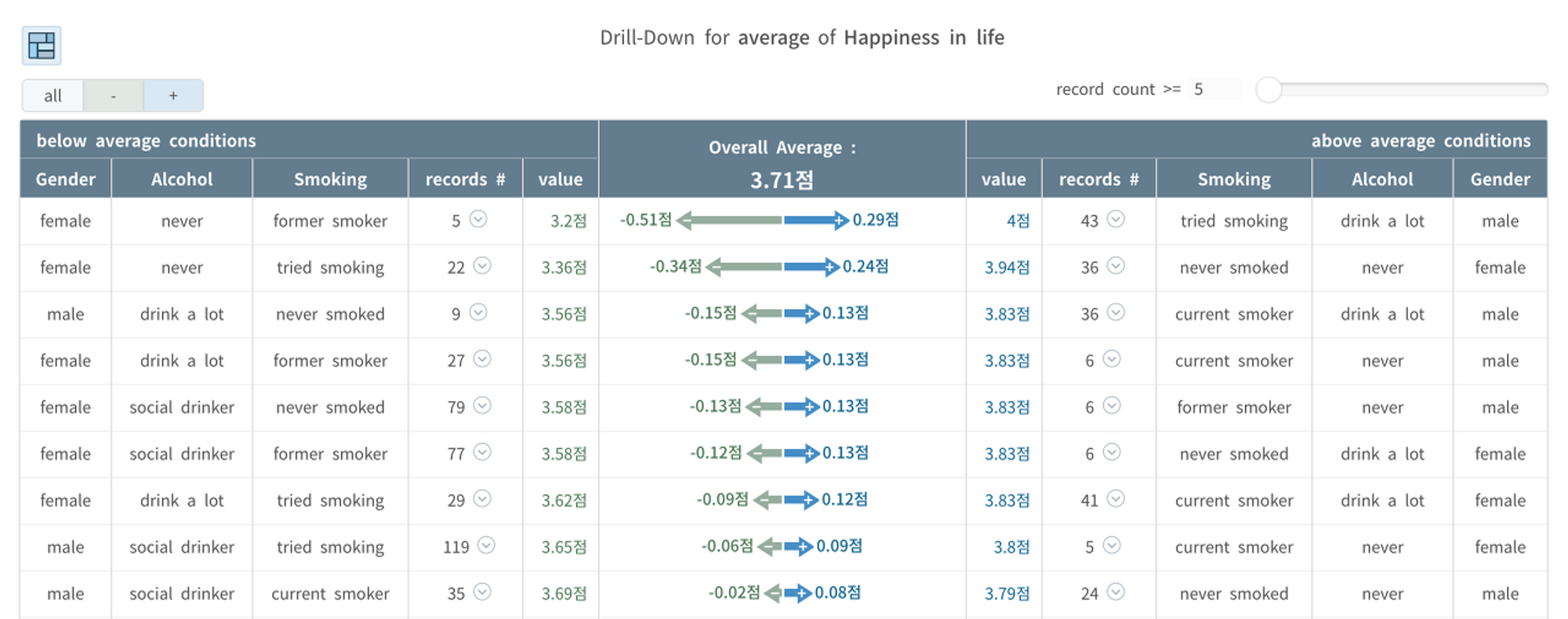
흡연, 음주 습관, 성별 세개 변수의 조합으로 행복도 점수 드릴다운한 결과
위에서 성별로 구분하지 않고 음주, 흡연 두 개 관점의 조합으로만 비교한 경우 술, 담배 모두 절대 하지 않는 집단의 행복도가 가장 높았던 건 여자의 영향이 컸다는 걸 발견할 수 있었습니다.
세개의 조합으로 비교한 경우,
남자는
•
담배를 피다 지금은 끊었지만 술은 자주 많이 마시는 남자들이 제일 행복했고
•
그 다음으로 술 담배 꾸준히 하는 친구들이 행복했다. (*설문 대상은 나이 15~30세의 영국 학생들과 학생들의 지인들이었음)
관계분석: Driver (통계적으로 유의미한 요인들) Premium 기능
레시피
요인 분석에서, 차이를 가져온 요인을 분석하고자 하는 수치형 KPI(Happiness)를 선택하고 [분석]을 클릭합니다.
HeartCount가 자동으로 가공하여 추가한 변수들을 제외하고 원본 엑셀에 담긴 149개 변수만 사용하여 회귀분석을 하려면, 변수 Filtering 하는 상단 메뉴의 톱니 아이콘을 클릭한 후 “파생 변수 포함” 상자를 uncheck하시면 됩니다.
분석 결과 해석
•
개별변수의 중요도에 따른 회귀분석 결과 순위를 보면 Small Multiples 화면에서 살펴본 상관관계의 크기 순서와 동일하게 나오는 걸 확인할 수 있습니다. 이건 개별 독립변수와 종속변수 사이의 관계를 분석하는 단순회귀분석인 경우 회귀분석 결과의 중요도인 결정계수(R²)가 수학적으로 상관계수(r)를 제곱한 값이라 그렇습니다. (*. 에너지 레벨의 상관계수인 0.44를 제곱하면, 0.194)
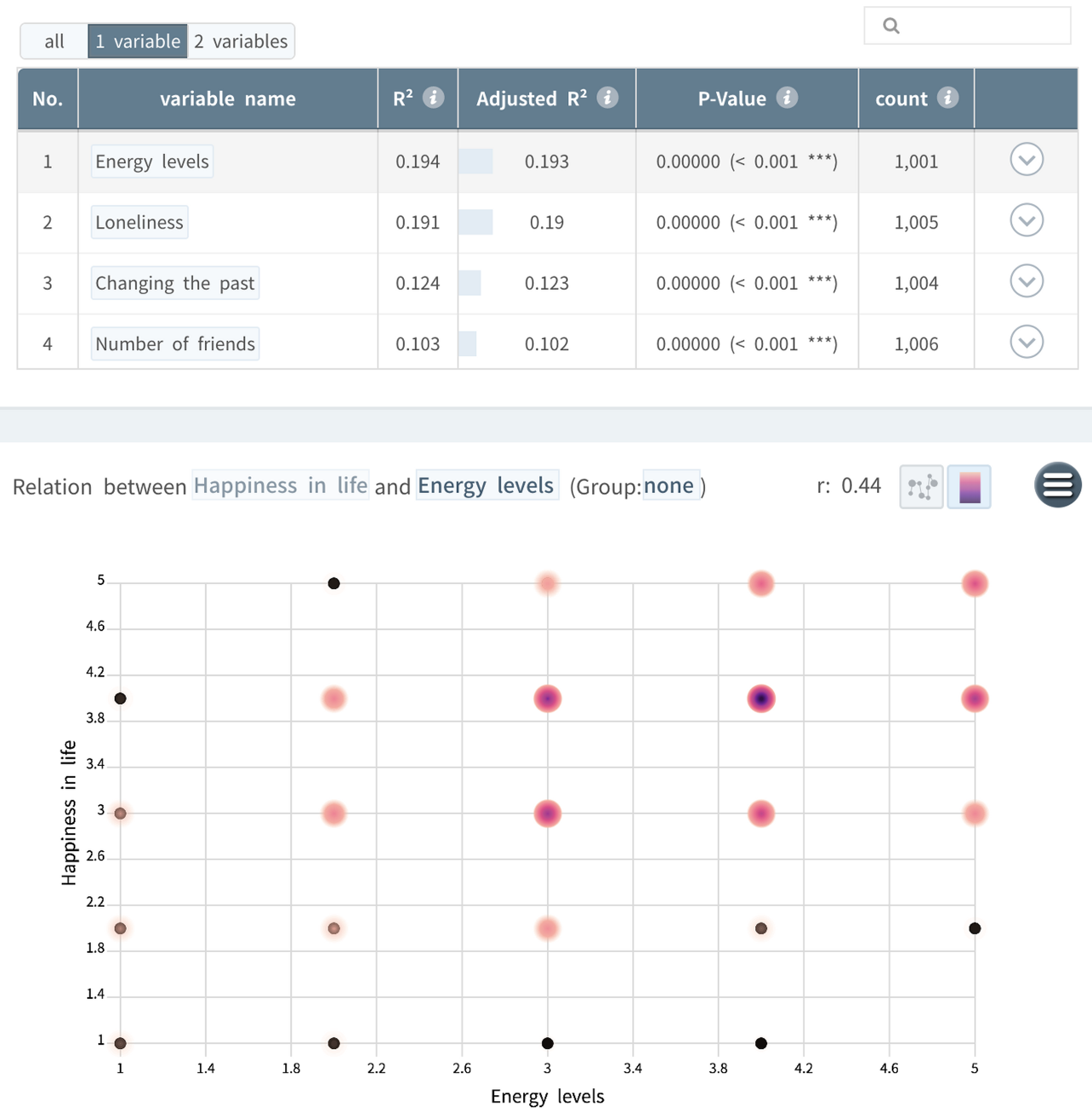
•
하지만, 흡연이나 음주 습관은 관계분석 결과 테이블에 나오지 않았습니다. 흡연습관이나 음주습관에 따른 행복도 점수의 차이가 통계적으로 유의미하지 않기 때문이죠.
통계적 유의미성에 대해 간단히 집고 넘어가자면, 집단 내(술먹는 집단) 행복도 차이보다 집단 간(술먹는 집단과 안 먹는 집단 사이) 차이가 커야 통계적으로 유의미한 차이가 존재한다고 주장할 수 있는데 아래 그림처럼 개별 집단별로 평균점수는 차이가 나지만 95% 신뢰구간 평균 점수를 비교하면 신뢰구간이 서로 다 겹쳐서 집단 간 차이가 통계적으로 의미없다고 판단되었기 때문입니다.
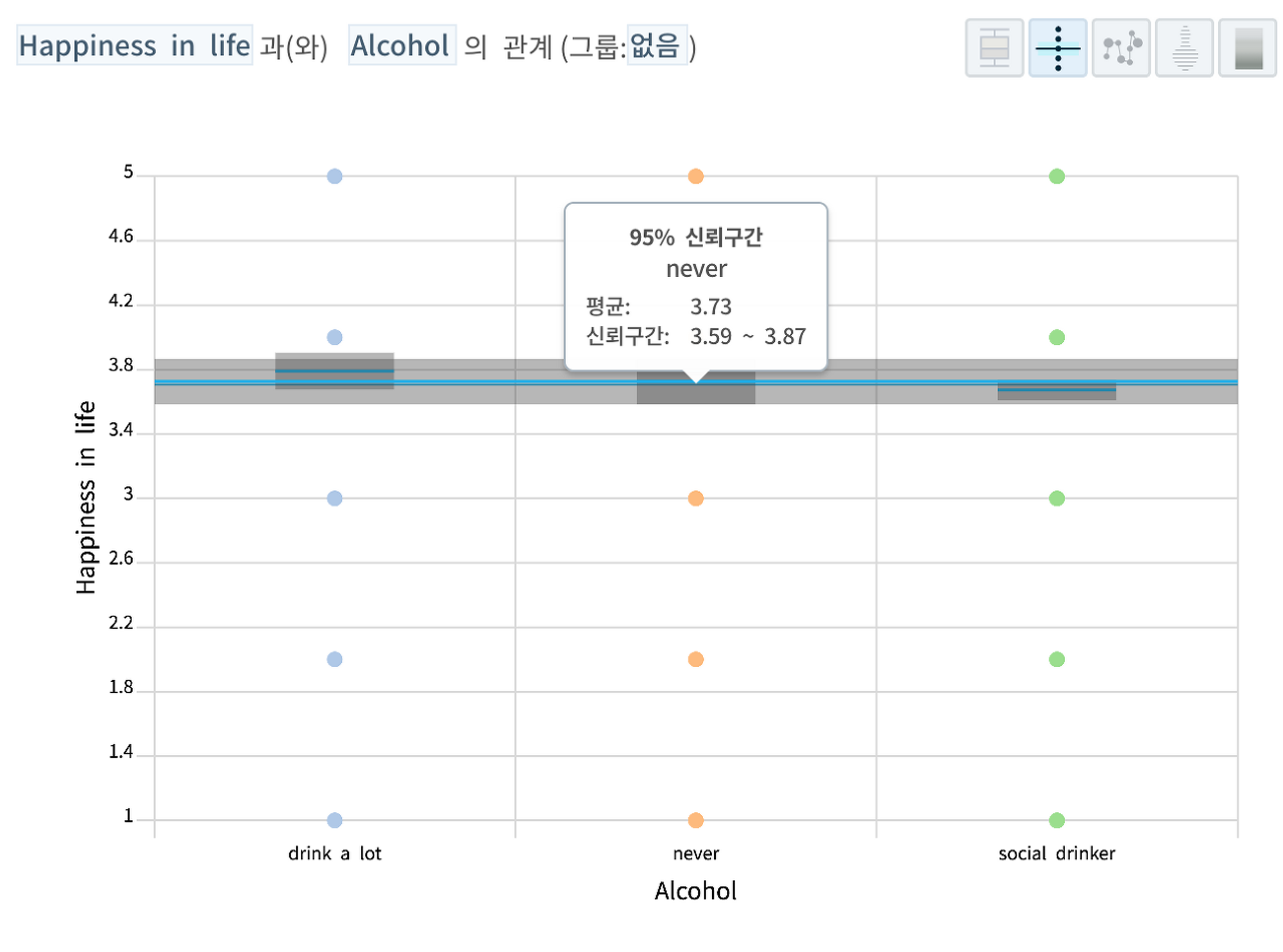
통계적으로 유의미한 것(Statistical Significance)보다는 실용적 관점에서 유의미한 것(Practical Significance)이 회사를 이롭게 하자는 취지에서 데이터를 분석하는 현업 입장에서 더 중요합니다.
Micro-Segmentation: 양극단을 비교하는 아주 좋은 습관 Premium 기능
마이크로세그멘테이션은 하트카운트 자체 의사결정트리 알고리즘을 이용한 기능으로, 유사한 특성이나 행동을 보이는 집단이 밀집해 있는 세그먼트를 찾는다고 해서 Micro-Segmentation라는 이름이 지어졌습니다.
‘Happiness in life’에 5점이라고 답변한 확실히 행복한 집단(닮고 싶은 집단; 73명)과 1~2점이라고 답변한 확실히 불행한 집단(30명)을 타겟으로 정하여 두 집단(세그먼트)을 구분하는 논리적 규칙을 찾아보려고 합니다.
레시피
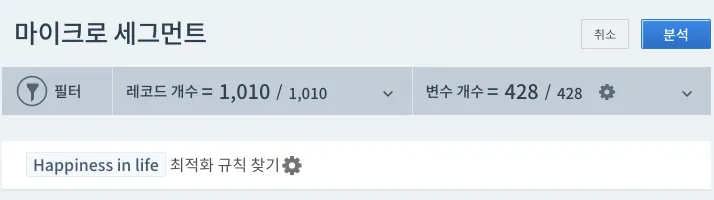
•
우선 하트카운트의 공통 기능, 필터링 기능을 이용해서 아래와 같이 분석 조건을 설정하였습니다.
◦
성별의 경우 남자만 분석
◦
분석에 사용할 총 150개 변수 중 행/불행의 원인이라기 보다는 결과에 가까운 [Loneliness]와 [Energy Level] 변수 제외
•
최적화 규칙을 찾을 변수로 ‘Happiness in life’를 선택하고 상세 설정으로 직접 타겟을 커스텀했습니다.
◦
기본 디폴트값: 수치형 변수의 경우, 상위 20% 그룹 vs 하위 20% 그룹의 분류 규칙 분석
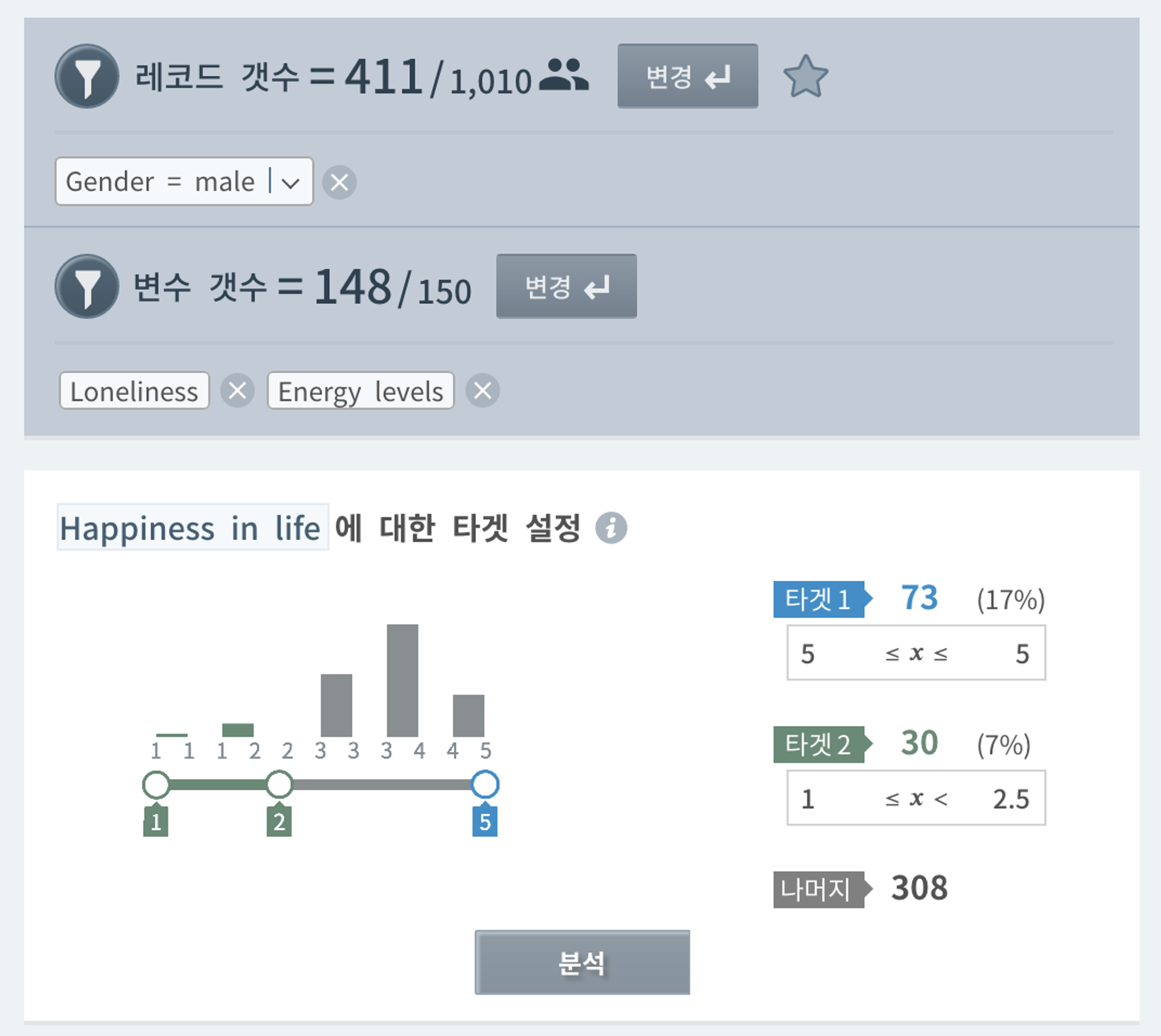
분석 결과 해석
의사결정 트리 결과를 보면,
•
남자의 경우 친구수가 많으면(4점 이상 답변) 무조건 행복: 4.76점
•
친구수가 아주 많지는 않지만(3점 이하 답변) 과거에 집착 적게 하면 (2점 이하) 행복: 4.3점
•
친구수도 적은데(3점 이하 답변) 과거에 붙들려 살면(3점 이상) 크게 불행: 2.32점
아까 술 주제로 돌아가면 음주를 상습적으로 하는 행위는 친구가 많은 것의 직접적인 결과로 볼 수 있습니다. 남자의 경우 친구의 숫자가 행복도와 음주빈도 둘 다에 영향을 주어 음주빈도와 행복도 사이에 관계가 발견되었을 수도 있겠습니다.

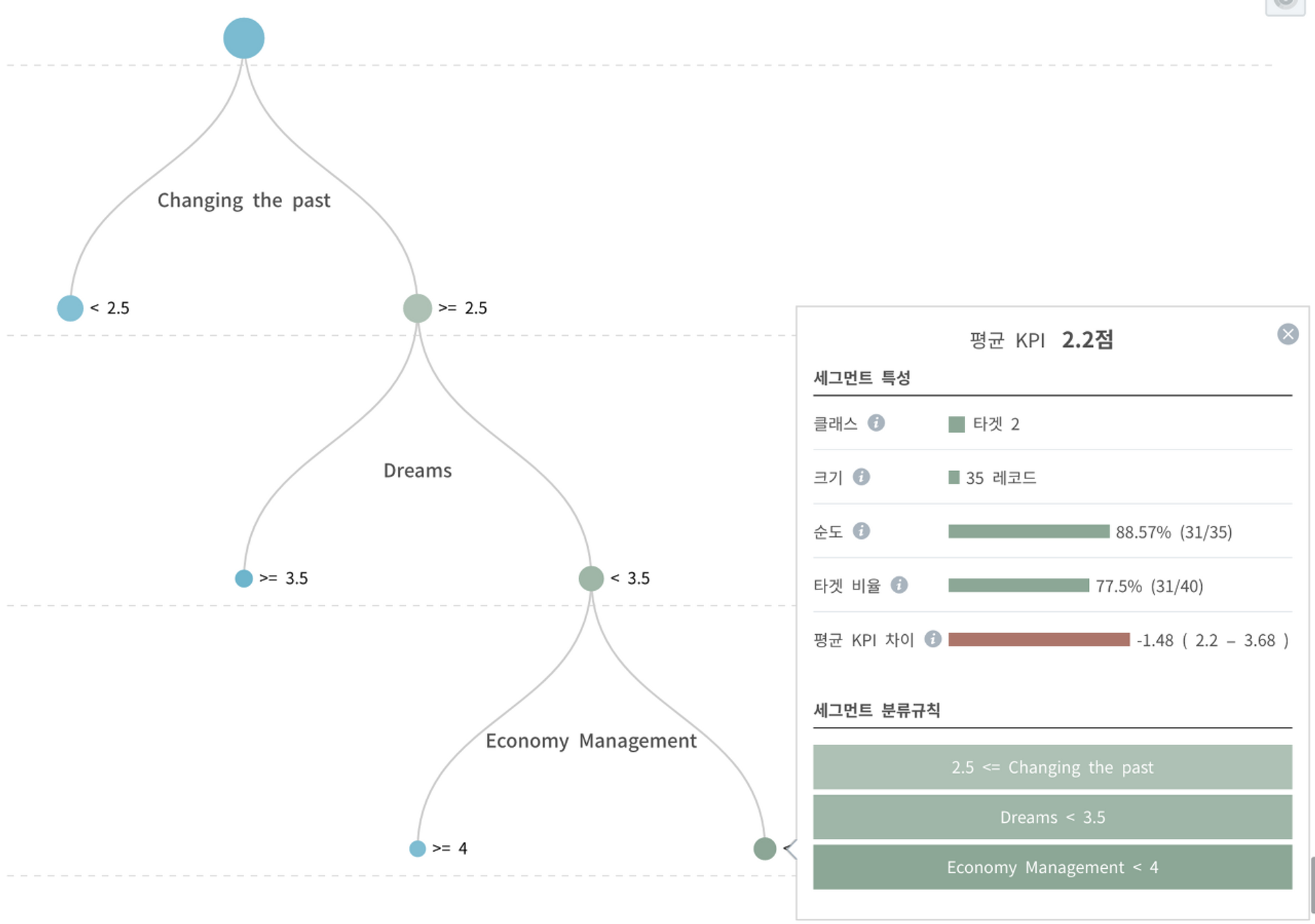
여자도 같은 식으로 행복한 집단과 불행한 집단이 높은 순도로 밀집해 있는 세그먼트의 조건을 찾아보았습니다.
여자의 경우
•
과거의 일에 대해 후회하지 않고 살면(2점 이하 답변) 무조건 행복: 4.76점
•
과거에 대해 집착하지만(3점 이상 답변) 긍적적인 꿈을 안고 살아가면(Dreams: 4점 이상) 행복: 4.33점
•
과거에 대해 집착하고(3점 이상 답변) 미래에 대한 장미빛 꿈도 없지만(Dreams: 3점 이하) 경제/경영에 높은 관심을 갖고 있으면 행복: 4.4점
•
과거에서 헤어나지 못하고 미래는 잿빛이고 경제/경영에 관심까지 없으면 완전 불행: 2.2점