
페이지 오른쪽 상단에 있는 검색을 클릭하여 필요한 것을 검색하세요.
처음이신가요? 
Search


자세한 기능별 사용 방법은 아래 가이드를 참고해주세요
Search














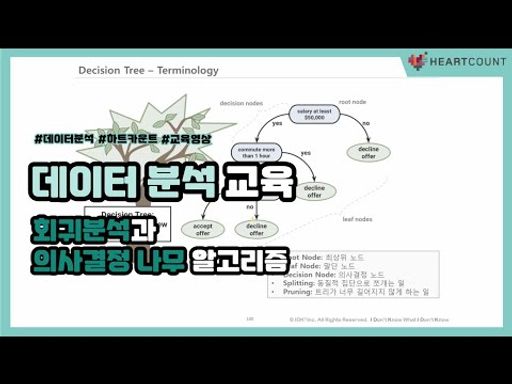
데이터 분석, 하트카운트와 함께 시작해요 ! 교육 콘텐츠 모음
데이터 분석/시각화 기초 체력을 채워줄 아티클들








핵심 내용만 담은 통계학 Playlist




HEARTCOUNT I IDK 2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know
IDK 2 Inc. All Rights Reserved. I Don’t Know What I Don’t Know