
두 집단을 구분하는 특성 찾기 관련 시리즈
Intro: 두 집단을 데이터로 구분해보기

실무 현장에서, 두 집단을 구분짓는 주요 특성을 데이터에서 찾아야 하는 경우가 종종 있습니다. 인사부서에서 고성과자와 저성과자를 구분하는 주요 특성을 파악하고자 하는 경우, 운영부서에서 매출이 좋은 매장들과 그렇지 못한 매장들의 차이가 어디서 비롯되는지 이해하고자 하는 경우, 마케팅 부서에서 최근 캠페인에 반응한 사람들의 세그먼트 특성을 (반응하지 않은 사람들과 비교하여) 파악해야 하는 경우 등이 그렇습니다.
이번 글에서는 타이타닉호에 탑승한 사람 중 살아남은 사람과 죽은 사람을 구분하고자 할 때, 탑승자의 어떤 속성(변수)이 두 집단을 구분하는데 요긴한 변수인지 확인하는 방법에 대해 알아 보겠습니다.
아래 그림에서 생존자를 파랑색, 사망자를 노랑색으로 구분한 후 나이에 따른 각 집단의 분포를 시각화했다고 가정해 보겠습니다. 생존자 집단의 나이가 전체적으로 많은 것(파랑색 집단의 나이 분포가 오른쪽에 치우쳐 있음)을 쉽게 확인할 수 있고, 나이 변수가 두 집단을 구분하는데 유용할 수 있겠다고 짐작할 수 있습니다.
다만, 나이 말고도 성별, 탑승권의 종류 등 두 집단을 구분할 때 사용할 수 있는 속성(변수)이 많다고 할 때, 이런 속성들의 상대적 중요도를 육안으로만 파악하는데는 한계가 있습니다.

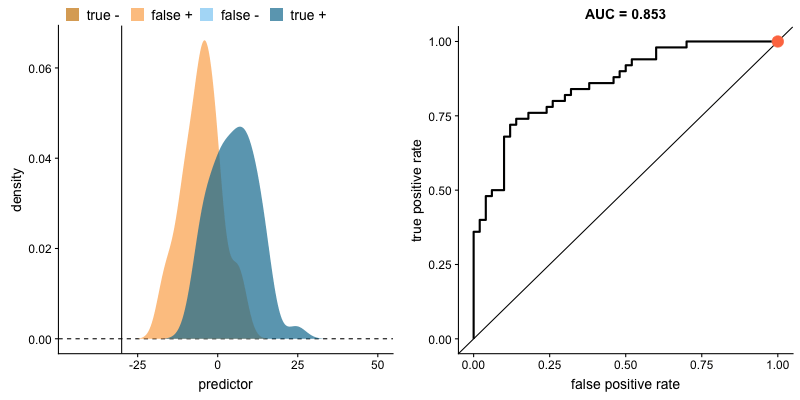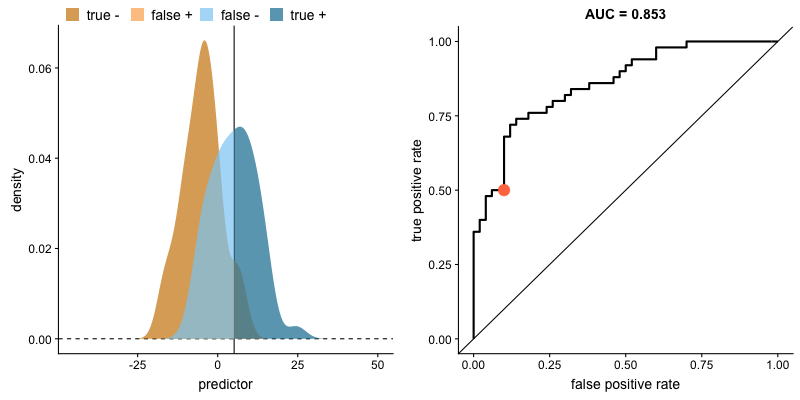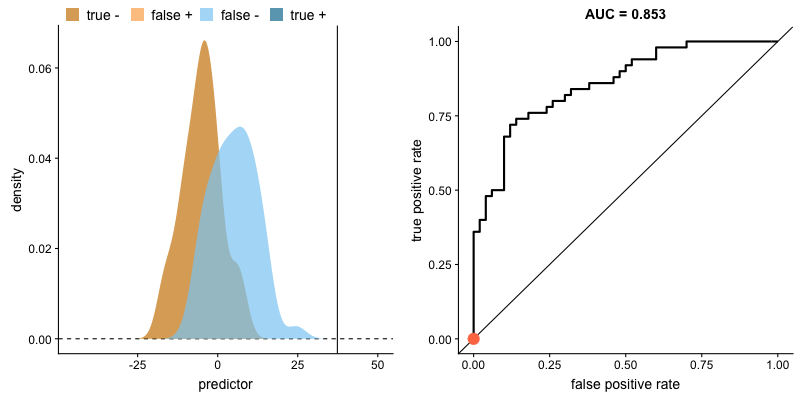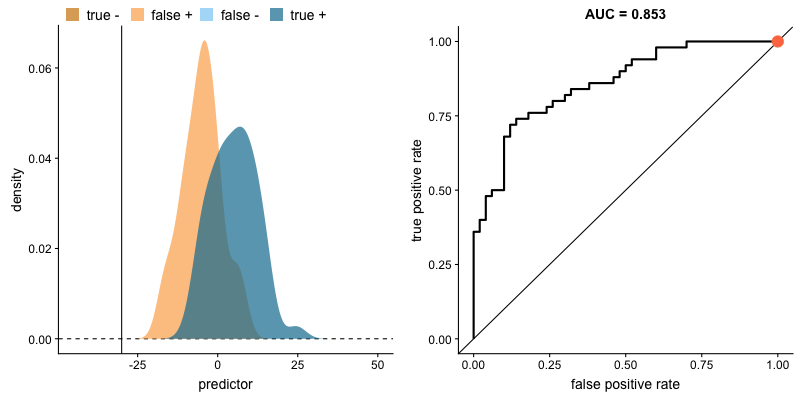
*AUC는 Area Under Curve(곡선 아래의 면적)의 약어로, 주어진 두 집단의 분포에서 생존, 사망 집단을 구분하는 기준점(cutoff, 좌측의 수직 직선)을 얼마로(20세, 25세 등) 설정하느냐에 따라, True Positive(생존했을 거라 예측했고 실제로도 생존한 경우), False Positive(생존했을 거라 했는데 실제는 사망한 경우) 비율이 달라지는 위치를 좌표 상에 표기 한 후, 해당 점들을 이은 선(ROC curve라고 함) 아래의 면적을 나타냅니다.
두 집단의 분포가 주어졌을 때, *AUC(위 박스글 참고)가 클 수록 해당 변수가 두 집단을 잘 구분할 수 있다고 얘기할 수 있습니다. 아래 그림처럼, 두 집단의 분포가 겹치는 영역(교집합)이 없는 상태가 되면 AUC는 1이 됩니다. (AUC가 1인 경우 해당 변수로 두 집단을 완벽하게 구분 가능하다는 의미입니다.)
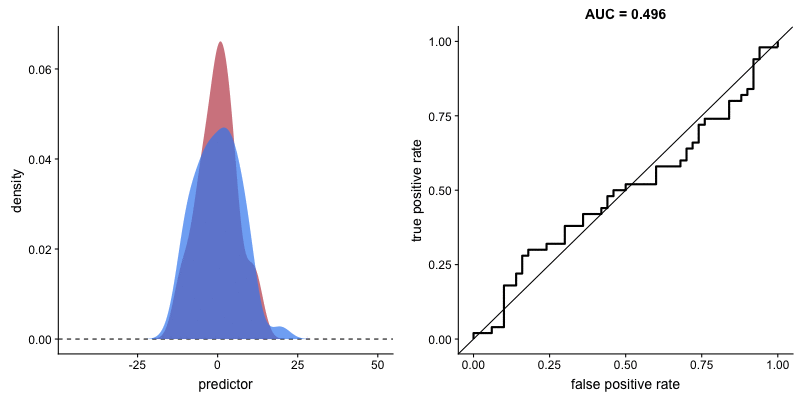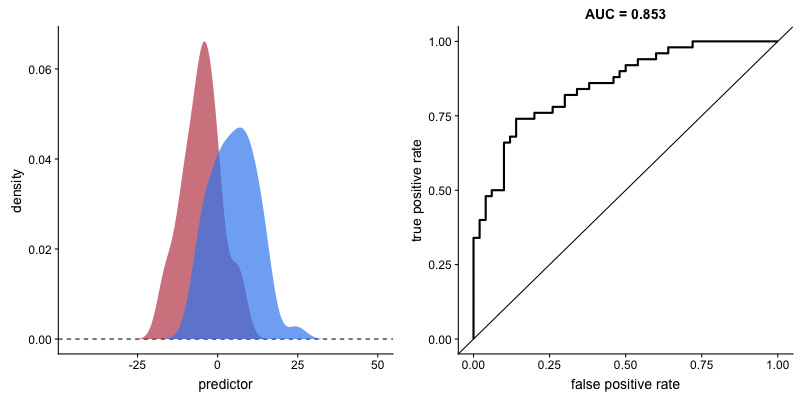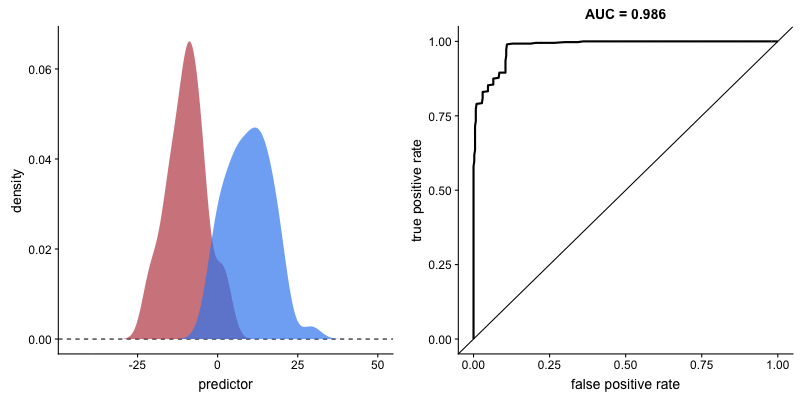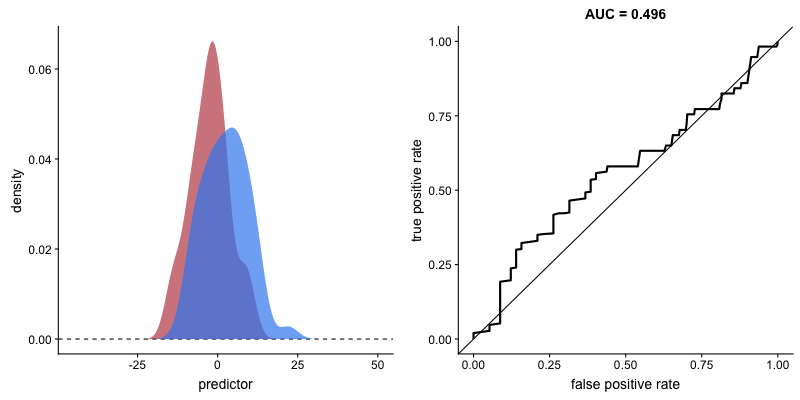
서로 다른 집단을 분류하는 모형(logistic model, decision tree 등)의 성능을 종합적으로 평가할 때 AUC가 사용되곤 합니다.
Dataset: 타이타닉 데이터
우선 타이타닉 데이터셋은 아래처럼 구성되어 있습니다.
주요 변수를 살펴보면,
•
survival: 생존/사망 여부를 표시하는 변수
•
pclass: 몇등석을 탔는지 표시하는 변수
•
sex, age: 성별, 나이
타이타닉 데이터셋: https://www.kaggle.com/c/titanic
Analysis in Heartcount
HEARTCOUNT로 타이타닉호 생존자, 사망자를 구분하는 특성 찾기
성능 좋은 예측 모형을 만들어 우리 회사 서비스에 반영할 것이 아니라면, 실무적 관점에서 두 집단의 차이를 이해하는 일은 아래 두가지 목적으로 이루어집니다.
•
개별 변수들의 상대적 중요도를 파악하기 (예, 순익이 높은 매장들의 가장 두드러진 특성은 매장직원들의 퇴사율이 낮다는 것이다.)
•
특정 집단이 높은 순도로 모여있는 변수들의 조합 찾기 (예, 퇴사율이 15%이하이고 배달 비중이 30% 이하인 매장들의 경우 90%의 확률로 순이익 기준 상위 20% 매장 집단에 속했다)
[HEARTCOUNT 비교 분석]
레시피
1.
그룹A와 그룹B에 특성 차이를 이해하고자 하는 두 집단의 조건을 설정합니다. 예시에서는 그룹A에는 사망자(Survived=0), 그룹B에는 생존자(Survived=1)를 설정했습니다.
2.
그룹 설정을 완료했다면, [비교] 버튼을 클릭하면 됩니다.
분석 결과 해석
•
Survived 100%: 맨 상단의 결과는 생존/사망 여부를 표시하는 (목표)변수인 "survived"가 나오게 되고, (당연히) 해당 변수로 두 집단이 100% 구분되는 것을 확인할 수 있습니다.

[SEX 변수 결과만]
•
sex, female: 성별이 두 집단을 구분하는 가장 주요한 변수이고, 생존자(붉은색으로 표현된 그룹B)의 68.13%가 여성이었던 반면, 사망자(파랑색, 그룹A)의 경우 14.75%만이 여성이었고, 여성(female)은 생존자의 주요 특성이라 말할 수 있겠네요.
•
sex, 42.8%: 숫자 42.8은 생존자/사망자를 성별(female, male)로 구분하니, 분포가 겹치지 않는 면적의 비율이 42.8%쯤 된다는 의미입니다.(보라색은 겹치는 영역을 나타냄). 두 분포의 차이를 정량적으로 계산하기 위해 내부적으로 "Kullback–Leibler divergence"라는 알고리즘을 좀 변형하여 사용하고 있고, 42.8%은 해당 변수가 두 집단을 구분하는 데 상대적 중요도를 측정하기 위한 지표 정도로 이해하면 좋겠습니다.