
두 집단을 구분하는 특성 찾기 관련 시리즈
Intro
데이터에서, Signal과 Noise란?
현업 관점에서 데이터 분석이란 목표변수(Y) 값의 차이를 설명하는 일이고
차이는 본질적인 차이와 우발적인 차이의 합으로 구성됩니다.
전국의 개별 대리점들이 나타내는 순이익률의 차이는 대리점에 내재된 본질적 성과(기량) 차이의 반영일 수도 있고 단순히 운이 좋아 장사가 잘(안)된 것의 반영일 수도 있는 것처럼 말이죠.
본질적인, 그래서 일반화할 수 있는 차이를 Signal이라 하고 우연(Chance)에 의해 유발된 차이를 Noise라 했을 때 Signal과 Noise를 어떻게 구분할 수 있을까요?
(우발적이거나 허구적 서열에 근거한 차이를 본질적 차이라고 주장한 것이 차별의 역사이기도 합니다.)
참고로 안정된 시스템일수록, 시스템을 구성하는 개별 구성요소들의 기량의 차이가 적어진게 된다. 이것은 구성요소들(예, 개별 대리점)이 best practice를 서로 서로 학습한 결과 돈버는 기량이 서로 비슷해지게 되어, 결국 이익의 차이(변량) 역시 작아지기 때문이다. 이렇게 기량의 차이가 적은 구성요소들로 구성된 시스템에서는 개별 구성요소들의 성과 차이에 미치는 운의 영향력이 상대적으로 커지게 되는데 이런 현상을 기량의 역설(Paradox of Skill)이라고 한다.
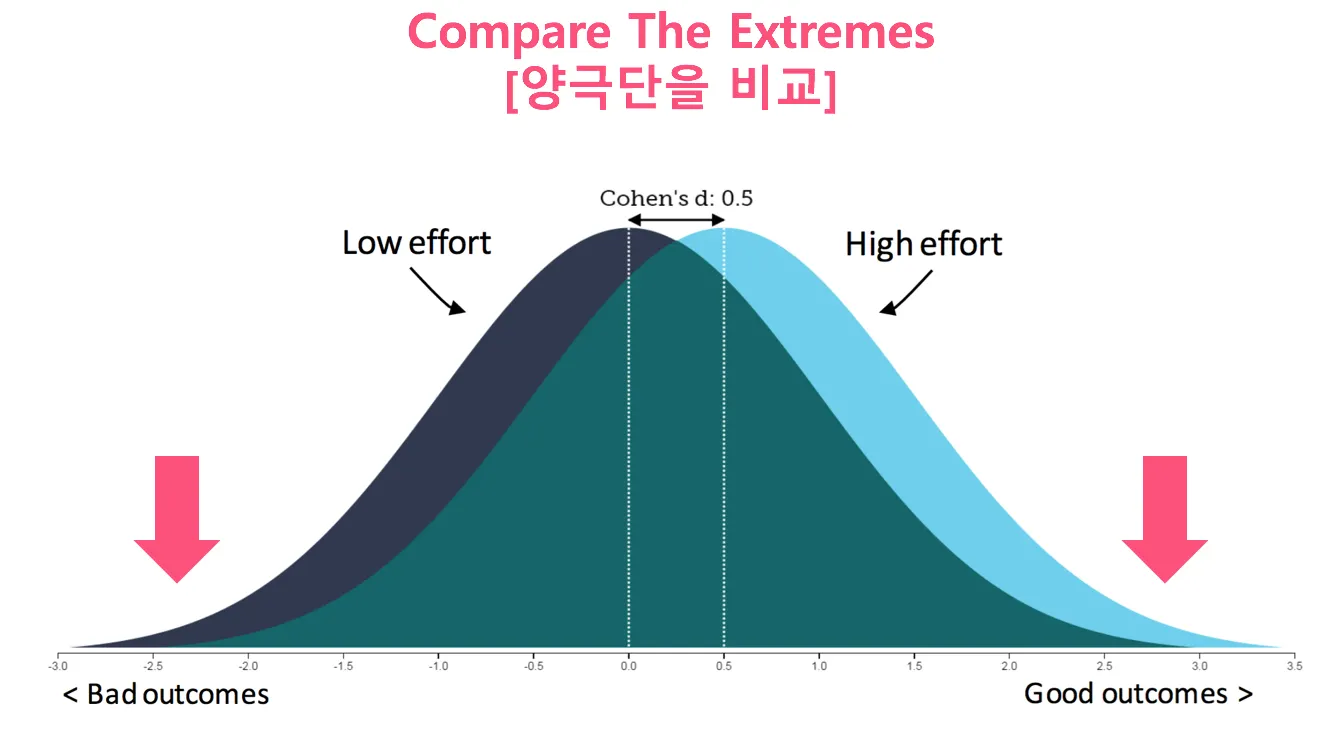
양극단의 두 집단 비교하기
이번달에 대리점 A 주변에 큰 국제 행사가 열려 대리점 A의 이익이 예외적으로 높았다고 해봅시다. 대리점 A의 이익은 다음달에는 아마도 다시 평균(평범함)으로 회귀하게 될 겁니다. (Regression to Mean/Mediocirity)
하지만, 지난 2년 동안 꾸준히 높은 이익률을 낸 대리점은 운(우발적 사건;Noise) 때문이 아니라 매장에 내재된 본질적인 기량이 이익의 차이로 나타난 것이라 생각할 수 있습니다. (반대로 꾸준히 장사 못하는 대리점의 경우도 마찬가지)
어떤 특성(이익)의 양극단(예, 이익률 상/하위 20% 대리점; 성과점수 3년 평균 상/하위 20%인 직원)에 위치한 대상을 비교하면 스펙트럼의 중간에 위치한 판단하기 애매한 애들(운과 기량이 골고루 섞여 있는 애들)이 분석 대상에서 제거되어 주어진 특성(이익) 차이를 가져오는 보다 본질적인 요인(패턴, Signal)을 찾을 수 있습니다.
Decision Tree Algorithm(의사결정나무 알고리즘)이란
서로 다른 두 집단의 두드러진 차이를 통하여 두 집단을, 완벽하게는 아닐지라도 최대한, 끼리끼리 모이도록 구분(Classification)하는 규칙을 찾는 대표적인 분석 알고리즘이 의사결정트리(Decision Tree)입니다.
예를 들면, 장기근속자(A)와 조기퇴사자라(B)는 서로 다른 두 집단을 구분하는 논리적 규칙을 의사결정트리 알고리즘을 통해 아래와 같이 찾을 수 있습니다.
•
장기근속자 분류규칙: [나이 >= 27] & [채용경로=신문광고]인 경우 90% 확률로 장기근속자
•
조기퇴사자 분류규칙: [나이 < 27] & [학력=석사 or 박사]인 경우 93% 확률로 조기퇴사
실습
Dataset: Superstore
월마트의 매출 관련 변수들이 모여 있는 ‘SuperStore’ 라는 데이터로 Signal과 Noise를 분리하는 실습을 해보겠습니다.
주요 변수를 살펴보면,
•
이익
•
매출
•
할인율
•
배송 방식

실습에 사용된 매출 데이터 다운로드 받기
Analysis in HEARTCOUNT
레시피
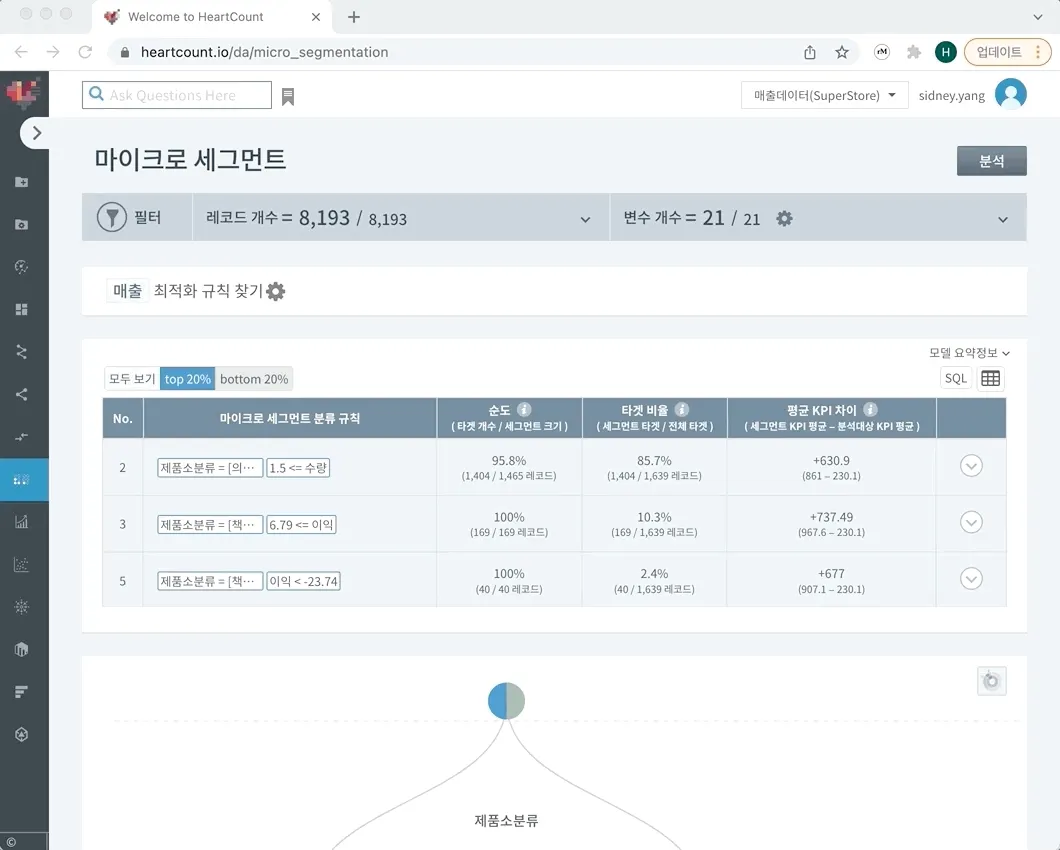
가구 판매 이익이 상위 20%인 그룹과 하위 20%인 그룹을 비교 분석하여 양극단의 두 집단(Top 20% vs. Bottom 20%)를 분류하는 규칙을 찾아보려고 합니다.
•
스마트 필터 기능을 통해 [제품대분류=가구]로 설정하면, 가구의 매출 데이터만 분석할 수 있습니다.
•
집단 구분의 기준이 될 변수로 [이익]을 설정합니다.
•
숫자형 변수를 목표변수로 설정하면 자동으로 상위 20%(top 20%)그룹과 하위 20%(bottom 20%)그룹으로 분류됩니다.
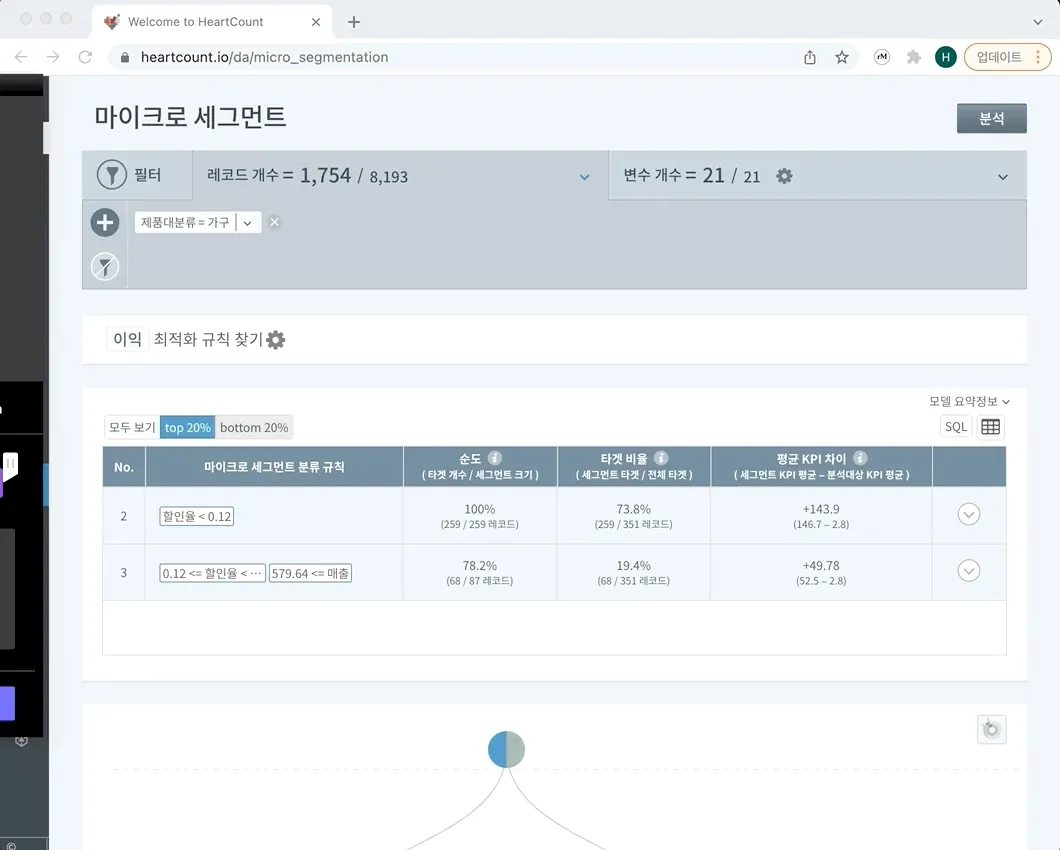
분석 결과 해석
•
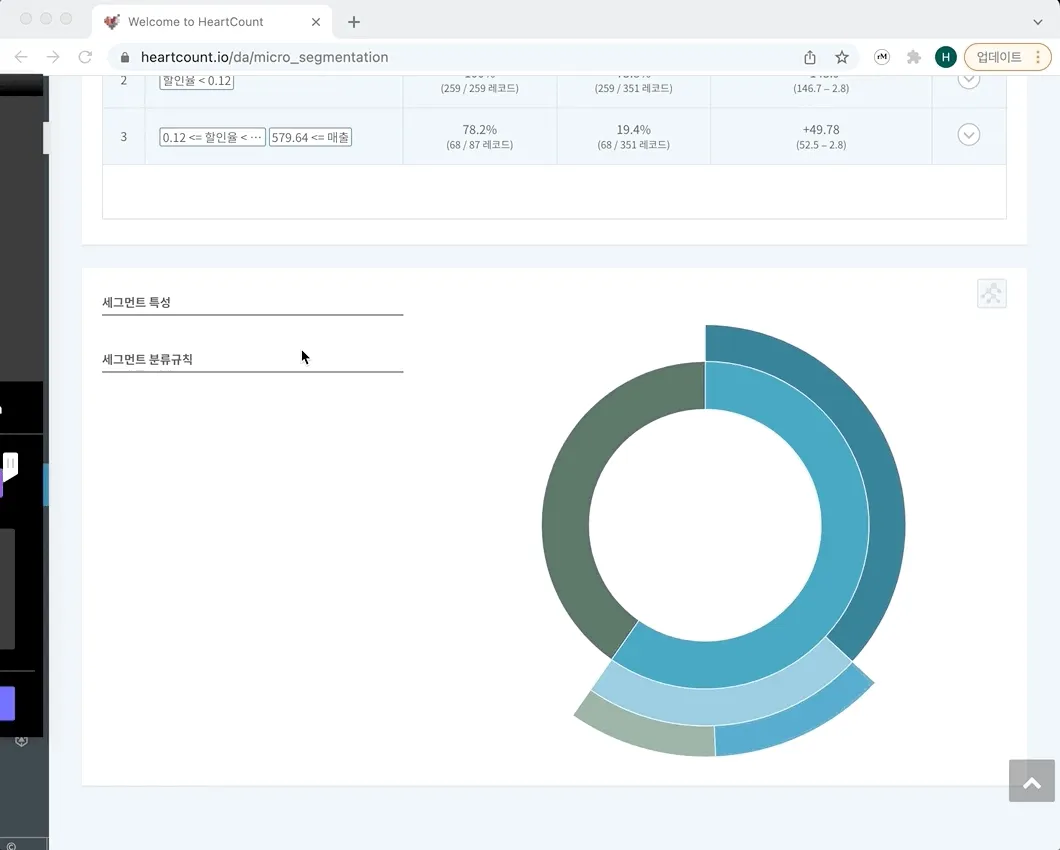
결과는 tree 또는 sunburst 형태로 표현할 수 있습니다.
•
tree 형식의 시각화에서는 각 node(원)을 클릭하면 해당 규칙을 확인할 수 있고, sunburst 형식에서는 색상으로 구분된 호(arc)에 mouse-over하면 분류 규칙을 확인할 수 있습니다.
•
개별 세그먼트 분류규칙을 해석해보면,
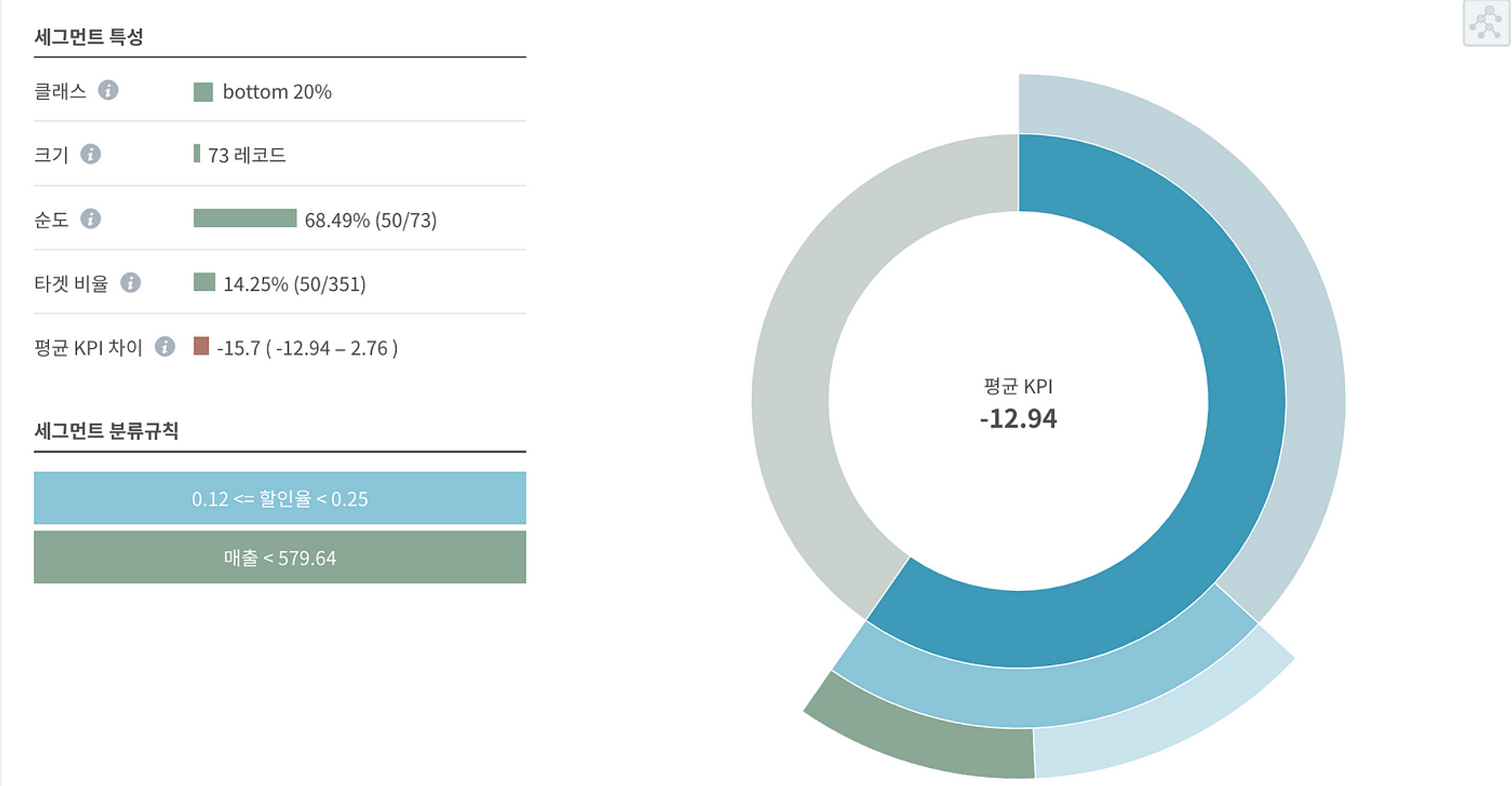
마이크로세그먼트 분석시 첫 화면으로 제공되는 sunburst 형식
◦
순도 (;해당 분류 규칙이 얼마나 정확한지 측정할 수 있음.)
분류규칙에 해당되는 모든 레코드들(할인율이 0.12 이상 0.25 미만이며 매출은 579.64 미만인 경우)의 68.49%가 가구 판매 이익 하위 20%이다.
◦
타겟 비율
가구 판매 이익 하위 20%인 총 매출건들 중 14.25%가 해당 규칙으로 설명된다.
분류 규칙(모델)을 더 좁혀볼 수도 있습니다.
•
마이크로 세그먼트의 분류 규칙은 기본 설정상 타겟변수를 제외한 나머지 변수들에서 발견됩니다.
•
범위를 더 좁히기 위해 변수 필터를 통해 정하거나, 분석 결과에 있는 변수를 변수 필터 영역으로 drag&drop하면 해당 변수를 제외한 나머지 변수들로 분류 모델이 만들어집니다.