
How? KPIを最適化するパターンを見つける
セグメンテーション機能により、任意のKPIを最適化するための実行可能なルールを発見することができます。
ここで言うKPIとは、分析の目標となる変数を意味します。つまり、必ずしもKPIとして登録されていなくても、任意の変数をセグメンテーションの目標変数として設定することができます。1. セグメンテーションとは?
人は常に自分の業務を最適化することを考えています。
ある企業のマーケティング担当者がマーケティングキャンペーンを展開する際に、このキャンペーンに積極的に反応するグループ/反応しないグループを区別するルールを見つけたとします。その場合、その企業は今後反応する可能性の高いグループのみを選んで効率的にターゲティングを行うことができるようになります。
このように、自分が望む目標を最適化する方法を自動的に見つけ出すことができたらどうでしょうか?
HEARTCOUNTはKPIを最適化することができるルールを自動的に発見し、どのような条件で実行するのが最適なのかを推奨するセグメンテーション機能を提供しています。セグメンテーション機能は、決定木(decision tree)、つまり、2つの異なるグループを分類する(classify)ためのルールを作成する代表的な機械学習アルゴリズムを用います。
決定木とは?
2. セグメンテーションを活用する
以下の例は、スーパーストアの利益を最適化するルールを自動的に見つけるプロセスの例です。このように、特定のKPIの最適化ルールをセグメンテーション機能を利用して見つけ出す方法を見てみましょう。
(1) 最適化ルールを探索
1.
まず、最適化したい変数を選択します(例では「利益(Profit)」を変数として設定しています)。そして、右の分析するボタンをクリックすると、top (上位) 20% と bottom (下位) 20% を分類するルールが自動的にテーブルに提示されます。
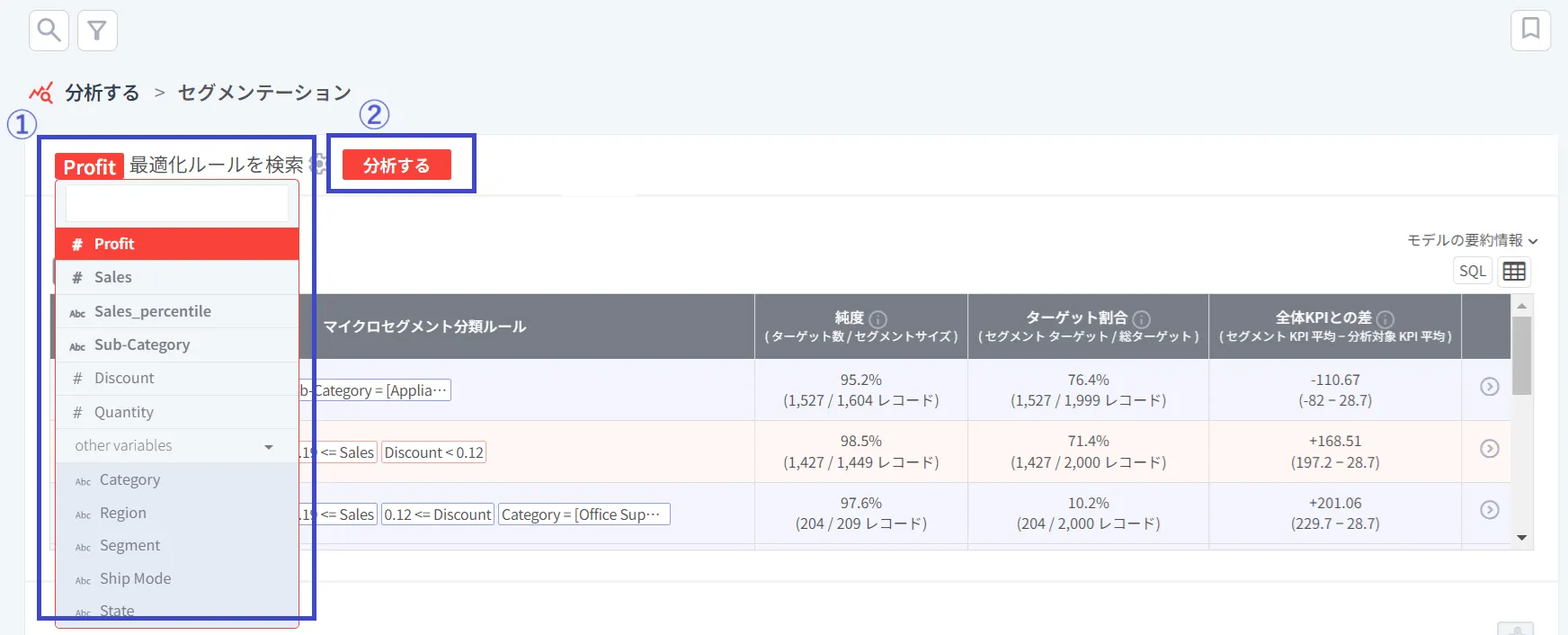 セグメンテーションは目的変数が数値型変数の場合は自動的に上位/下位グループを分けて「最適化ルール」を、カテゴリ型変数の場合は2つのグループの「分類ルール」を探します。カテゴリ型変数は以下のように設定可能です。
セグメンテーションは目的変数が数値型変数の場合は自動的に上位/下位グループを分けて「最適化ルール」を、カテゴリ型変数の場合は2つのグループの「分類ルール」を探します。カテゴリ型変数は以下のように設定可能です。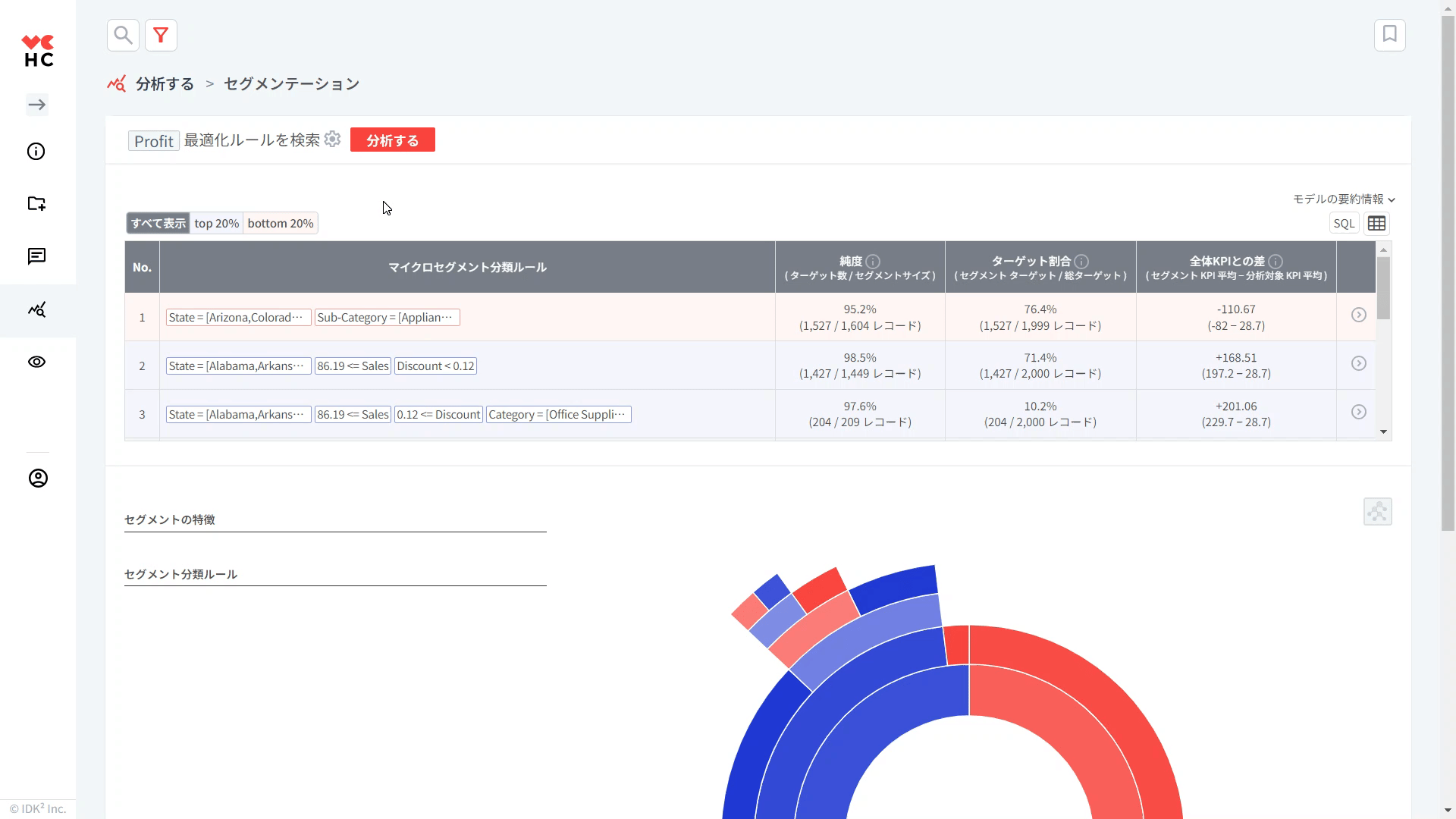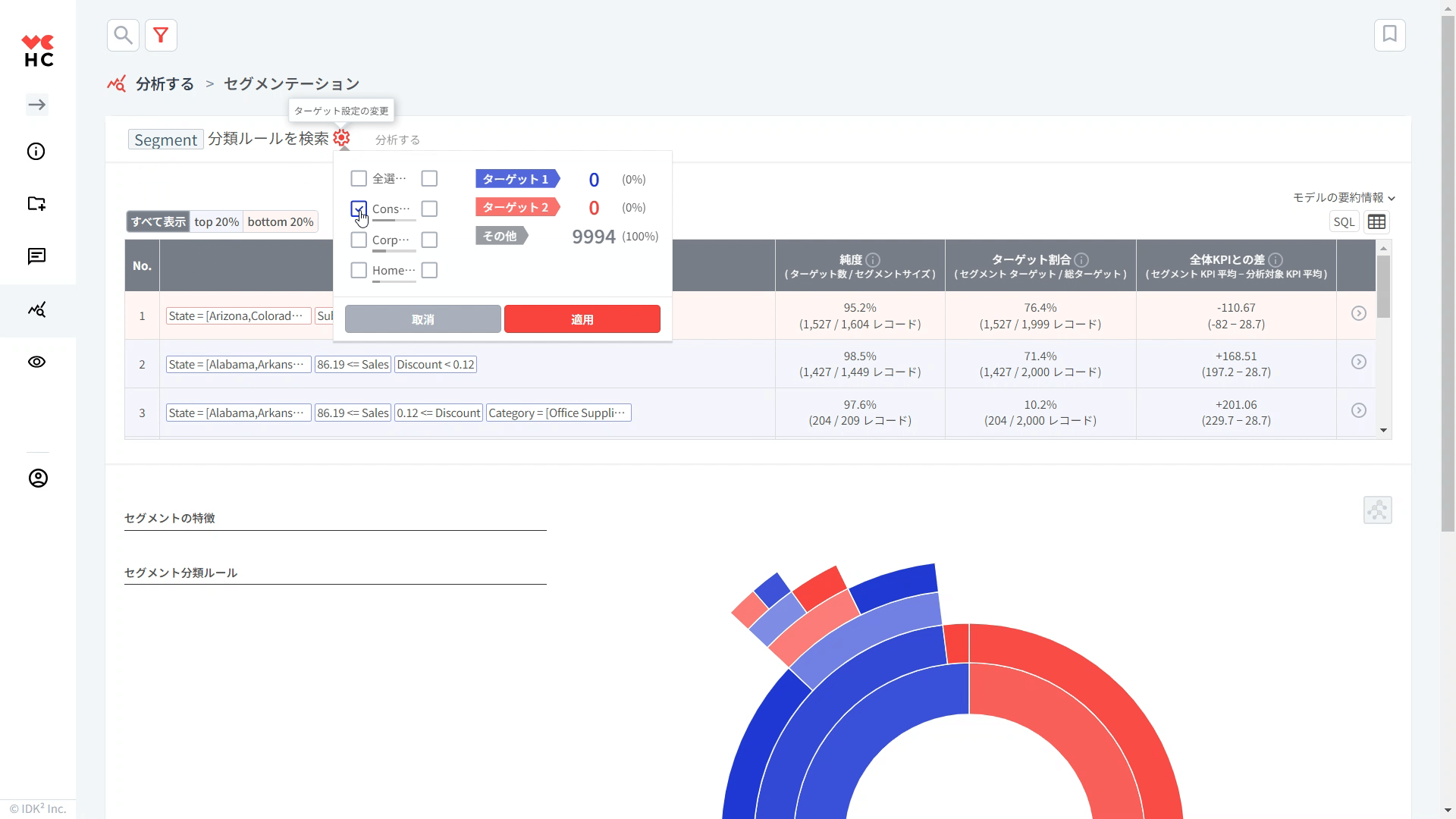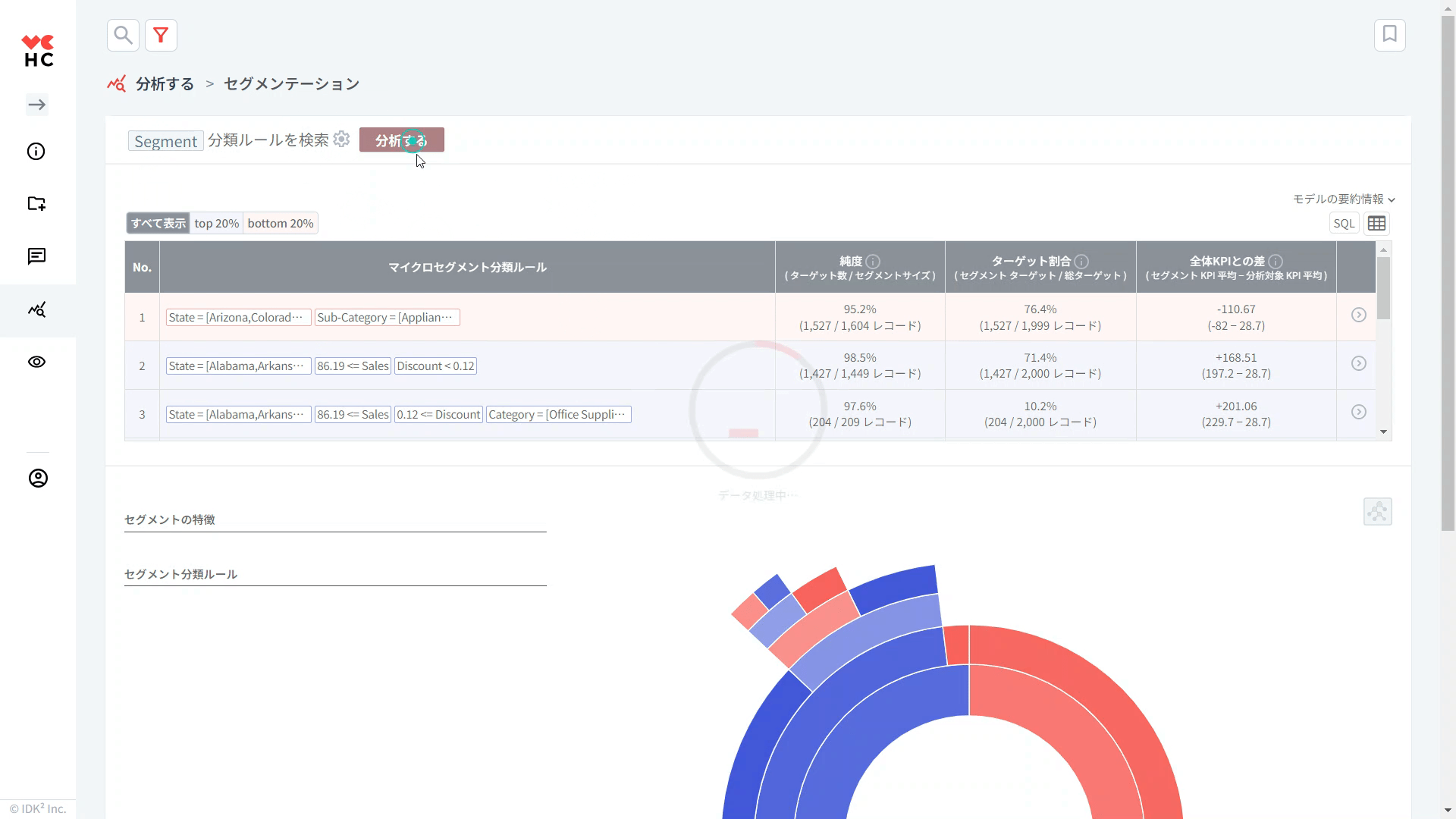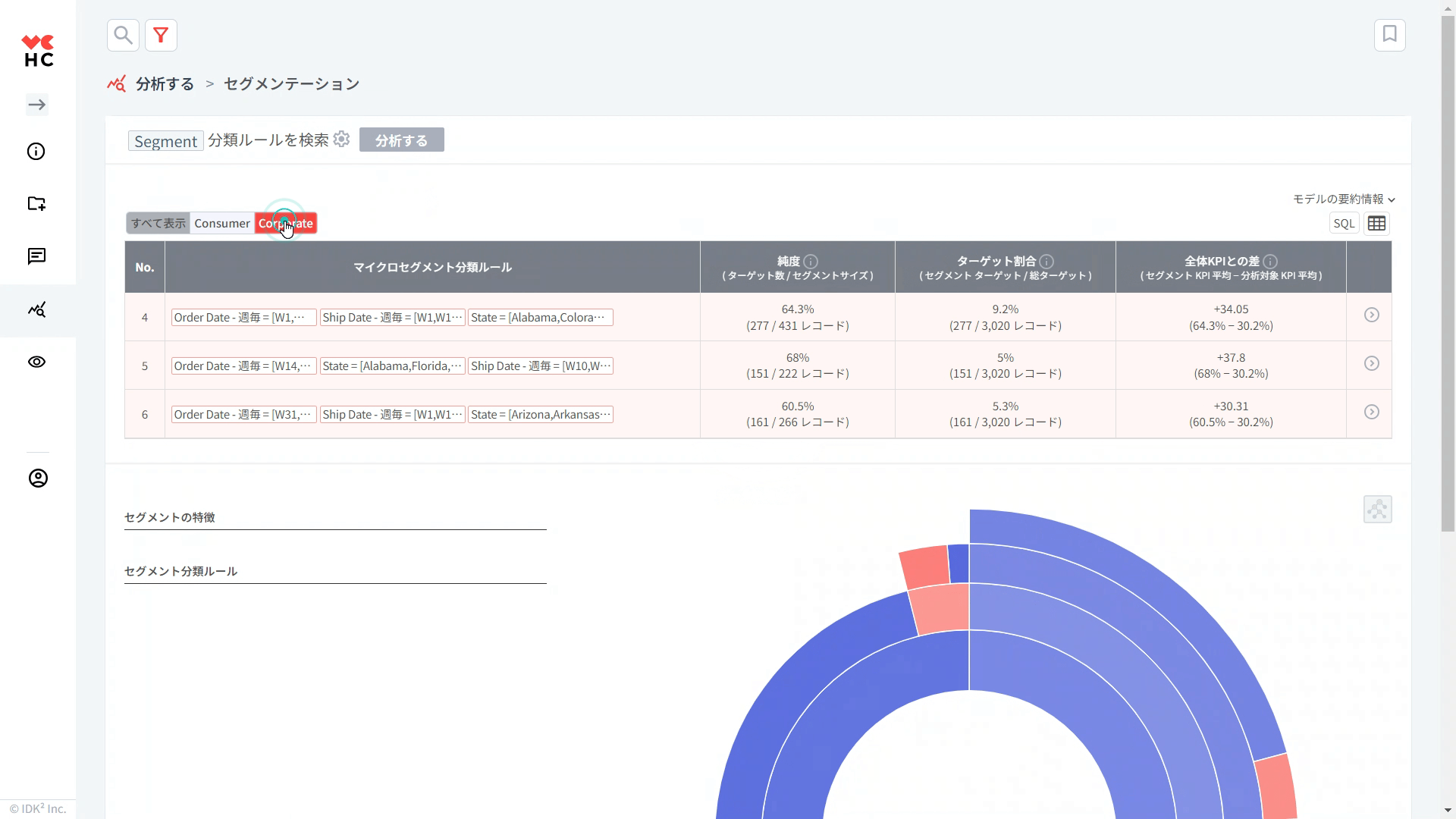
2.
(オプション) セグメンテーションの基本原則は、2つのターゲットグループを区別して、その2つのグループを分類する「ルール」を見つけることです。 ユーザーは、デフォルトで提示される top (上位) 20% / bottom (下位) 20% のグループ以外にも、独自のターゲットグループを直接設定することができます。 歯車をクリックして、分類ルールを作成したい2つのグループの範囲をマウスで直接調整したり、数値を直接入力することもできます。
をクリックして、分類ルールを作成したい2つのグループの範囲をマウスで直接調整したり、数値を直接入力することもできます。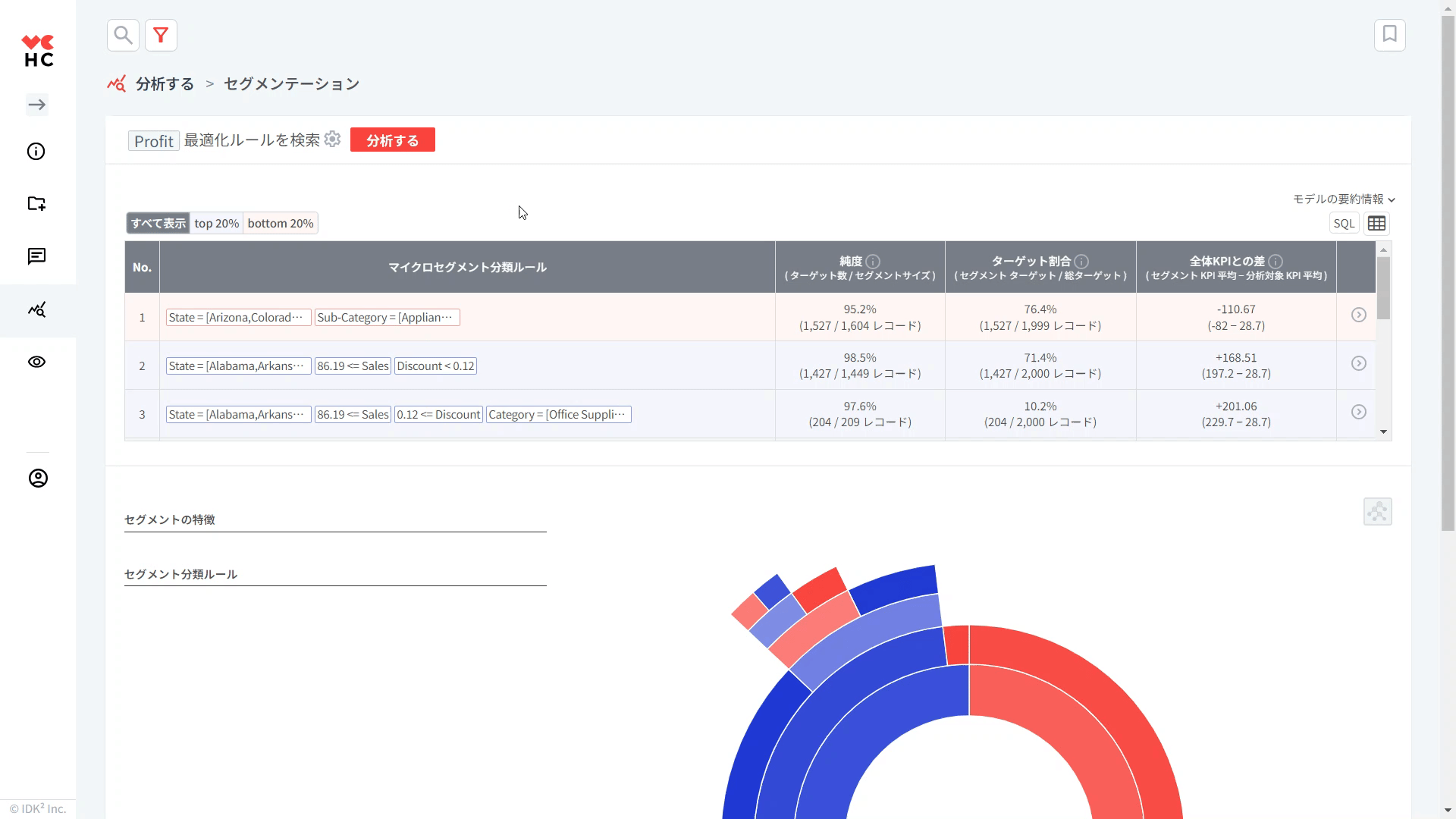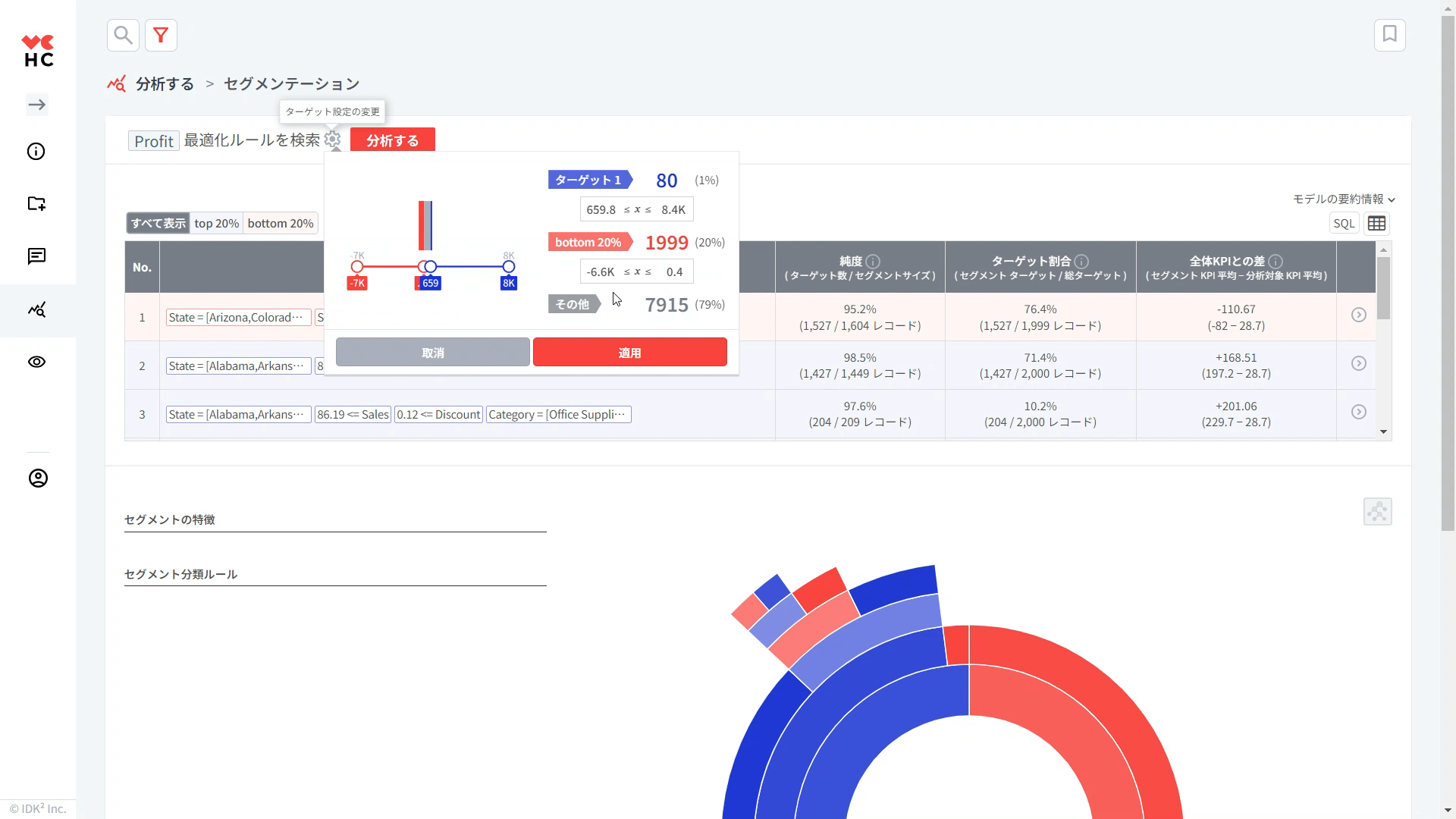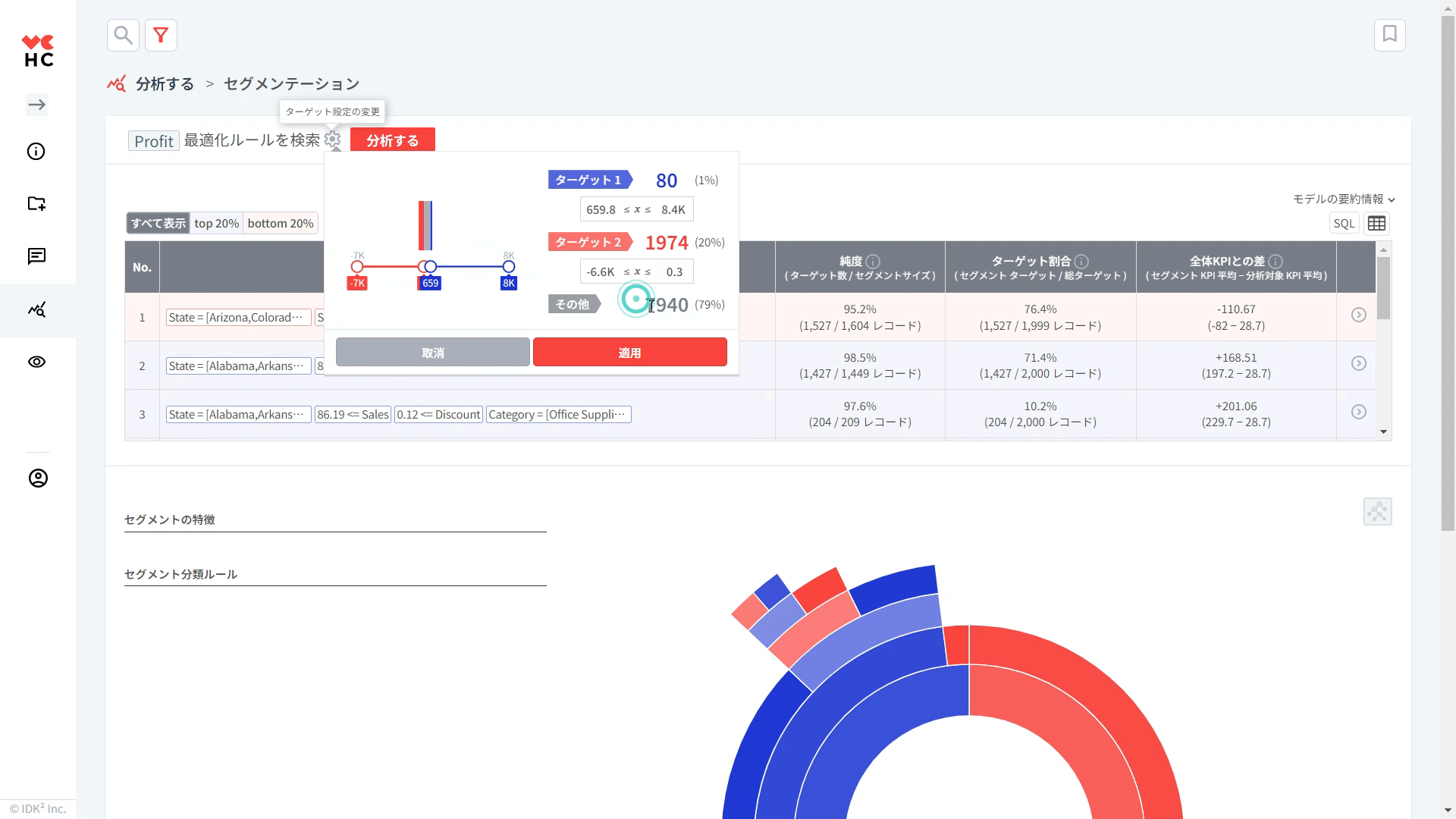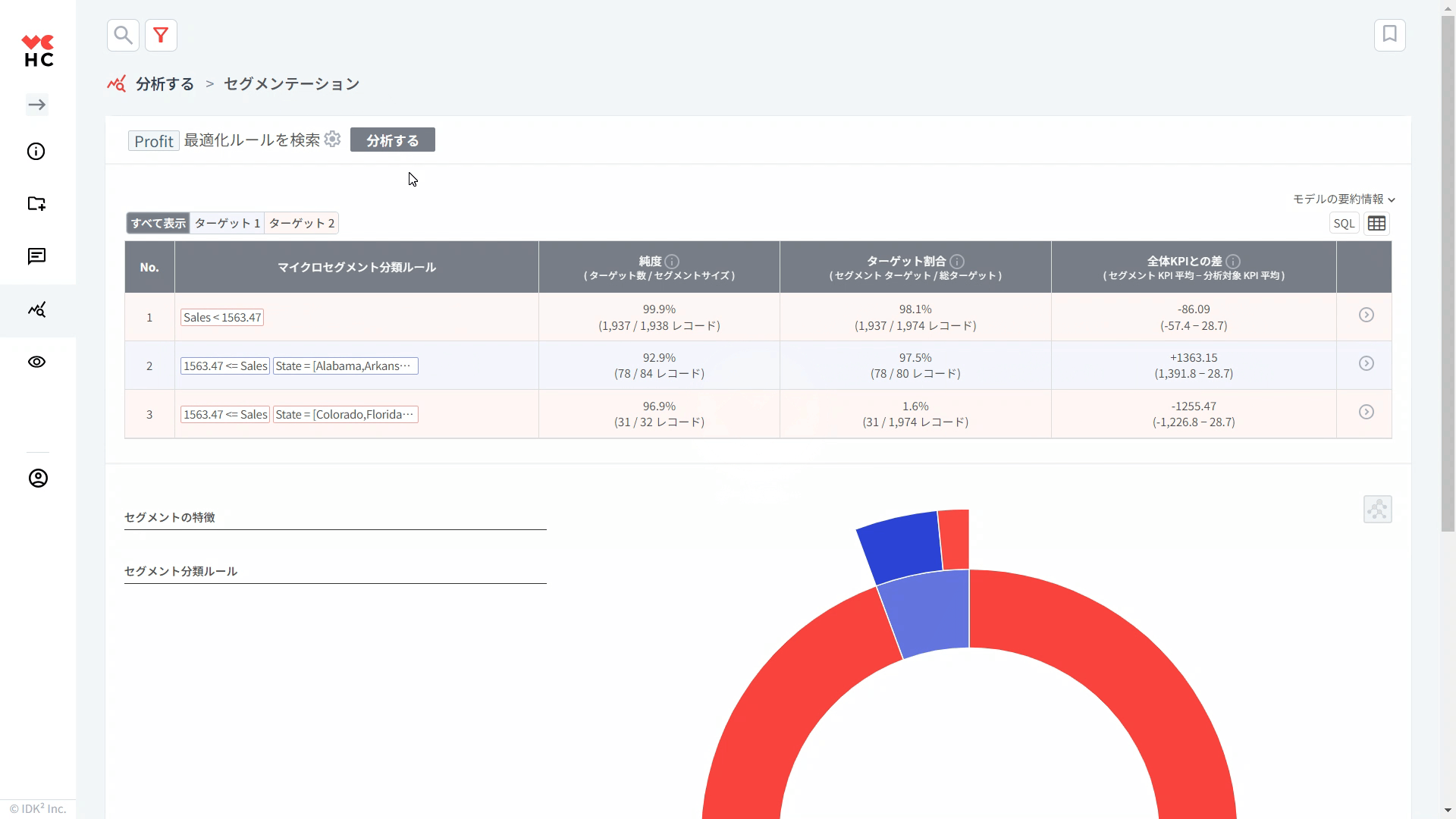
3.
テーブルの各項目を詳しく見てみましょう。なお、テーブルのルールは、ターゲット比率が高い順に降順に並び替えられています。
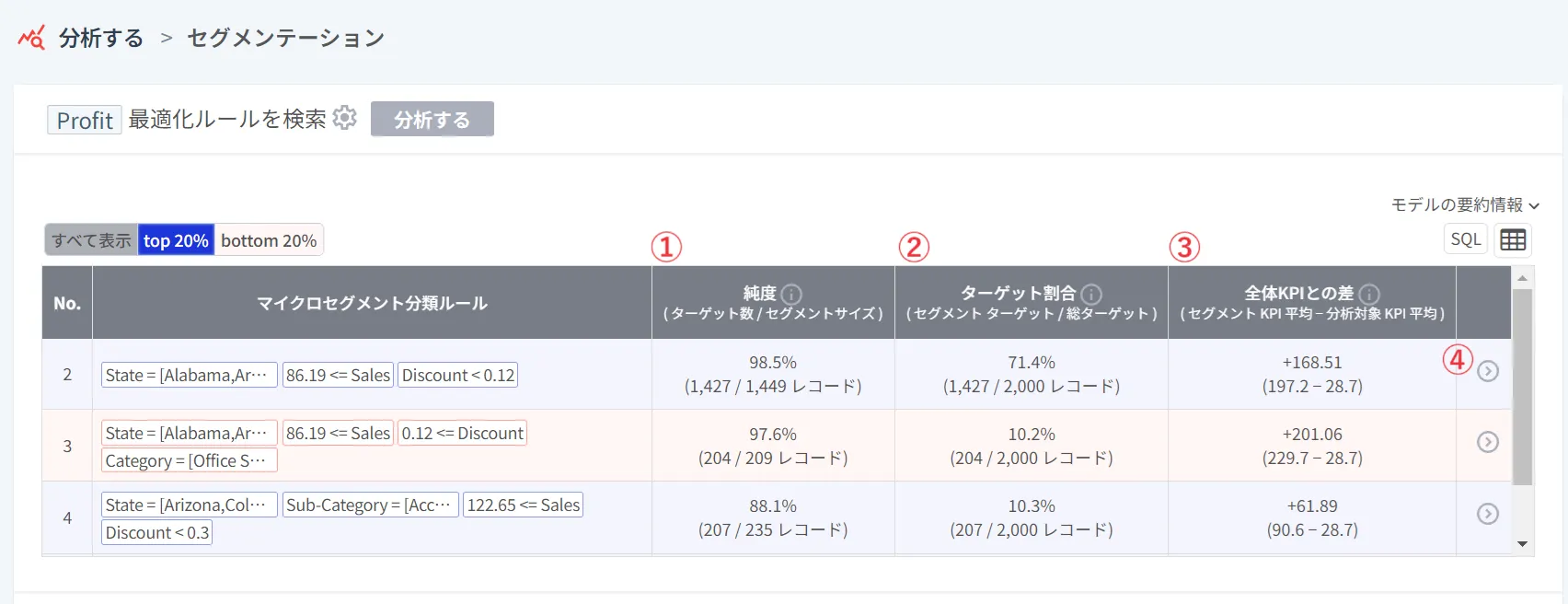
① 純度: 分類ルールが適用されるグループ内でのターゲットグループが占める割合。その分類ルールがどのくらい正確であるかを知ることができます。
(例. 「割引率が12%未満の全体グループ」の中で「割引率が12%未満+利益が上位20%であるグループ」が占める割合)
② ターゲット比率: ターゲットグループのうちルールが適用されるグループが占める割合。
(例. 「利益が上位20%である全体グループ」の中で「割引率が12%未満のグループ」が占める割合)
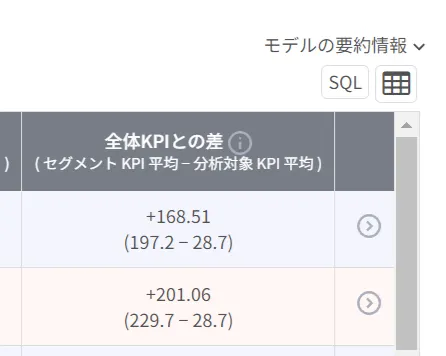
③ 全体KPIとの差: 個々の分類ルールが適用されるセグメントとターゲットに設定した変数の全体平均との差。
④ >(スマートサーチ): 各行の右側にある>をクリックすると、各ルールに該当する個々のレコード(データ)をより詳細に探索することができる「スマートサーチ」メニューに移動します。
4.
予測モデルの概要情報も確認してください。
以下の赤枠で示した部分の矢印∨をクリックしてください。
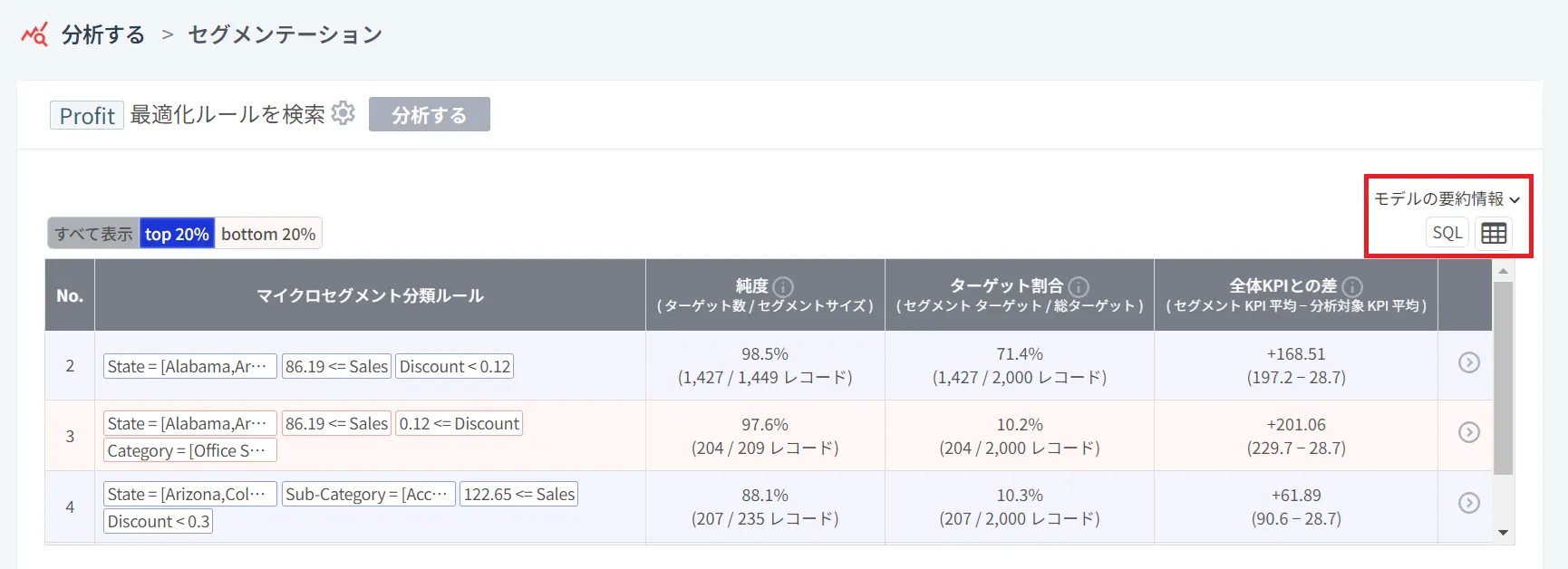
デフォルトで提示される2つのターゲットグループ、またはユーザーが直接設定したターゲットグループの概要情報を確認することができます。
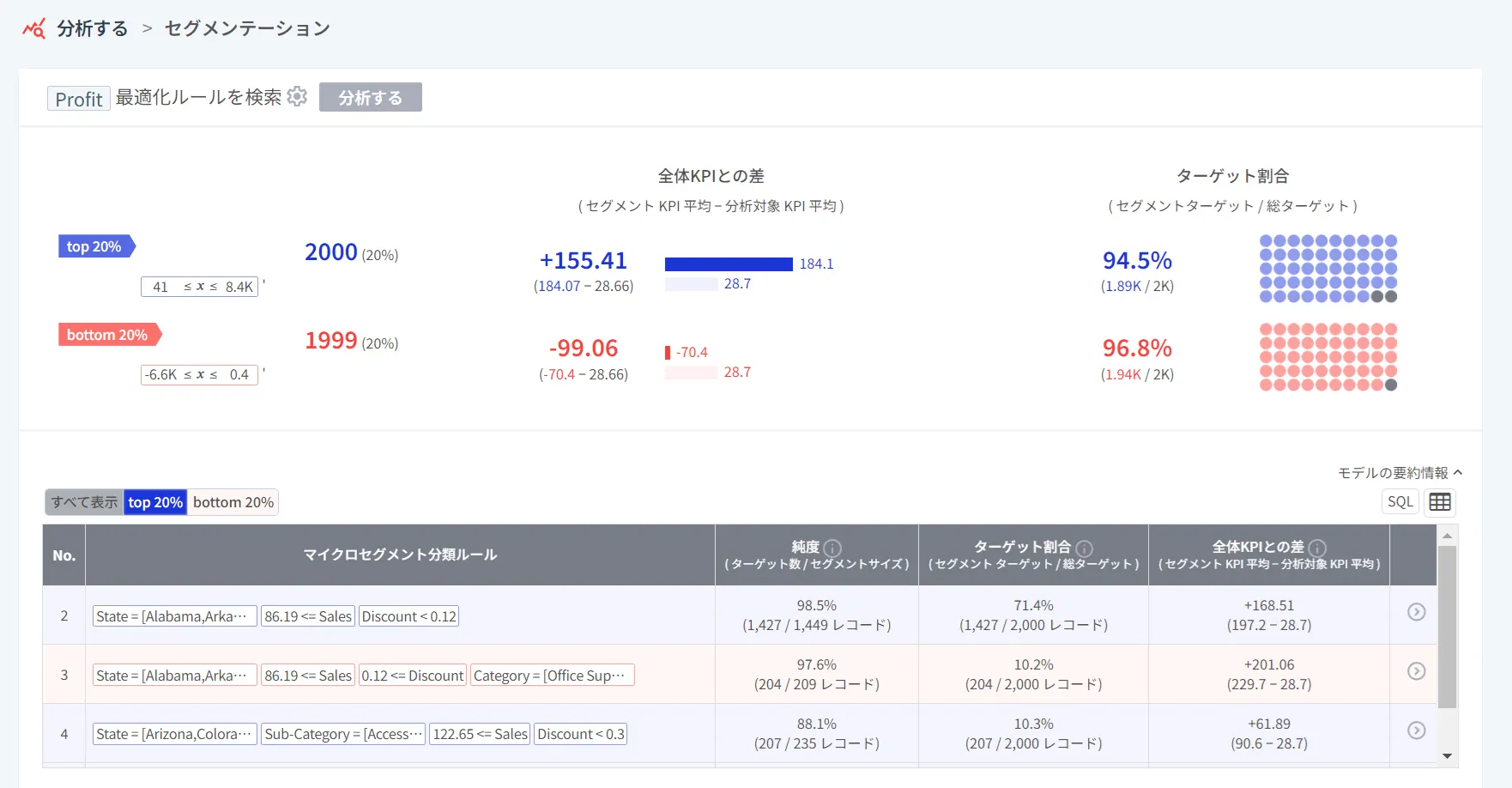 要約情報のターゲット比率は、上記で説明した各セグメントのターゲット比率とは異なります。
分母の全体ターゲットは同じですが、分子であるセグメントのターゲット数が異なるためです。要約情報では、導出されたすべてのルールのセグメントを合計し、総ターゲット数で割ります。上の例で、利益が「top (上位) 20%」のグループの場合、合計の件数が2000のうち、導出された全てのセグメントの件数は1.89Kです。つまり、利益が 「top (上位) 20%」であるグループのうち94.5%が注目すべきルールを持っているという意味になります。
要約情報のターゲット比率は、上記で説明した各セグメントのターゲット比率とは異なります。
分母の全体ターゲットは同じですが、分子であるセグメントのターゲット数が異なるためです。要約情報では、導出されたすべてのルールのセグメントを合計し、総ターゲット数で割ります。上の例で、利益が「top (上位) 20%」のグループの場合、合計の件数が2000のうち、導出された全てのセグメントの件数は1.89Kです。つまり、利益が 「top (上位) 20%」であるグループのうち94.5%が注目すべきルールを持っているという意味になります。(2) 視覚化グラフ
ユーザーがテーブルに提示されたルールをより理解しやすくするために、以下の画面のように視覚化されたグラフを用いて最適化ルールを詳しく把握することができます。
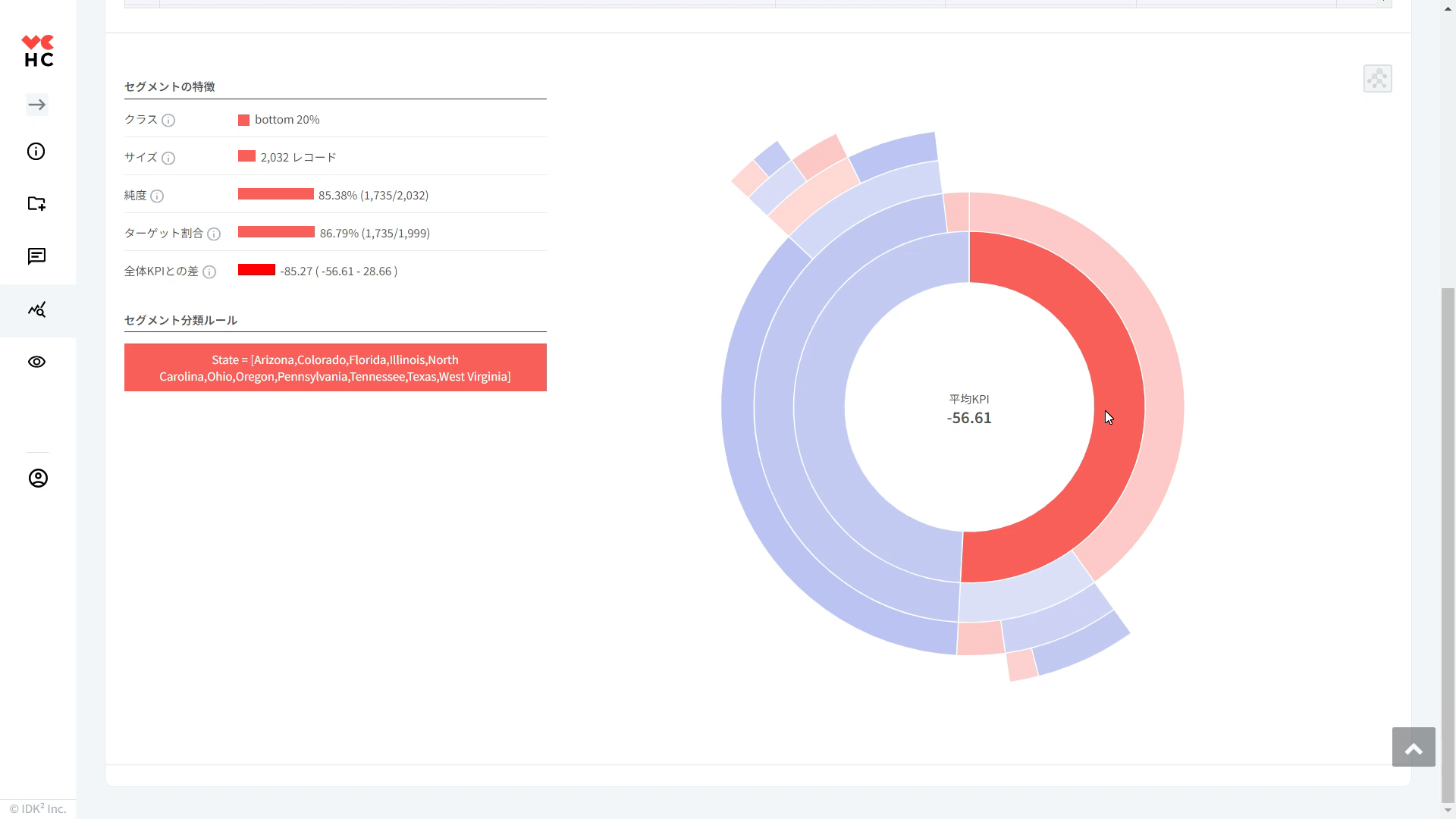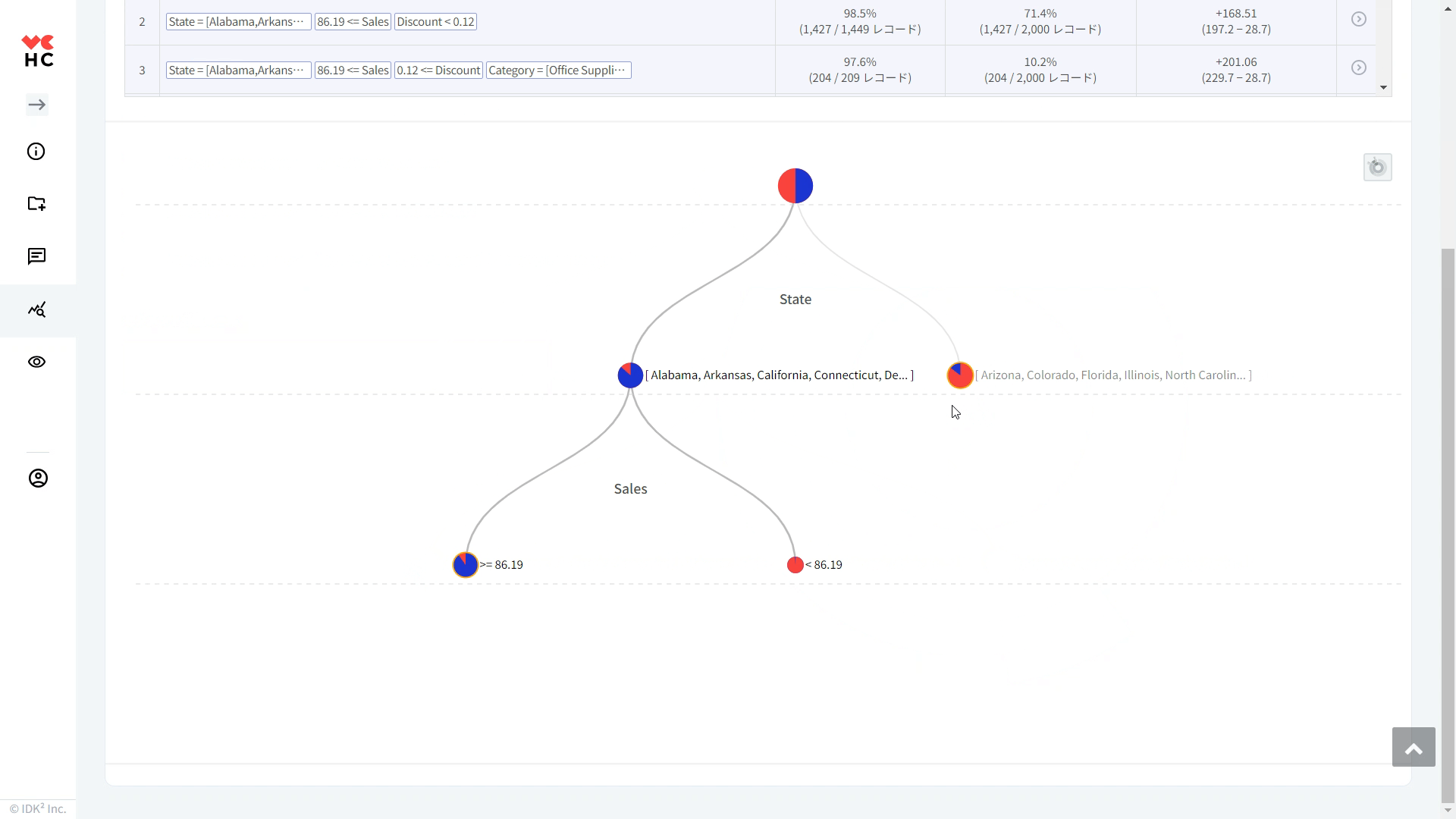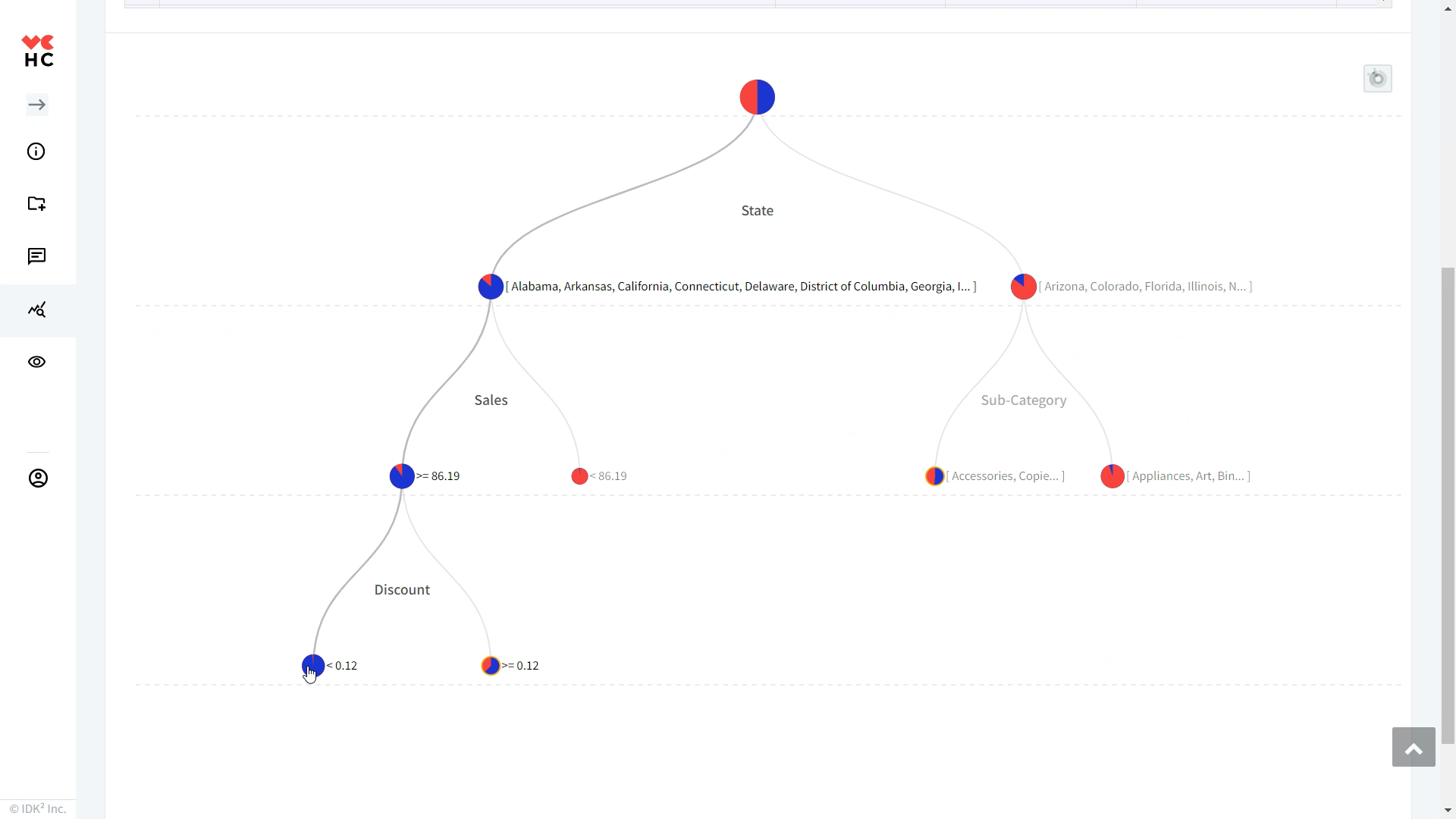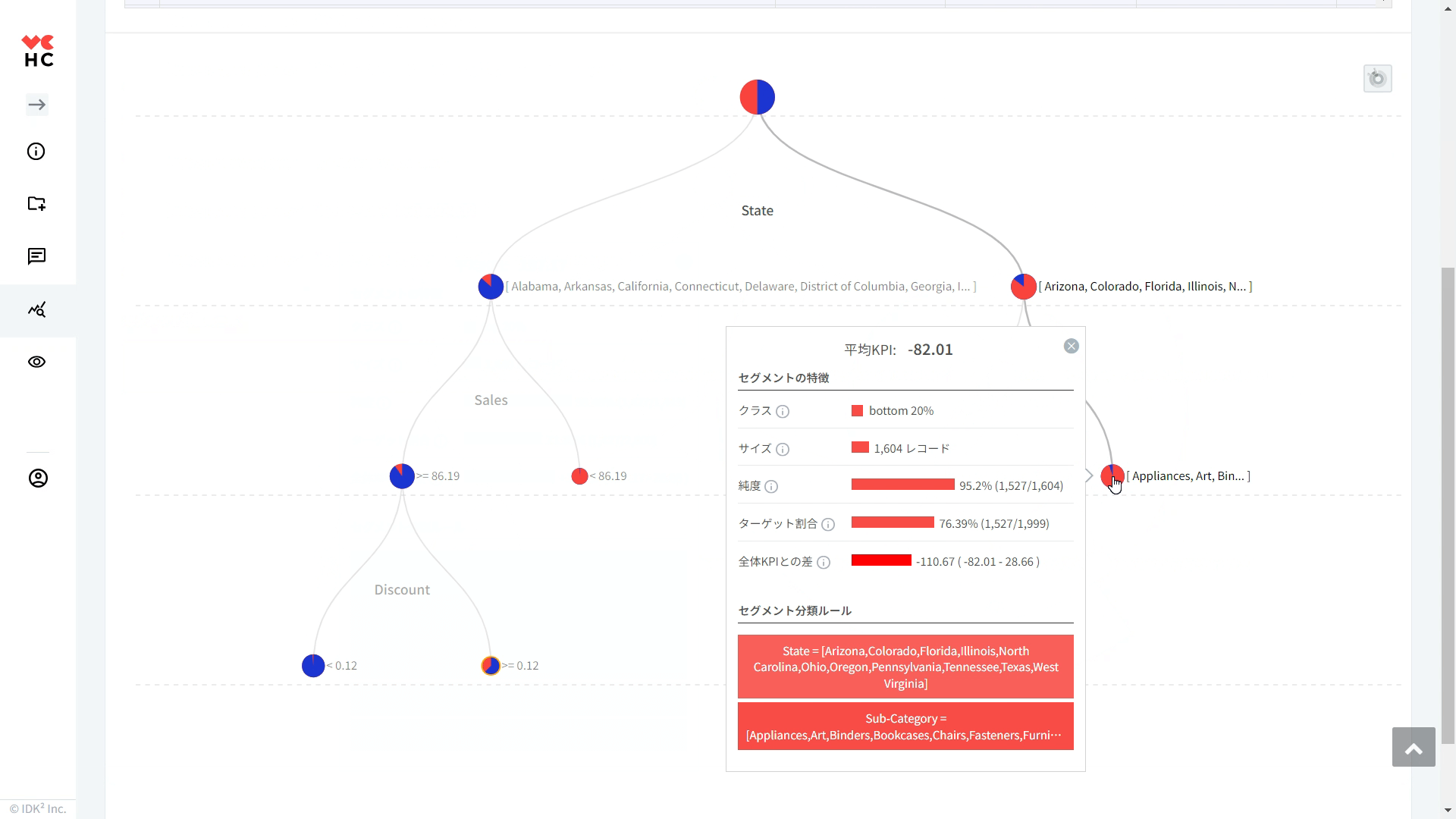
以下の画面は「利益最適化」を基準に導出されたルールのうち、テーブルの一番上に表示されたルール、特定のState & 86.19<=Sales & Discount<0.12の条件に該当する視覚化グラフ/セグメントの特性を示す図です。
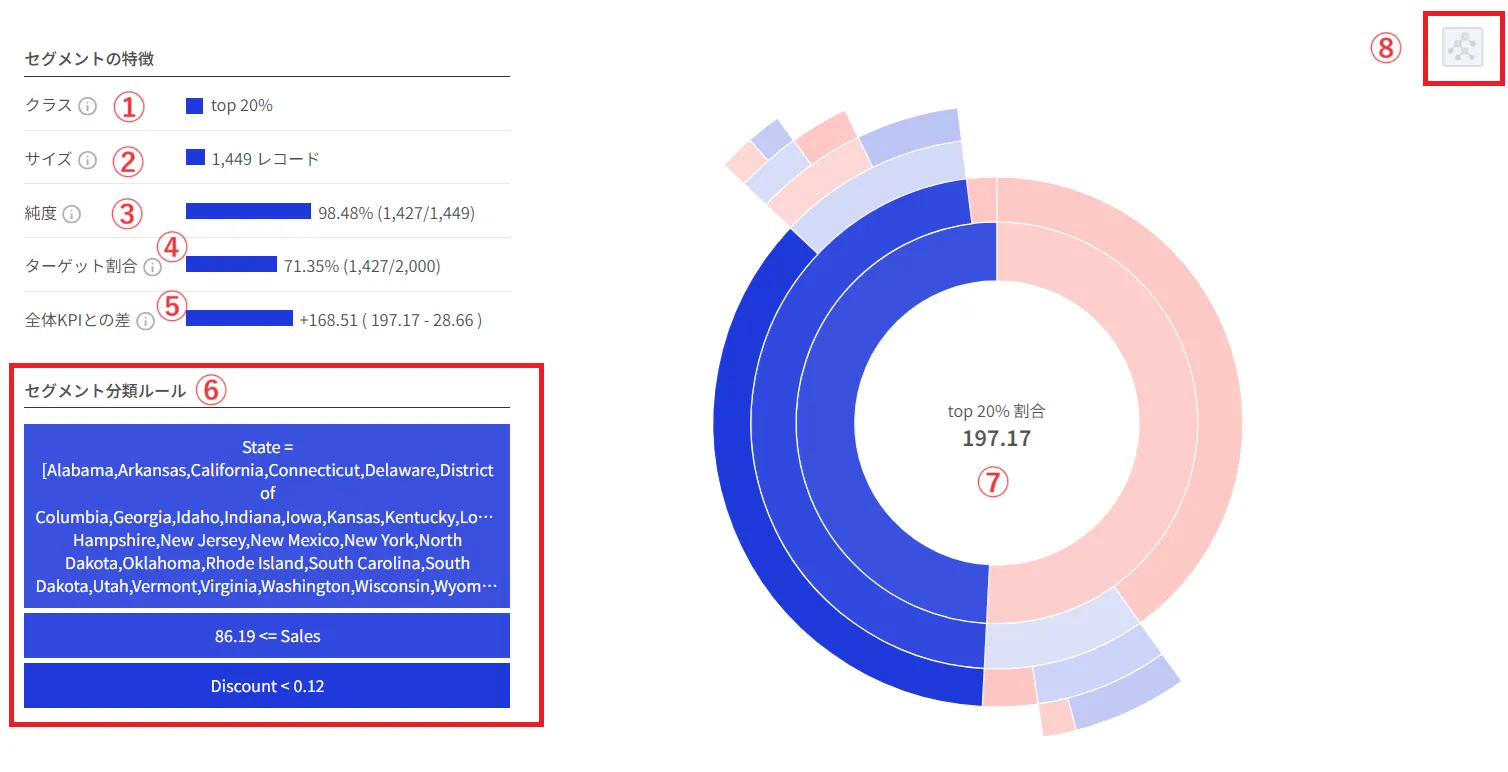
①クラス: 該当条件である特定のState & 86.19<=Sales & Discount<0.12に分類されるレコードの多くが利益 top (上位) 20% に該当することを意味します。
②サイズ: 該当条件を満たすレコード件数(1,449レコード)
③純度: 該当条件を満たすセグメントサイズ1,449件のうち1,427件(98.48%)が利益 top (上位) 20% に該当することを意味します。純度が高ければ高いほど、分析結果に対する信頼性も高くなります。簡単に言えば、その分類ルールがどれだけ正確に予測するかを示す尺度です。
④ターゲット割合: 利益 top (上位) 20%に属する総レコード件数(2,000件)のうち、1,427件(71.35%)が該当のセグメントに属することを意味します。(Recall/再現率とも呼ばれます)
⑤平均KPIとの差: 該当のセグメントに属するレコードでの平均KPIと分析対象全体の平均KPIとの差(全体での平均利益: +168.51、該当条件のレコードでの平均利益: +197.17、平均KPIとの差=+28.66)
⑥セグメント分類ルール: 上の画面(「利益最適化」を基準に導出されたルール一覧画面)の上段のテーブル中の最初の分類ルールを詳細に表示した内容です。
⑦視覚化グラフ: 導出された利益最適化条件をグラフで表現したものです。青色で鮮明に表示された領域が該当する分類ルールの領域です。
⑥決定木: アイコンをクリックすると、下図のように分類ルールがツリー形式で表示されます。
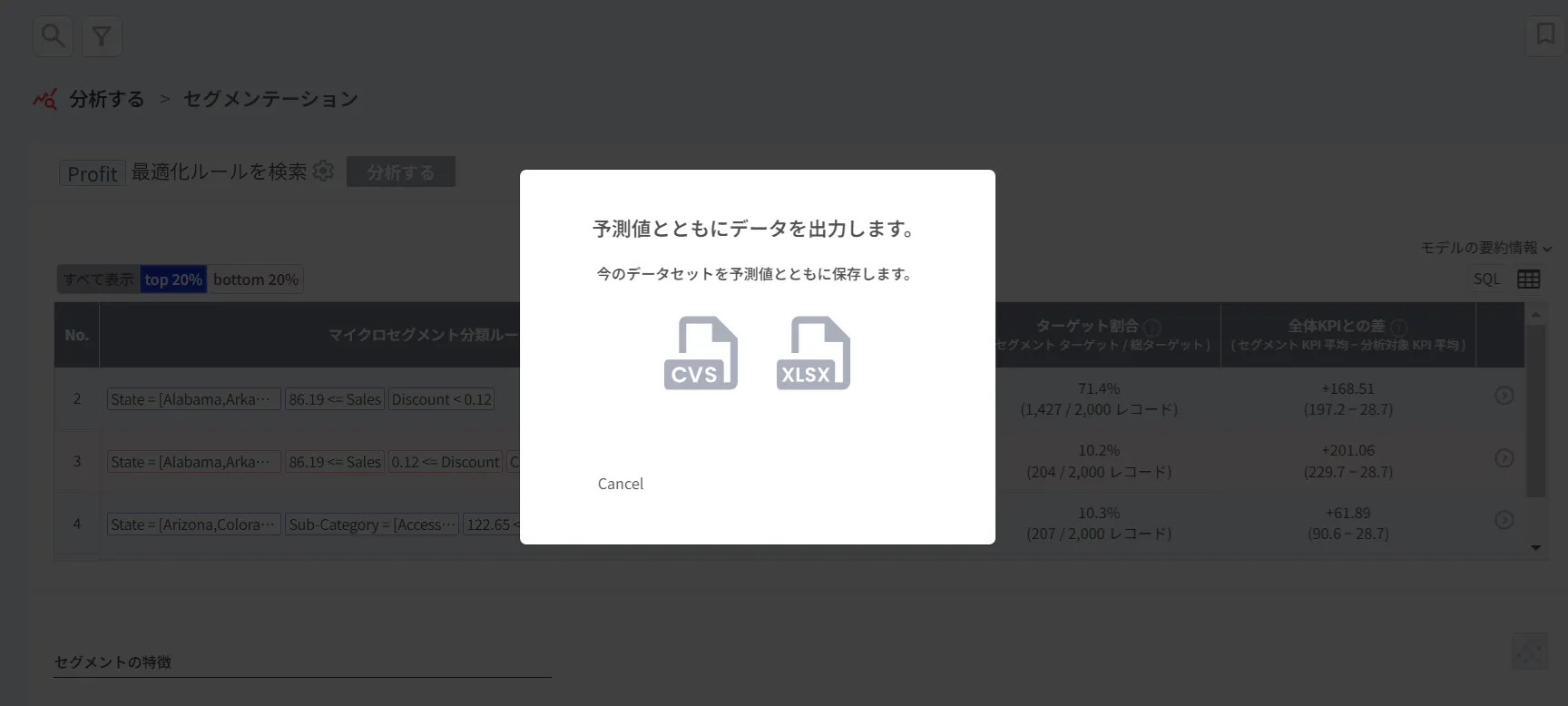
(3) ファイル出力
•
SQLをクリックすると予測モデルを以下のようなクエリで確認することができます。
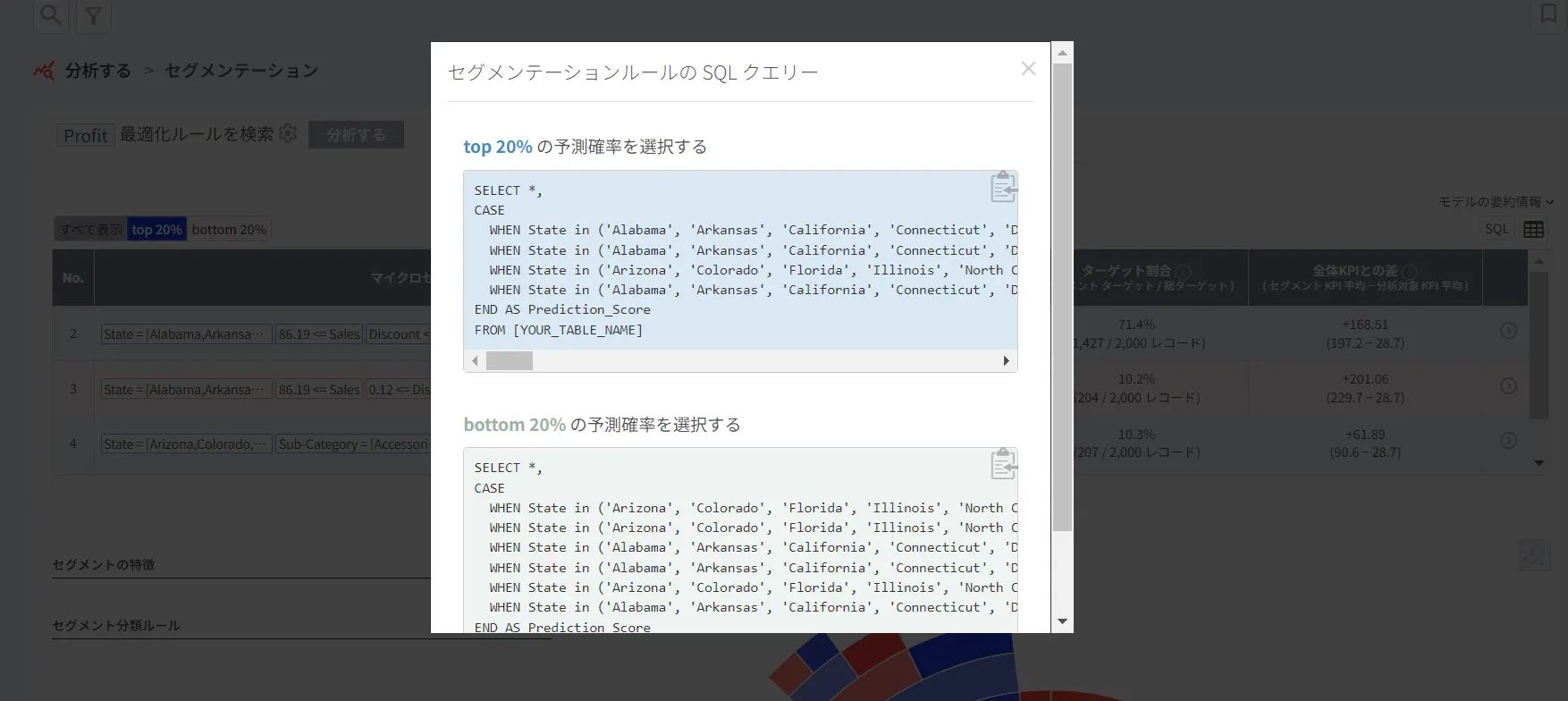
•
テーブルのアイコンをクリックすると予測モデルの結果をCSVファイルもしくはExcelファイル(.xlsx)として保存することができます。