
이 글은 데이터 히어로 캠프 1기 멤버 김지은님이 4주차 최종 미션으로 수행하신 분석 사례입니다.
Intro
말레이시아 스타벅스 서베이를 통한 자료에 대해 말레이시아에서 스타벅스 서비스 점수의 요인을 분석하고자 한다. 세밀하게 수요층에 대한 분석을 통해서 항목에 대한 결과값이 긍정적으로 검토되는 집단과 상반되는 집단에게도 부족한 니즈를 면밀히 검토한 후 이를 타겟팅을 하여 마케팅을 할 수 있다는 생각으로 서베이를 분석하고자 한다. 추후 동일한 루트를 통한 국내 데이터셋을 통한 분석을 해보고 싶다.

RM은 말레이시아 통화의 공식 명칭으로 링깃(Ringgit Malaysia)이다.
링깃을 원으로 변환했을 때, RM = 1링깃은 289.70원을 의미한다.
Dataset
: 스타벅스 고객 설문조사 관한 설문 데이터 분석
공개된 서베이 데이터를 HeartCount를 통해 분석해보겠습니다.
스타벅스에서 구매 행동에 대한 100명 이상의 응답자의 설문 조사 질문으로 구성되어 있습니다. 수입은 말레이시아 링깃(RM)으로 표시됩니다.
분석에 사용한 데이터는 2019년도에 말레이시아의 스타벅스 고객들에게 서베이를 실시한 결과입니다. 총 20개의 문항으로 구성되어 있으며 대부분은 5점 척도(Strongly disagree: 1점, Strongly agree; 5점) 중 하나를 선택하게 설계되었습니다.
질문을 구성하는 주요 항목들은:
•
고객에 대한 인구 통계 정보 – 성별, 연령 범위, 고용 상태, 소득 범위
•
스타벅스를 사는 그들의 현재 행동
•
행동에 기여하는 스타벅스의 시설과 특징
원본 데이터와 관련 내용을 확인하려면:
Analysis in HEARTCOUNT
Small Multiples: 전체를 한 눈에
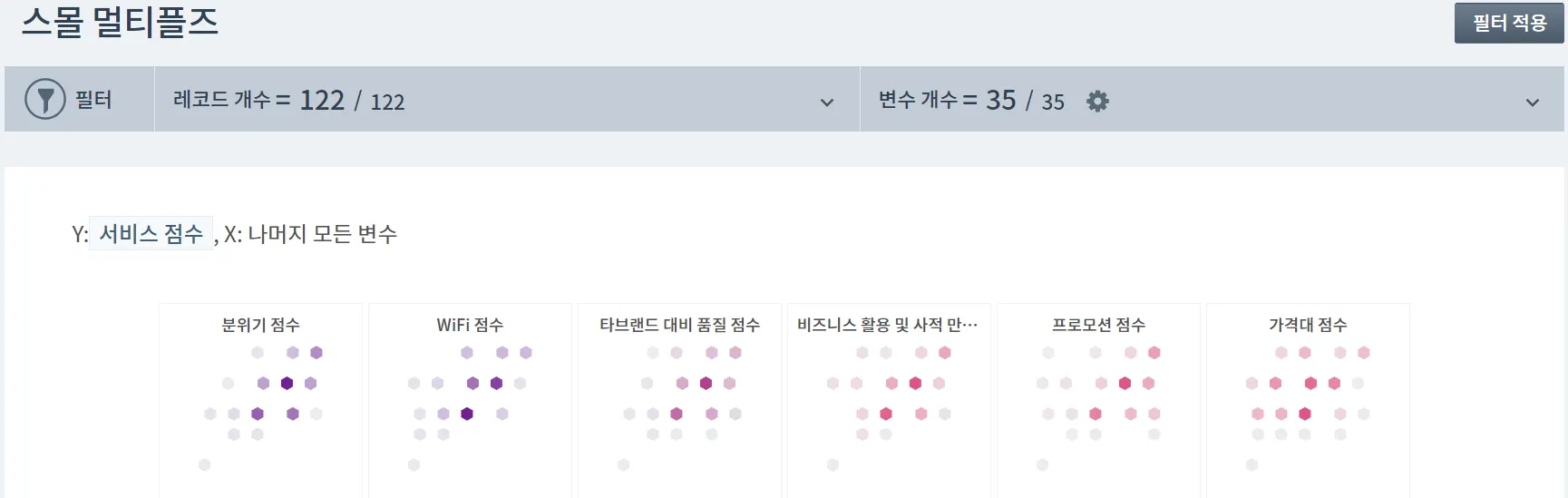
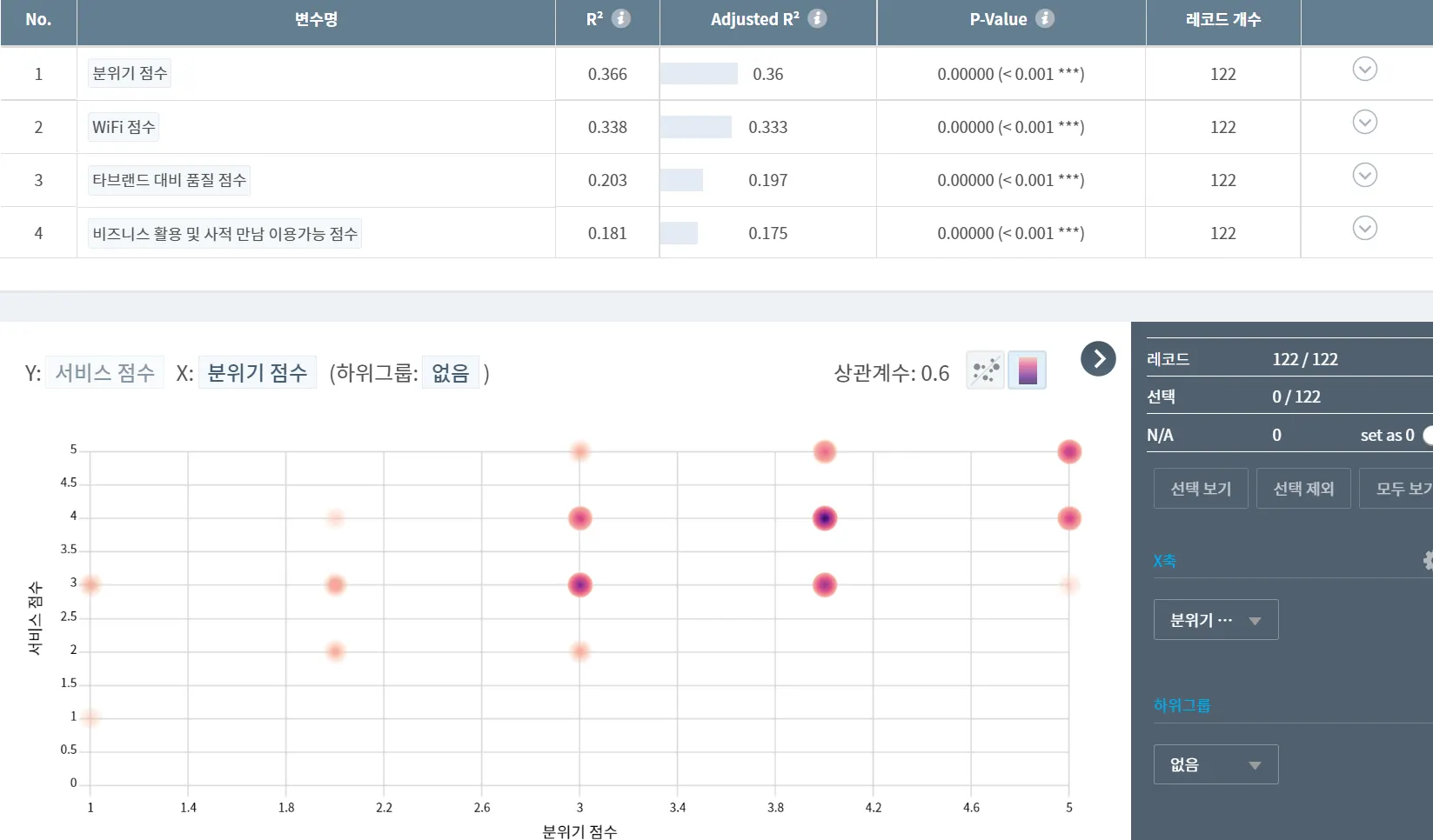
우선, 아래 그림처럼 Small Multiples에서 [서비스 점수] 문항에 대한 답변 점수(5점 척도)와 다른 문항 답변 점수들 간의 상관관계(Correlation)를 내림차순으로 확인해보았습니다.
레시피
분석하고자 하는 변수를 Y축에 설정하고 ‘분석’을 클릭하면, 상관계수가 높은 순서대로 결과가 나타납니다.
상관계수 : 절대값이 1에 가까울수록 둘은 높은 선형적 관계를 가짐
선형적 관계 : x값과 y값이 직선으로 서로 비례(; 하나가 증가하면 다른 하나도 증가(양의 상관관계)하거나 다른 하나는 감소(음의 상관관계)
분석 결과 해석
상관계수의 절대값 크기 기준으로 상위 네가지를 살펴보면:
1위: “분위기 점수 : How would you rate the service at Starbucks? (Promptness, friendliness, etc..)”와 가장 큰 양의 상관관계 (+0.6)
2위: “WiFi 점수 : You rate the WiFi quality at Starbucks as..” 와 다음으로 큰 양의 상관관계 (+0.58)
3위: “타브랜드 대비 품질 점수 : How would you rate the quality of Starbucks compared to other brands (Coffee Bean, Old Town White Coffee..) to be”와 양의 상관관계 (+0.45)
4위: “비즈니스 활용 및 사적 만남 이용가능 점수 : How likely you will choose Starbucks for doing business meetings or hangout with friends?”와 양의 상관관계 (+0.43)
여기서 분위기 점수와 WiFi 점수는 만족도의 요인(Cause)에 가깝습니다. 상관관계가 높은 다른 항목이 Cause라고 볼 수 있습니다.
5점 척도 이외의 객관식 문항들 중 현재상태/접근성에 대한 답변 유형별로 만족도 평균 점수를 비교해 보면,
(만족도 전체 평균점수 : 4.03/3.8)
•
현재 상태 : Housewife(평균: 5) > Employed(3.89) > Self-Employed(3.76) > Student(3.48)
•
접근성 : within 1km(평균: 4) > 1km-3km(3.79) > more than 3km(3.61)
Drill-Down: 변수의 조합에 따른 랭킹
앞에서 높은 접근성, 현재상태 : 주부일 때 보이는 집단이 높은 만족도를 보인 결과에 고무되어 드릴다운 메뉴를 통해 접근성과 현재상태의 조합에 따른 서비스 점수(만족도)를 비교해 보았습니다.
레시피
•
드릴다운에서 평균을 비교하고자 하는 변수를 선택합니다.
•
총 3가지 형태 중 마지막 형태를 선택하면 ‘전체 평균’ 기준으로 먼 순서대로 한 눈에 확인할 수 있습니다.
•
더 유의미한 분석을 위해, 아래 예시처럼 최소 레코드 개수를 설정할 수 있습니다.
•
드릴다운할 조건(변수의 조합)을 계속해서 추가할 수 있습니다.
분석 결과 해석
•
놀랍게도, 현재상태가 Housewife에, 접근성이 more than 3km인 집단이 5점으로 제일 서비스 만족했고(우측의 첫번째줄)
•
반면, 현재상태가 Student에, 접근성이 1km-3km인 집단이 3.55점으로 제일 서비스 불만족했다는 것을 알 수 있었습니다. (좌측 첫번째 줄).
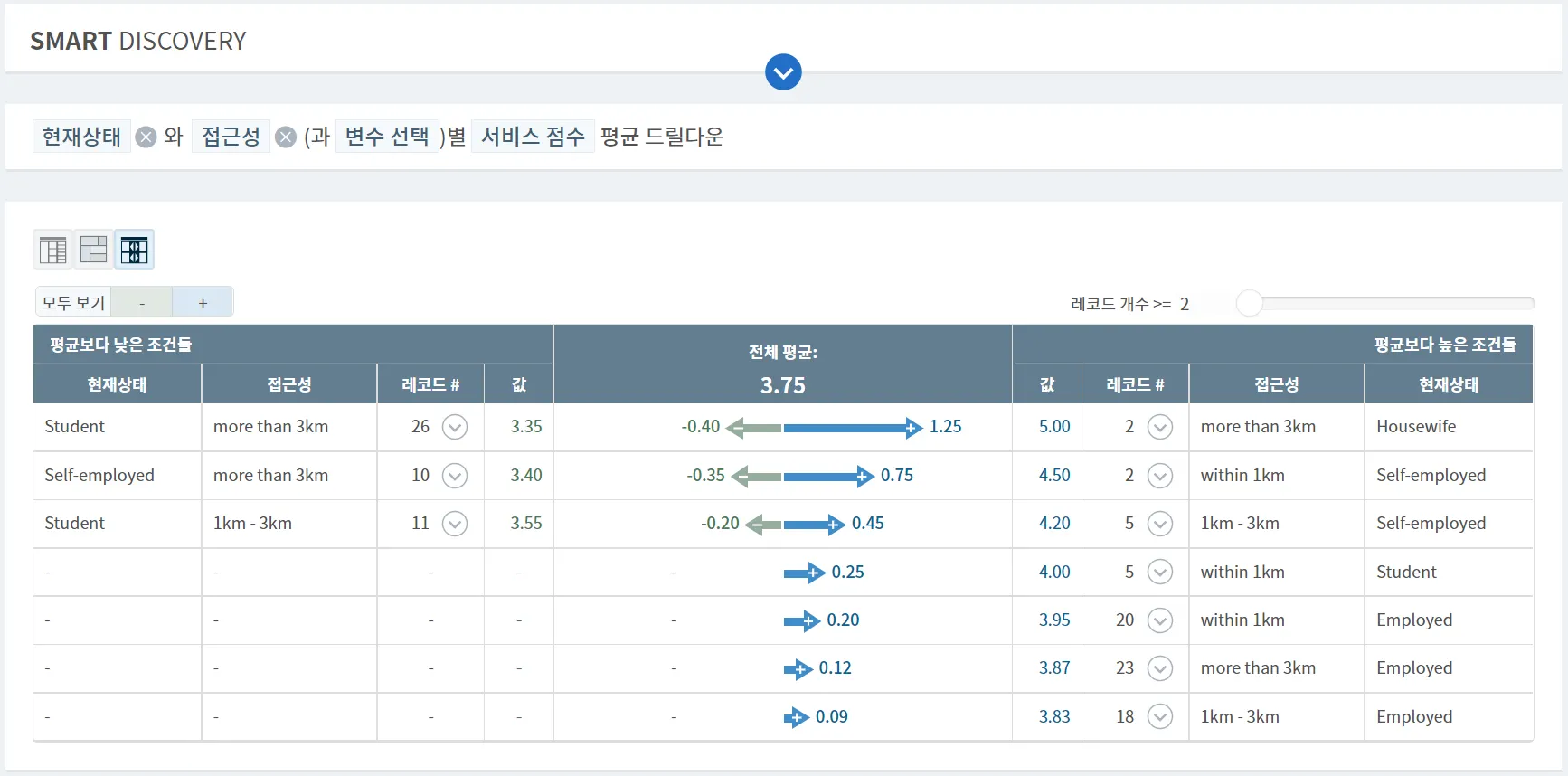
현재상태와 접근성 각각에 대해 하나의 관점(차원; 변수)으로 서비스점수(만족도) 의 평균을 비교했을 때와 결과가 너무 상이한 걸 알 수 있죠?
납득이 잘 안되어서 Gender(성별) 변수를 추가하여 세가지 관점의 조합으로 만족도 점수를 쪼개(Drill-Down) 보았습니다.
•
현재상태가 Housewife, 접근성이 more than 3km인 여자의 경우 서비스점수(만족도)가 5로 매우 높음 (우측열 첫번째 줄)
•
현재상태가 Employed, 접근성이 within 1km 남자의 경우 서비스점수(만족도)가 3.54로 평균을 살짝 상회 (우측 맨아래)
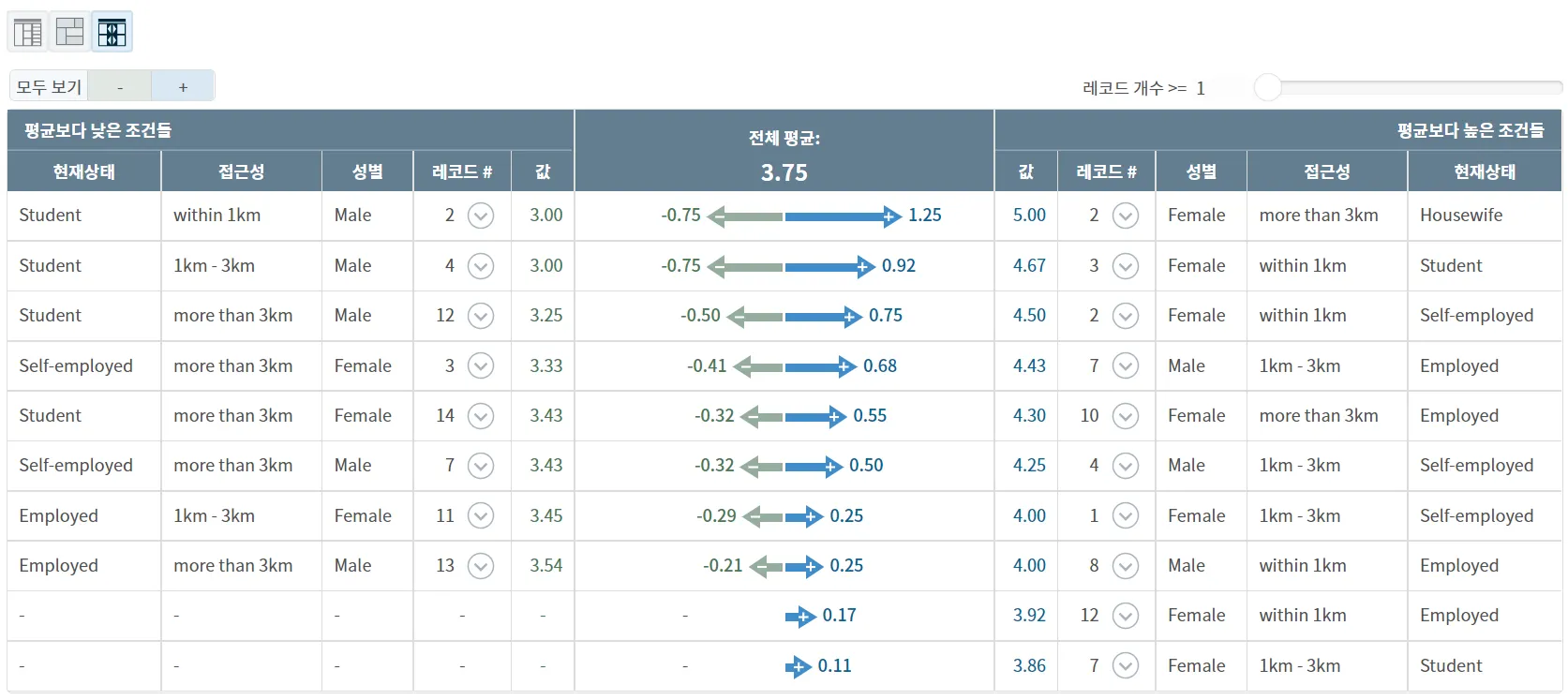
현재상태, 접근성, 성별 세 개의 변수의 조합으로 서비스 점수(만족도) 드릴다운한 결과
위에서 성별로 구분하지 않고 현재상태, 접근성 두 개 관점의 조합으로만 비교한 경우 현재상태가 Housewife이고 접근성이 more than 3km인 집단의 만족도가 가장 높았던 건 여자의 영향이 컸다는 걸 발견할 수 있었습니다.
세개의 조합으로 비교한 경우,
남자는
•
현재상태가 Employed이고 접근성이 1km-3km인 남자들이 제일 만족했고
•
그 다음으로 현재상태가 Self-Employed이고 접근성이 1km-3km인 남자들이 만족했다.
관계분석: Driver (통계적으로 유의미한 요인들)
이번엔 관계분석 메뉴를 통해 [서비스 점수] 문항과 나머지 19 문항들 사이에 회귀분석을 수행해 보겠습니다.
레시피
요인 분석에서, 차이를 가져온 요인을 분석하고자 하는 수치형 KPI(서비스점수)를 선택하고 [분석]을 클릭합니다.
HeartCount가 자동으로 가공하여 추가한 변수들을 제외하고 원본 엑셀에 담긴 149개 변수만 사용하여 회귀분석을 하려면, 변수 Filtering 하는 상단 메뉴의 톱니 아이콘을 클릭한 후 “파생 변수 포함” 상자를 uncheck하시면 됩니다.
분석 결과 해석
•
개별변수의 중요도에 따른 회귀분석 결과 순위를 보면 Small Multiples 화면에서 살펴본 상관관계의 크기 순서와 동일하게 나오는 걸 확인할 수 있습니다. 이건 개별 독립변수와 종속변수 사이의 관계를 분석하는 단순회귀분석인 경우 회귀분석 결과의 중요도인 결정계수(R²)가 수학적으로 상관계수(r)를 제곱한 값이라 그렇습니다. (*. 에너지 레벨의 상관계수인 0.6를 제곱하면, 0.36)
•
•
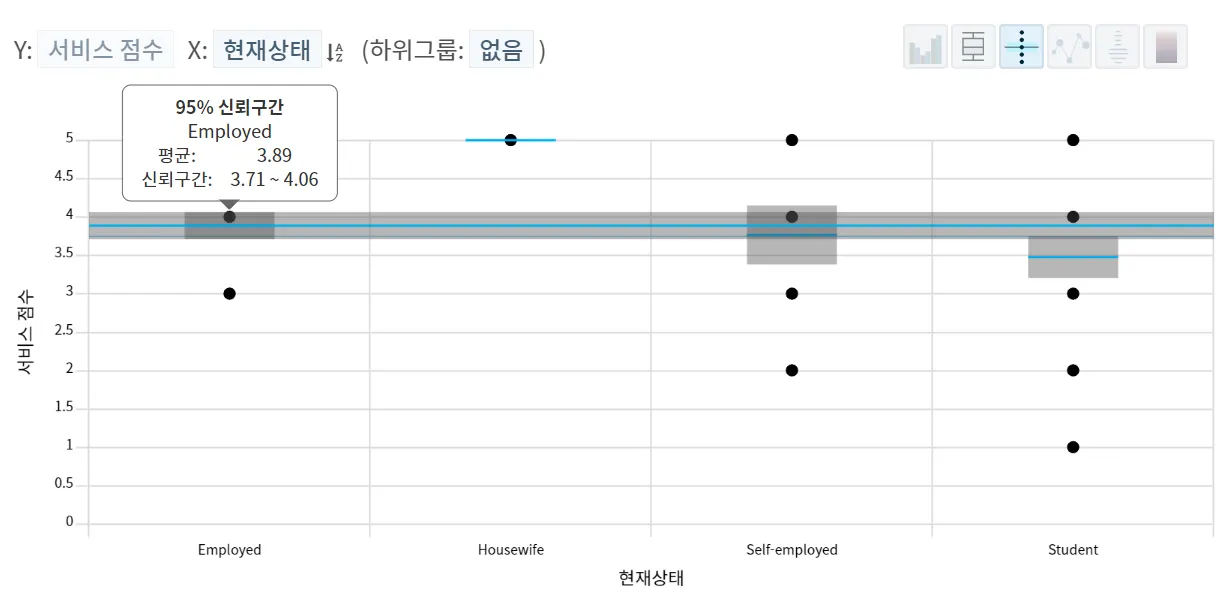
하지만, 현재상태나 접근성은 관계분석 결과 테이블에 나오지 않았습니다. 현재상태나 접근성에 따른 만족도 점수의 차이가 통계적으로 유의미하지 않기 때문이죠.
통계적 유의미성에 대해 간단히 집고 넘어가자면, 집단 내(Housewife이면서 접근성이 more 3km인 집단) 만족도 차이보다 집단 간 차이가 커야 통계적으로 유의미한 차이가 존재한다고 주장할 수 있는데 아래 그림처럼 개별 집단별로 평균점수는 차이가 나지만 95% 신뢰구간 평균 점수를 비교하면 신뢰구간이 서로 겹쳐서 집단 간 차이가 통계적으로 의미없다고 판단되었기 때문입니다.
통계적으로 유의미한 것(Statistical Significance)보다는 실용적 관점에서 유의미한 것(Practical Significance)이 회사를 이롭게 하자는 취지에서 데이터를 분석하는 현업 입장에서 더 중요합니다.
Micro-Segmentation: 양극단을 비교하는 아주 좋은 습관
마이크로세그멘테이션은 하트카운트 자체 의사결정트리 알고리즘을 이용한 기능으로, 유사한 특성이나 행동을 보이는 집단이 밀집해 있는 세그먼트를 찾는다고 해서 Micro-Segmentation라는 이름이 지어졌습니다.
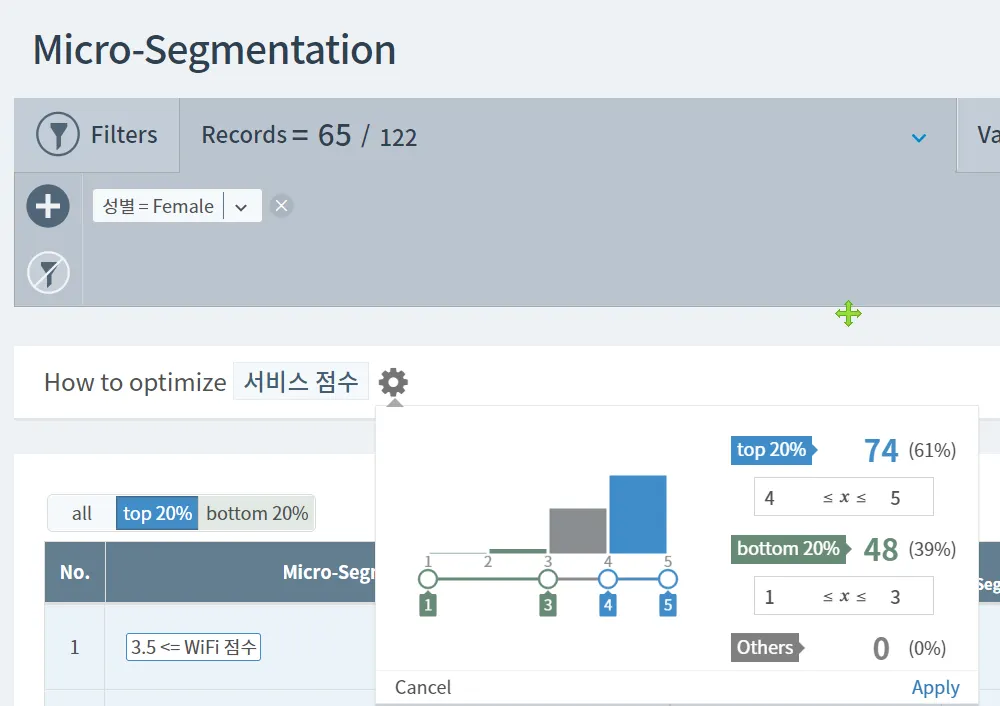
‘서비스점수’에 5점이라고 답변한 확실히 서비스를 만족한 집단(30명)과 1~2점이라고 답변한 확실히 불만족한 집단(27명)을 타겟으로 정하여 두 집단(세그먼트)을 구분하는 논리적 규칙을 찾아보려고 합니다.
레시피

•
우선 하트카운트의 공통 기능, 필터링 기능을 이용해서 아래와 같이 분석 조건을 설정하였습니다.
◦
성별의 경우 남자만 분석
◦
분석에 사용할 총 19개 변수 중 서비스 점수(만족도)의 원인이라기 보다는 결과에 가까운 비즈니스 활용 및 사적 만남 이용가능 점수와 지속이용 여부는 제외
•
최적화 규칙을 찾을 변수로 ‘서비스 점수(만족도)’를 선택하고 상세 설정으로 직접 타겟을 커스텀했습니다.
◦
기본 디폴트값: 수치형 변수의 경우, 상위 20% 그룹 vs 하위 20% 그룹의 분류 규칙 분석
분석 결과 해석
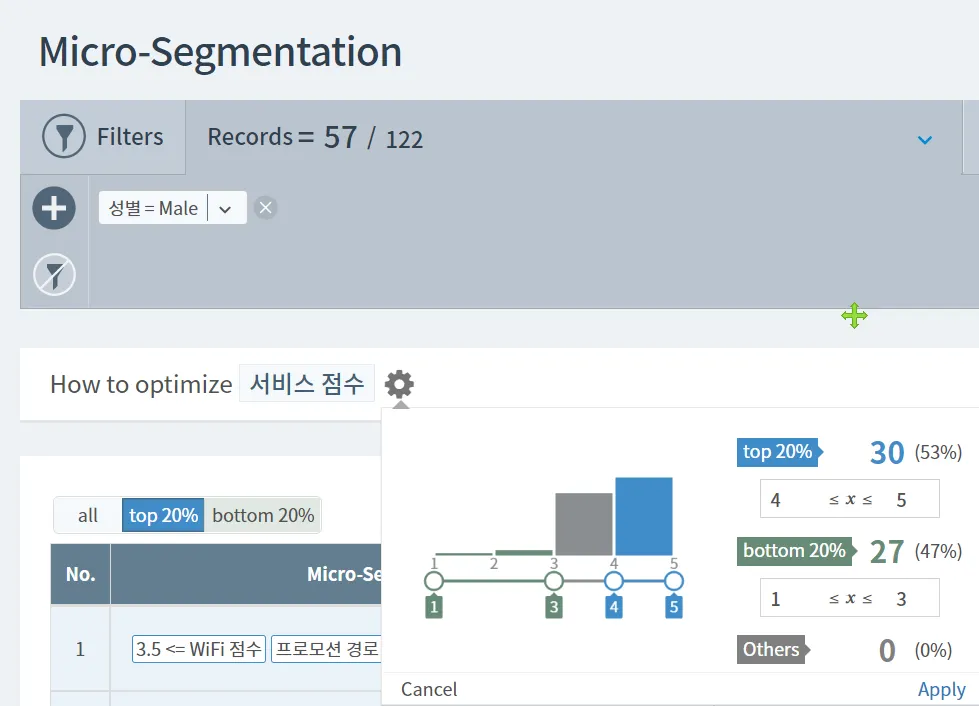
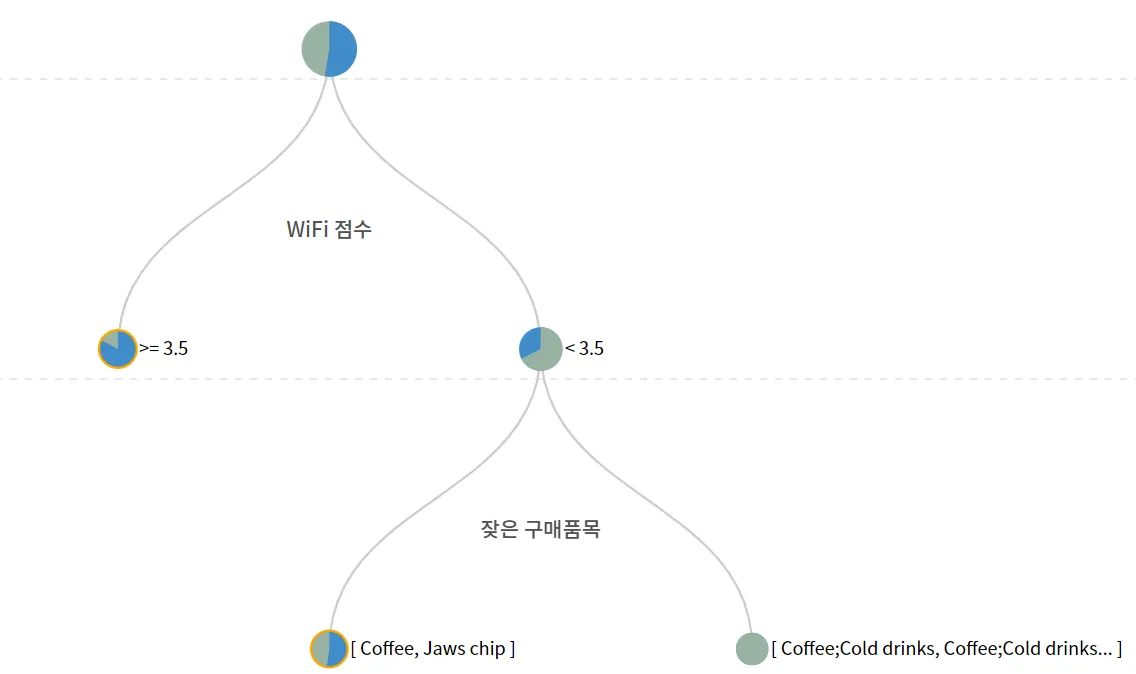
의사결정 트리 결과를 보면,
•
남자의 경우 WiFi 점수가 많으면(4점 이상 답변) 무조건 높은 서비스 점수(만족도) : 4.17점
•
WiFi 점수가 아주 많지는 않지만(3점 이하 답변) 잦은 구매품목이 Coffee, Jaws chip (2점 이하) 서비스 점수(만족도) : 3.52점
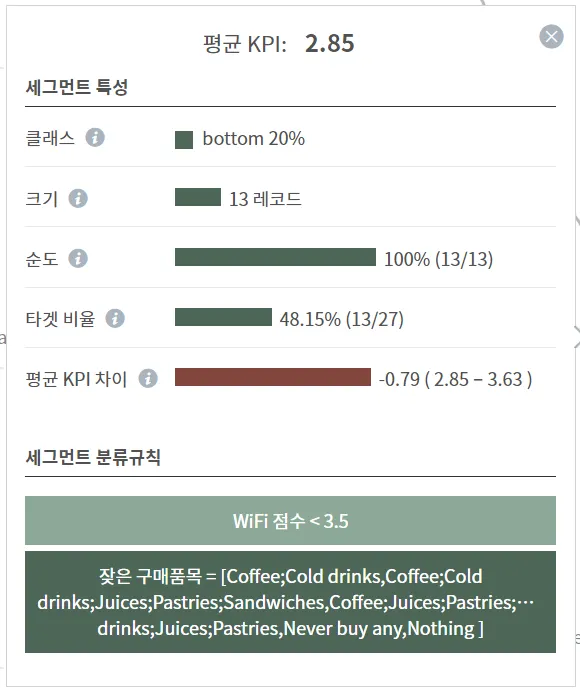
•
WiFi 점수도 적은데(3점 이하 답변) 잦은 구매품목이 Coffee;Cold drinks(3점 이상) 낮은 서비스 점수(만족도) : 2.85점
아까 현재상태 주제로 돌아가면 현재상태가 Housewife 이면 WiFi가 많은 것의 직접적인 결과로 볼 수 있습니다. 남자의 경우 WiFi 점수가 서비스 점수와 현재상태에 둘 다에 영향을 주어 현재상태와 서비스 점수 사이에 관계가 발견되었을 수도 있겠습니다.
여자도 같은 식으로 서비스 점수(만족도) 높은 집단과 서비스 점수(만족도) 낮은 집단이 높은 순도로 밀집해 있는 세그먼트의 조건을 찾아보았습니다.
여자의 경우
•
프로모션 경로에 대해 In Store displays, Social Media, Emails, Deal sites이면(2점 이하 답변) 무조건 서비스 만족: 5점
•
프로모션 경로에 대해 Emails, Never her, Social Media이면 완전 서비스 불만족 : 3.37점

