
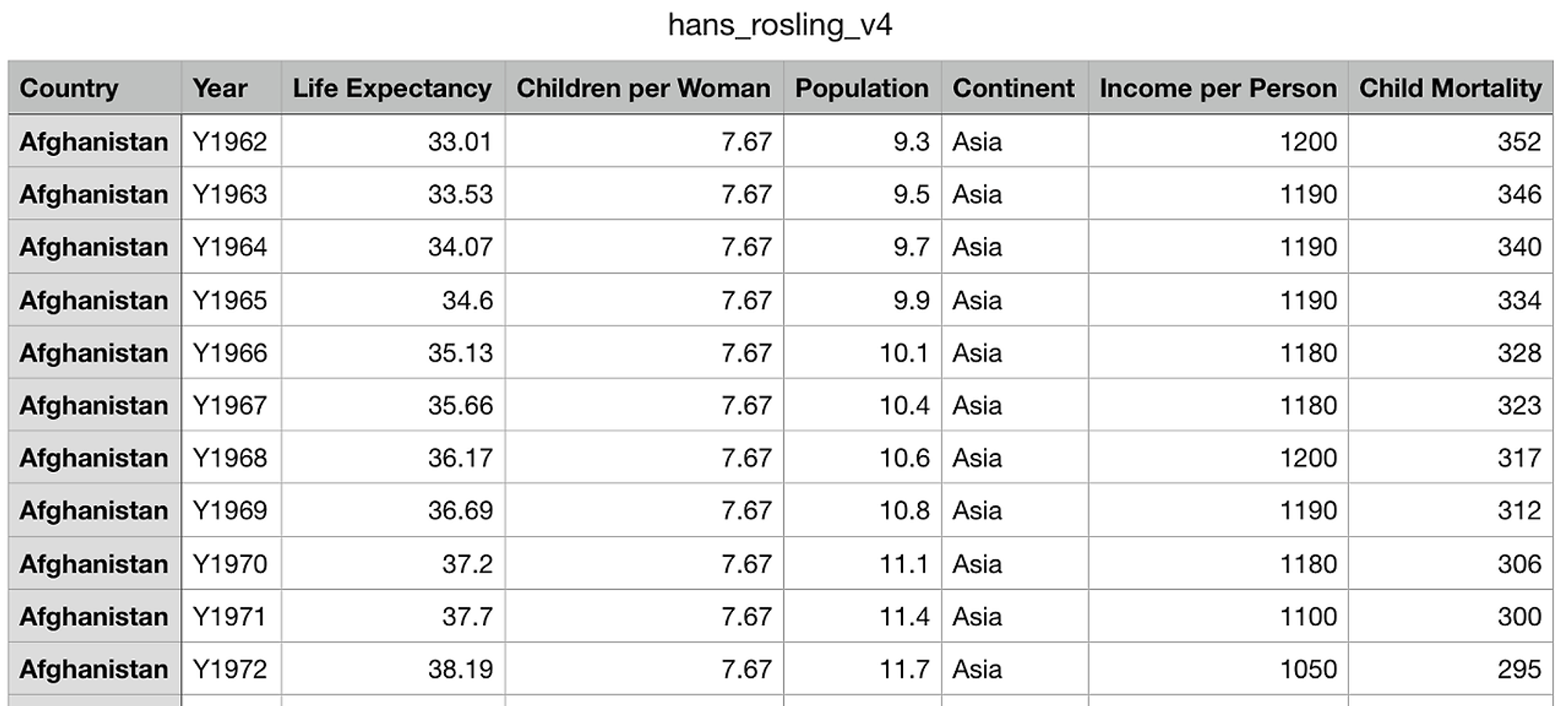
EDA 실습에 사용할 Dataset 설명
이 글에 사용한 데이터는 Hans Rosling이 데이터 시각화를 통해 사람들이 기본적인 사실관계에 대해 얼마나 무지한지를 드러내는데 사용했던 데이터셋으로 아래의 변수들로 구성되어 있다.
•
Country: 국가명
•
Year: 기대수명 등 각종 통계치가 집계된 년도
•
Life Expectancy: 기대 수명
•
Children per Woman: 여성 일인당 출산아동수
•
Population: 인구
•
Continent: 국가가 속한 대륙명
•
Income per Person: 일인당 소득(단위 $)
•
Child Mortality: 5세 이하 영유아 1,000명당 사망자수

Hans Rosling 데이터셋 : https://drive.google.com/file/d/1bm2ImU_MD-fvoNbIr-eTbAEUcipnfJZP/view
아래 EDA를 직접 따라하고 싶다면, 이 링크를 클릭해주세요.
Descriptive Analytics (기술적 분석):
기술적 분석은 데이터를 사실적으로 묘사(describe)하는 일이라고 정의할 수 있다. (테이블 형태로 정리된) 데이터만 있다면 기술적 분석을 통해 What Happened?에 대한 질문에 답할 수 있다.
갯수를 집계하고(몇 명이 방문했나?) 평균을 비교하는(지난 분기 상품군별 매출이 얼마였나?) 등 데이터를 요약하여 데이터가 담고 있는 다양한 사실들을 확인하는 일이다.
아래는 예제 데이터를 사용하여 주요 대륙들의 1962년~2015년 기대수명을 평균값으로 요약한 바차트이다. 오세아니아 대륙이 76.1세로 평균 수명이 제일 높았다는 “사실”을 확인할 수 있다.
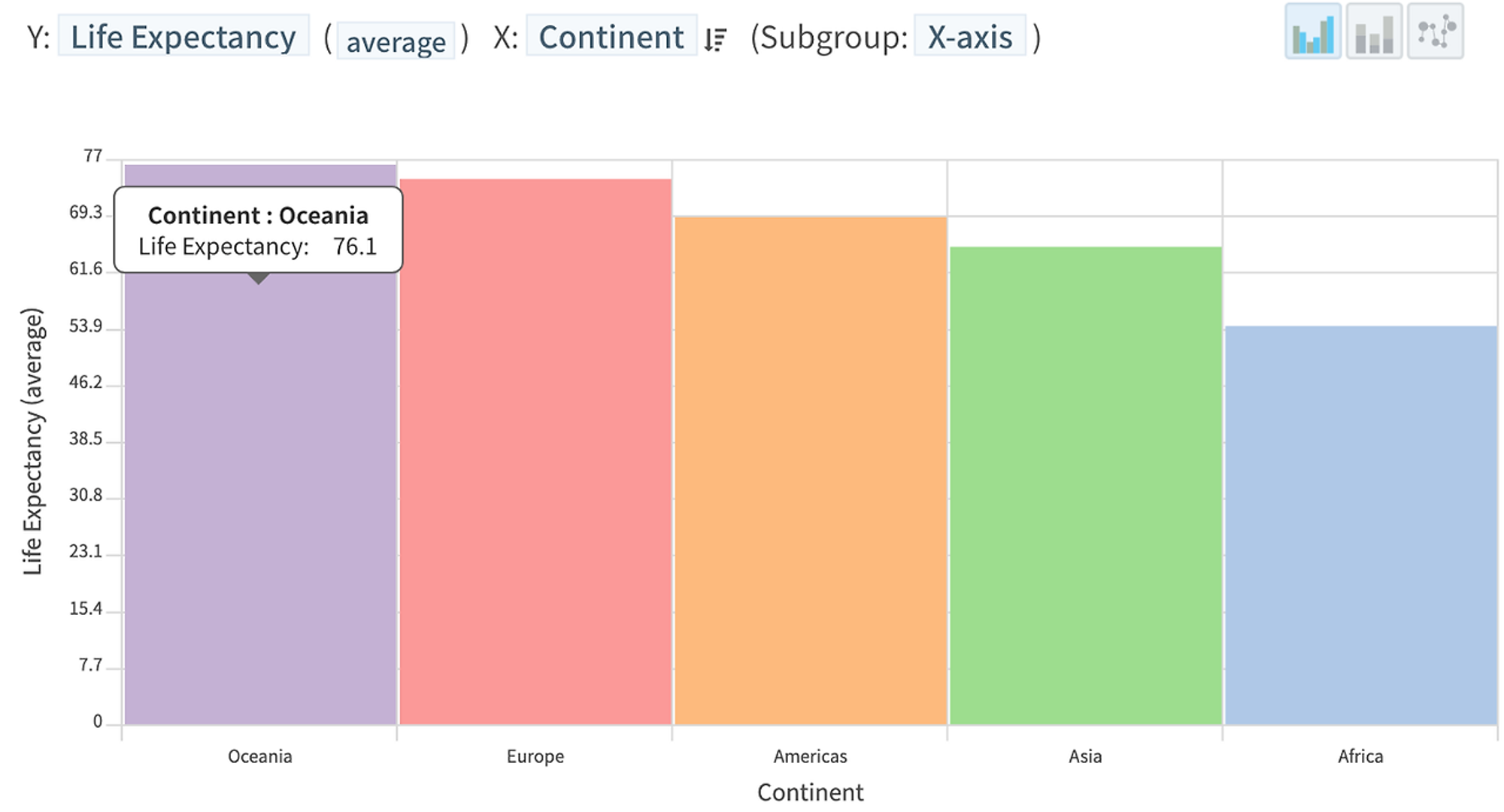
HEARTCOUNT의 스마트 플롯 - bar chart (1)
시간의 흐름에 따라 인류의 평균 기대수명 역시 꾸준히 증가했다는 “사실”도 확인할 수 있다.
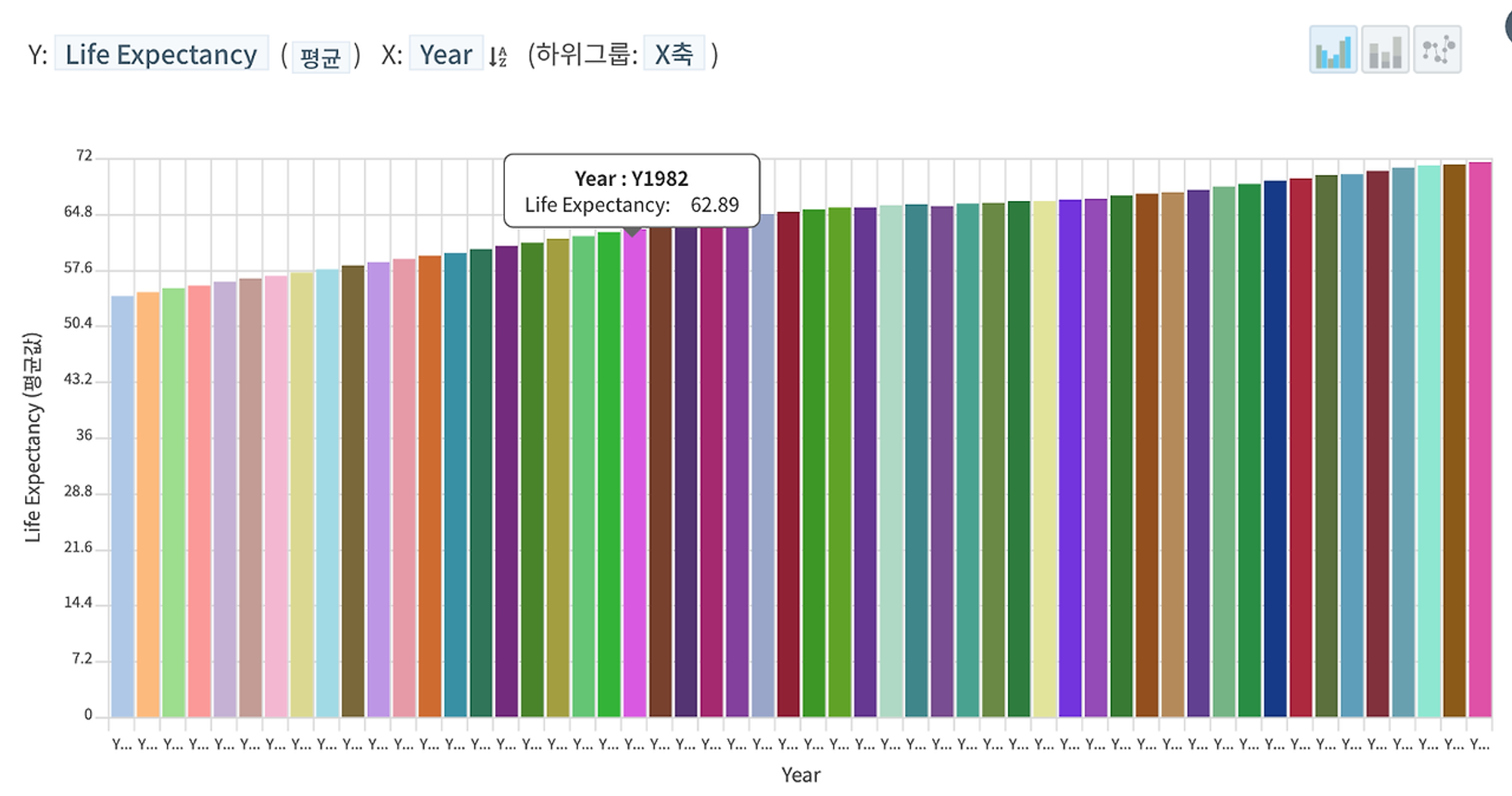
HEARTCOUNT의 스마트 플롯 - bar chart (2)
서로 다른 그룹(국가별, 연도별)의 평균을 비교하면 필연적으로 차이가 나는데 이 차이가 유의미한 차이인지 아니면 우연의 결과인지, 차이가 어디에서 비롯되는지 등의 질문에 답하려면 평균값을 비교하는 일에서 몇 걸음 더 나아가야 한다.
Exploratory Analytics (탐험적 분석):
통상 EDA(Exploratory Data Analysis)라고 일컬어지는 탐험적 분석은 시각적 분석 기법과 도구를 활용하여 데이터의 모양, 분포, 변수들 간의 관계를 차트와 기본적인 통계값(상관계수, 신뢰구간 등)을 활용해 확인하는 일이다.
분석 모형을 활용하여 데이터에 담긴 일반화할 수 있는 패턴을 찾는 데이터 모델링(추론, 예측 분석, 가설 검증 등) 작업을 하는 것은 아니고 편견없이 데이터를 요모조모 눈으로 살펴보며 기존에 궁금했던 것을 정량적으로 확인하고, 확인하는 과정에서 새로운 영감을 받고, 또 신박한 의문도 품게 되는 과정이다.
탐험적 분석과 기술적 분석 방법 간에 엄격한 경계가 있다기 보다는 탐험적 분석이 전통적 기술적 분석에 모던한 시각적 분석을 결합하여 기술적 분석의 유용성과 자유도를 높였다고 이해하는 편이 맞겠다.
EDA의 현재적 개념과 방법을 완성한 John W. Tukey의 말을 빌리자면 “EDA는 존재한다고 또는 존재하지 않을 거라 믿고 있는 것을 데이터에서 (시각적으로) 찾고자 하는 유연한 태도이자 의지이다"
“‘Exploratory data analysis’ is an attitude, a state of flexibility, a willingness to look for those things that we believe are not there, as well as those we believe to be there.” by John W. Tukey

EDA 용도 1. 데이터의 분포를 통해 유의미한 차이를 발견하기
대륙간 평균수명을 요약값(평균)이 아닌 분포(아래 그림은 박스플롯)를 통해 비교해보면 평균에 가려져 있던 불확실성(uncertainty)이 들어나게 된다.
오세아니아의 경우 평균 수명이 상대적으로 좁은 범위에 오밀조밀 몰려있는 반면, 유럽의 경우 평균수명이 낮은 레코드들(점으로 표현)이 아래쪽으로 넓게 퍼져 있는 것을 육안으로 확인할 수 있다.
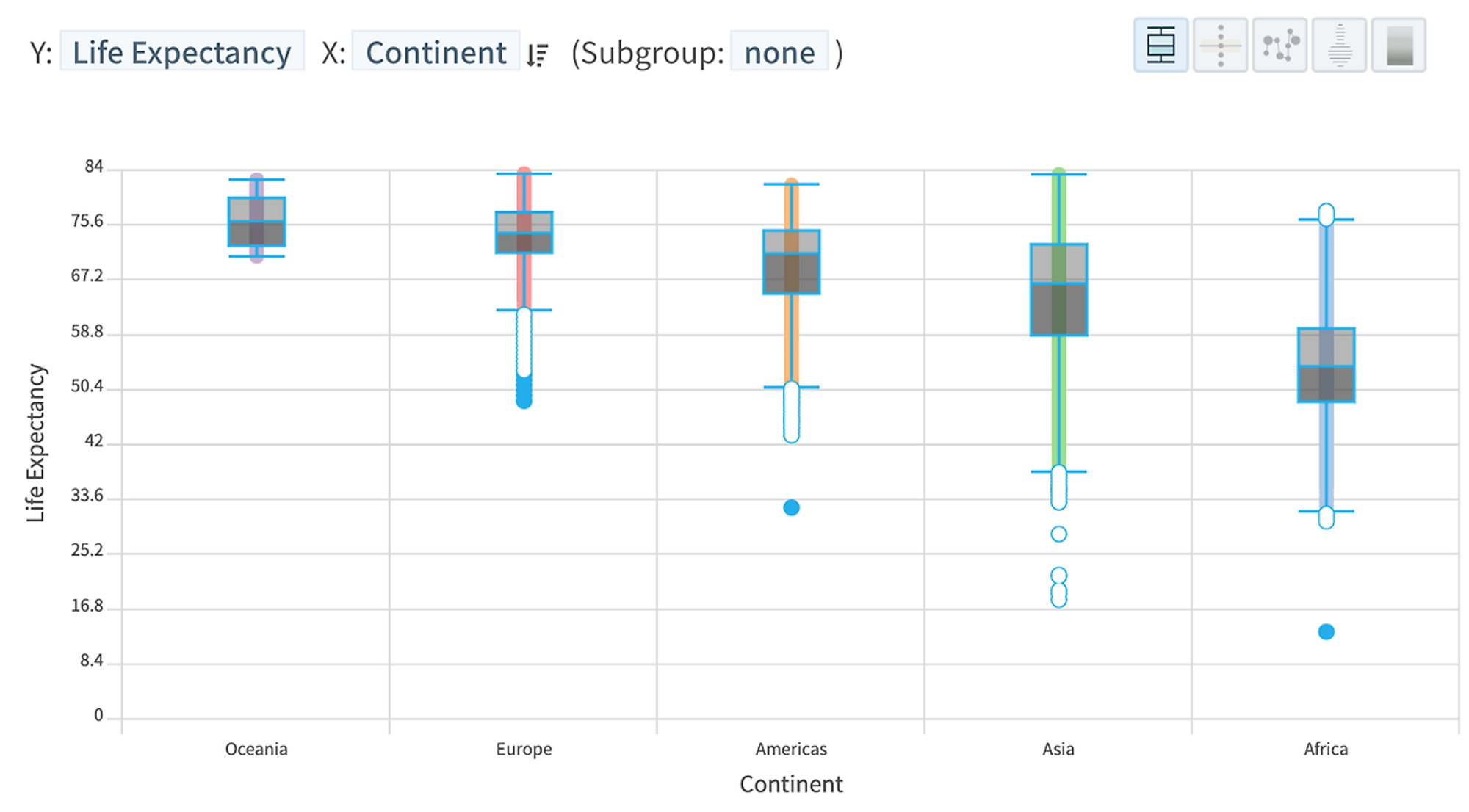
HEARTCOUNT의 스마트 플롯 - boxplot
•
평균값만 보고도 오세아니아와 유럽 대륙 간에 평균 기대수명에 차이가 난다고 확정적으로 이야기할 수 있다. 그건 fact니깐. 다만, 두 집단 간 평균값에 의미있는 차이가 있냐는 질문에 답하기 위해서는 두 집단의 분포를 함께 고려해야 한다.
•
분포를 보면 평균 뒤에 감추어져 있던 개별 레코드들의 불확실성(변동성, variation)이 드러나게 되며, 주어진 질문에 대해 확정적이 아니라 확률적으로 답해야 한다.
•
이번에는 동일한 분포를 박스플롯이 아니라 95% 신뢰구간(confidence interval)을 통해 비교해 보자. 실무적 차원에서, 서로 다른 집단 간에 95% 신뢰구간이 겹치지 않으면 두 집단 간에 평균값에 의미있는 차이가 있다(=차이가 우연히 발생한 것이 아님)고 이야기할 수 있다.
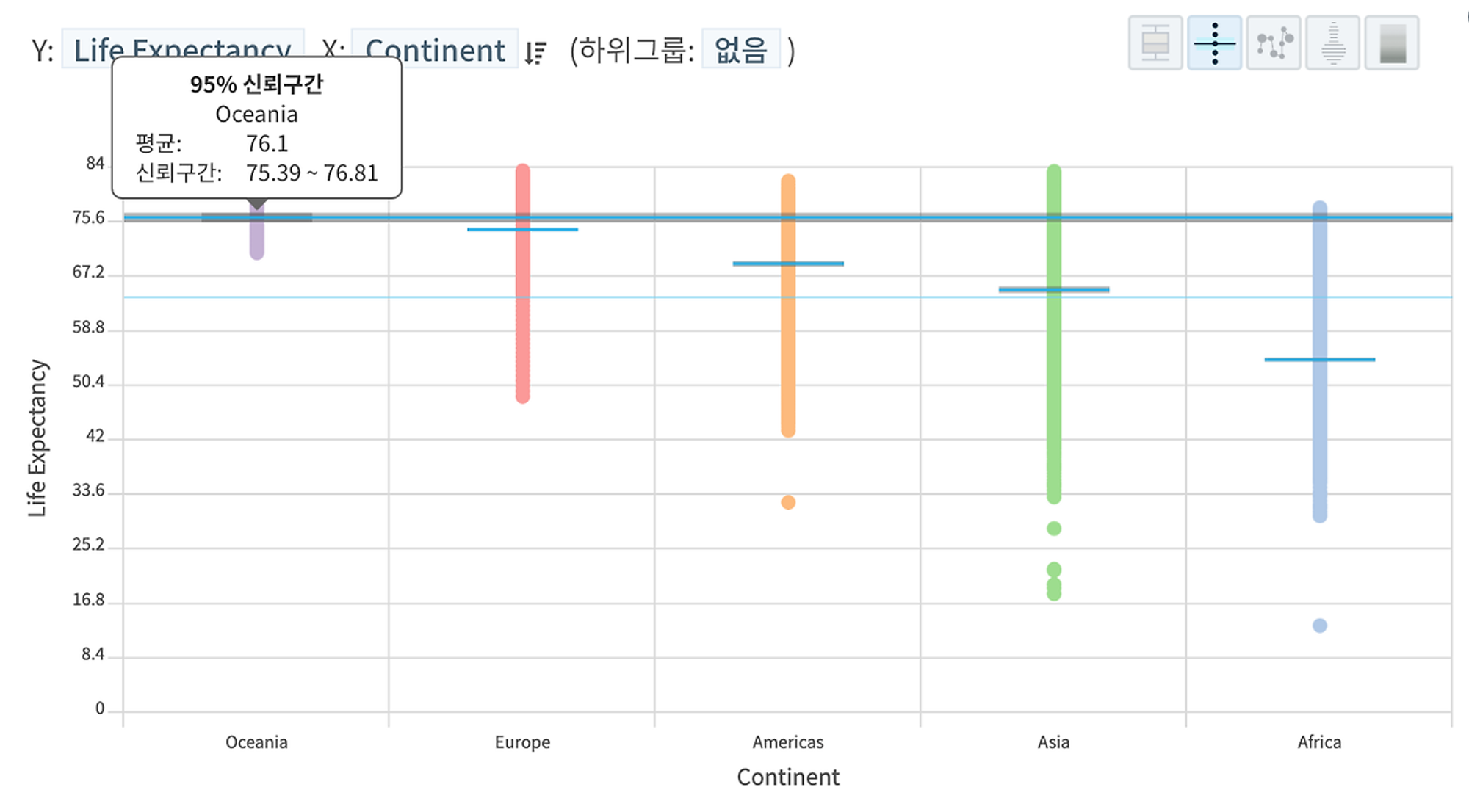
HEARTCOUNT의 스마트 플롯 - 95% 신뢰구간
•
신뢰도(90%, 95%, 99%)가 높아지면 신뢰구간의 폭이 넓어지며, 동일한 신뢰도일지라도 샘플 사이즈가 작을수록 신뢰구간이 넓어지게(불확실성이 커지게) 된다. 대부분의 교과서나 통계툴에서 신뢰구간은 t-distribtuion에 기반한 공식을 사용해 계산되지만 최근에는 개선된 컴퓨터 계산 능력을 활용해 bootstrap 방식으로 계산하기도 한다.
•
대부분 95% 신뢰구간을 "참값(가공/상상의 모집단의 진짜 평균값)이 해당 구간 안에 있을 확률이 95%이다"라고 알고 있는데, 이건 사실과 다르다. 진짜 평균값(true mean)은 우리가 모를 뿐이지 이미 정해져 있을테니 특정 구간에 해당 값이 존재할 확률은 100%거나 0%이지 95%일 수 없다.
•
95% 신뢰구간의 정확한 의미는 모집단에서 동일한 방식으로 샘플링을 한 후 신뢰구간을 계산하는 작업을 무한히 반복하는 경우, 계산된 신뢰구간들 중 95% 정도가 진짜 평균값을 포함하게 된다는 이야기다.
•
마찬가지로, 두 대륙의 평균수명을 확률밀도 그래프(Probability Density Plot)를 통해 비교해보면, 유럽인들의 기대수명이 오세아니아인들의 분포와 비교해서 왼쪽으로 치우쳐 있음이 확인된다.
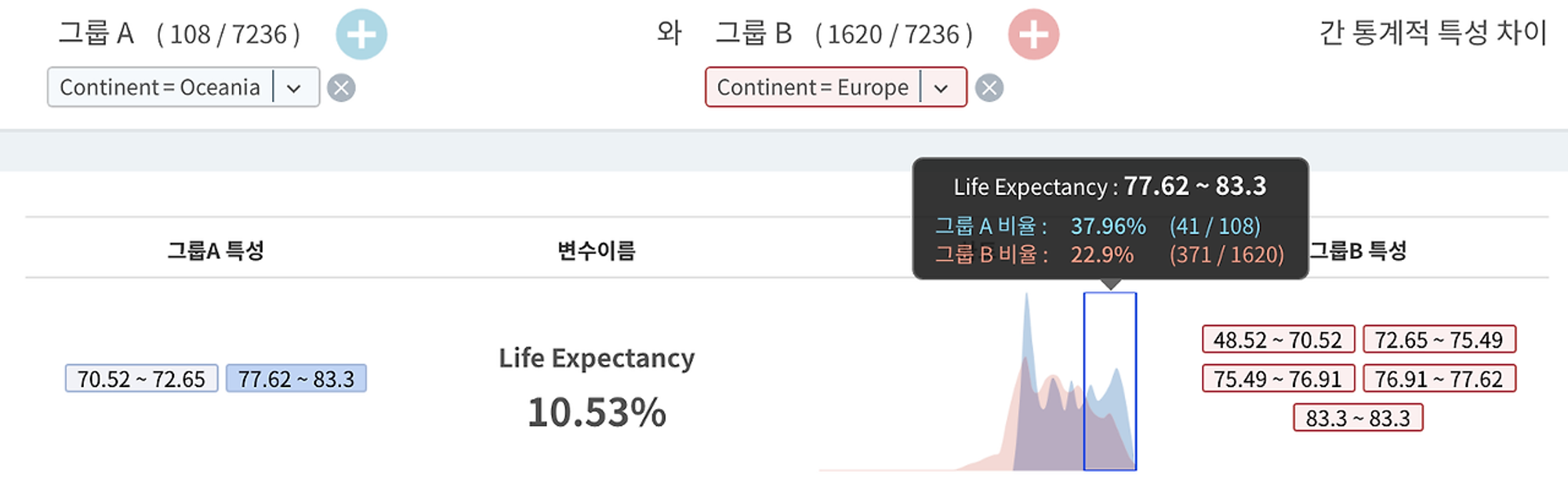
HEARTCOUNT의 비교 분석 기능
EDA 용도 2. 변수 간 상관관계 확인하기
기대수명이 다른 변수들과 어떤 관계를 갖는지 살펴보는 일도 EDA의 몫이다. 기대수명(Y)과 일인당 소득(X) 두 변수를 아래처럼 scatterplot(개별 레코드를 X, Y좌표 상에 흩뿌려서 표현하는 시각화 방법)으로 표현하여 두 변수간 상관관계를 확인할 수 있다.
아래는 기대수명(Y)과 일인당 소득(X)의 관계를 국가 단위로 묶어서(아래에는 하위그룹으로 표시) 시각화한 결과이다. 데이터셋에는 개별 국가의 레코드가 총 54건(1962~2015년, 각각 연도별 1건씩) 있는데, 국가별 54개의 관측값을 하나의 평균값으로 요약(aggregation)해서 하나의 점으로 표현한 차트이다. “평균소득이 높은 국가일수록 오래 사는 경향이 있다.”고 말할 수 있다.
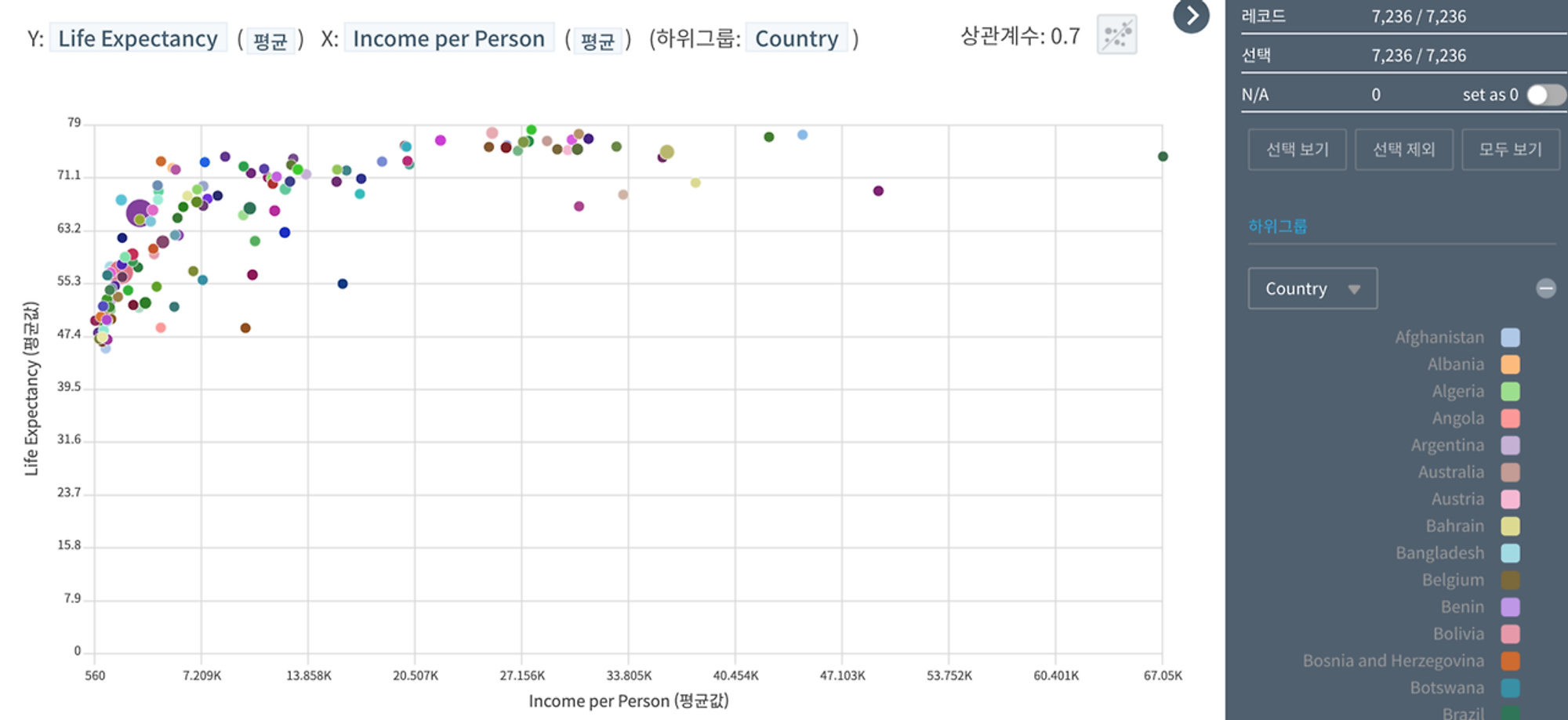
HEARTCOUNT의 스마트 플롯
이번에는 국가별로 레코드를 묶었던 규칙(하위그룹: Country)을 제거하고 개별 레코드를 건건이 시각화해 보자. 여전히 소득수준이 높아질수록 기대수명도 증가하는 관계(양의 상과관계)가 보인다.
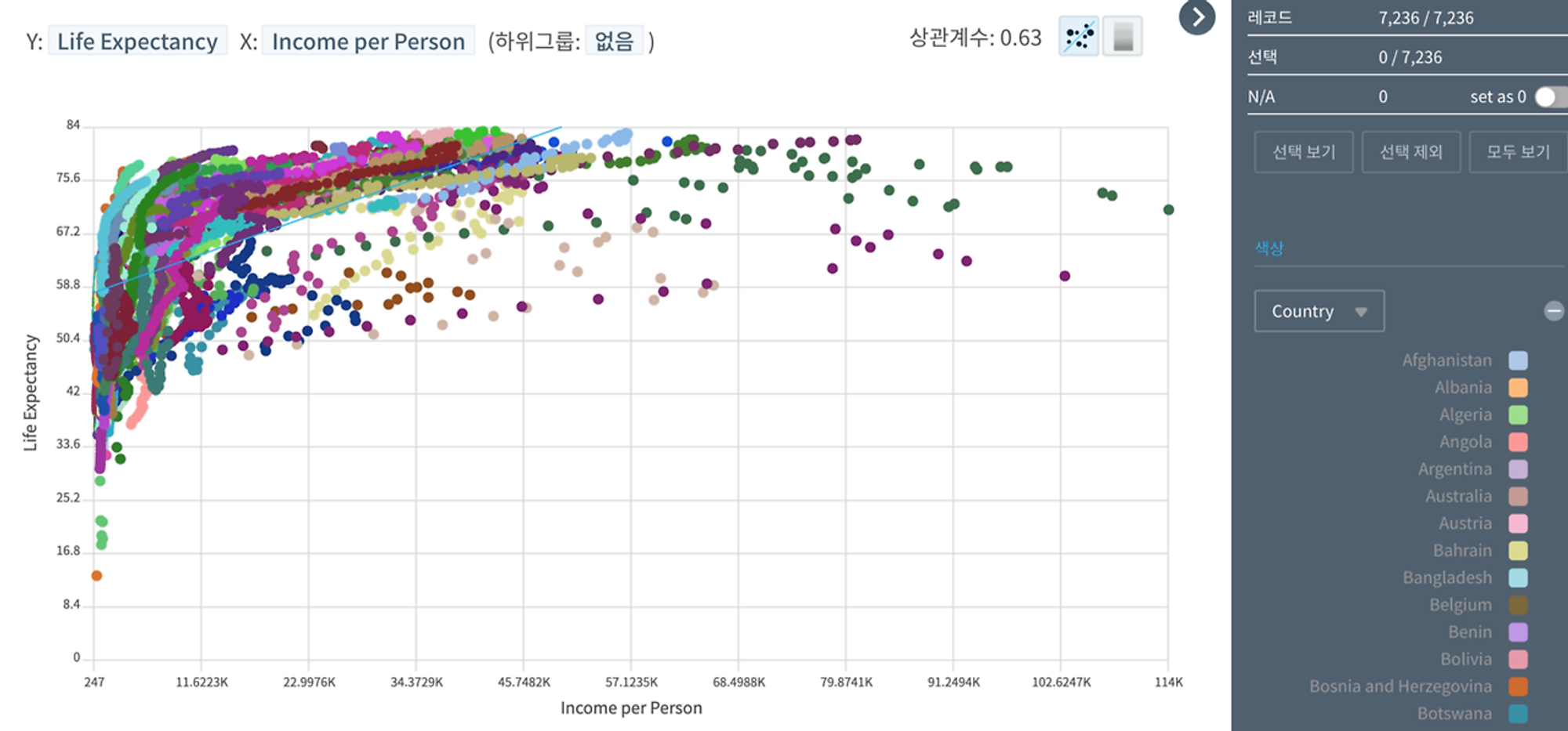
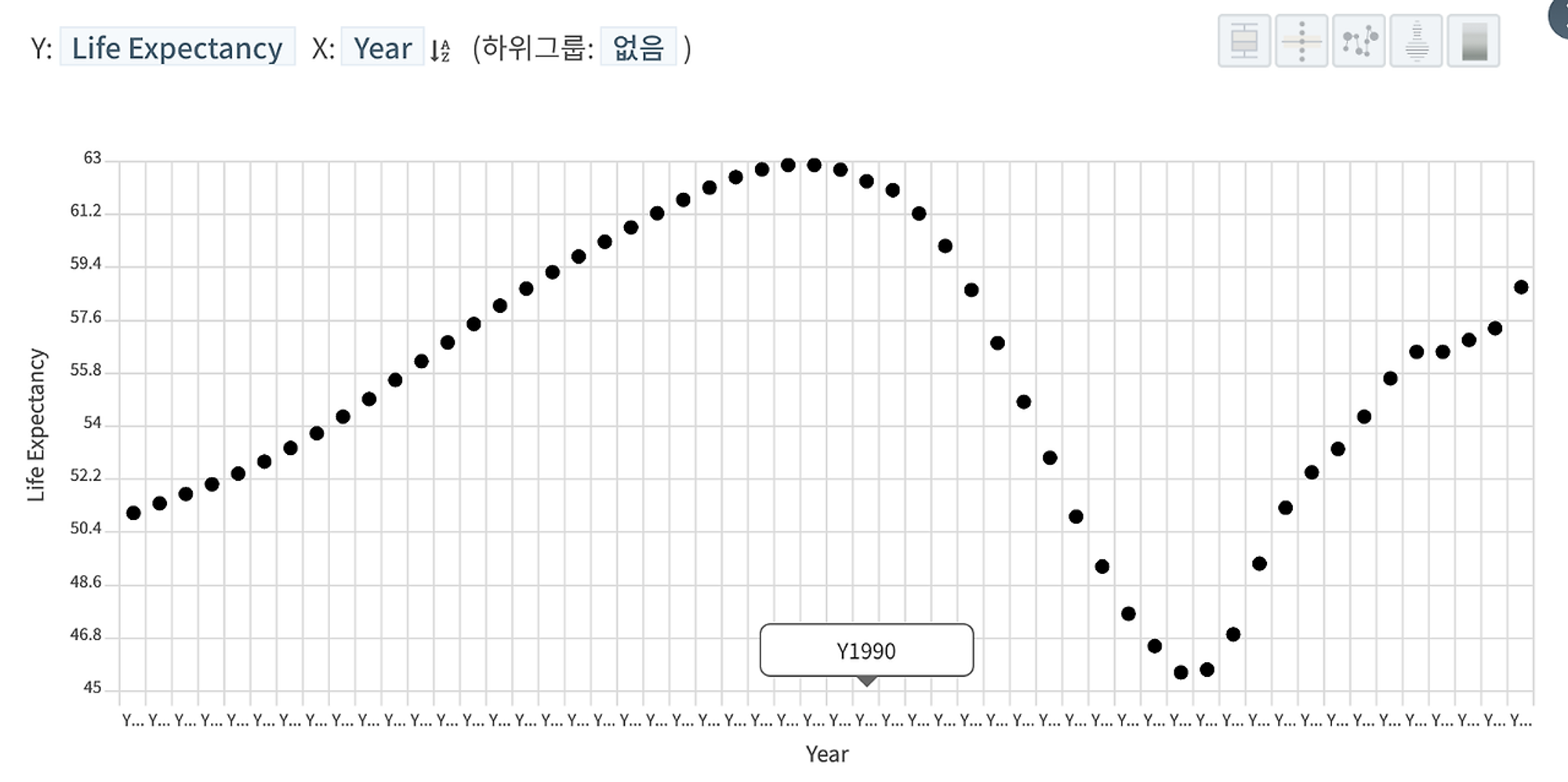
이번엔 개별 국가별로 따로 따로 살펴보자. (우측에 있는 개별 국가명 클릭) 특정 국가(보츠나와)에서는 선형적 양의 상관관계 대신 예외적인(비선형적인) 패턴을 보이기도 한다.

보츠나와만 따로 떼어 내어 기대수명을 시계열로 살펴보았다. 아마 일인당 국민소득 증대에 의한 기대수명 증가의 효과를 상쇄할 만한 다른 국가적 재난이 있었다고 추측해볼 수 있겠다. (정확한 원인은 우리가 확보한 데이터로는 알 수 없음)
appendix. 데이터 분석의 종류들
•
설명 분석과 예측 분석의 차이는 분석 기술과 방법에 있기보다는 분석의 목적에 있다. 동일한 분석 기술과 방법을 통해 만든 모델을 예측 용도로 활용할 수도, 설명 용도로 활용할 수도 있다.
•
설명 분석은 분석의 목적이 예측을 통한 의사결정의 자동화에 있는 것이 아니라 데이터로 현상에 대해 더 정확하고 깊은 설명을 찾아내어 더 좋은 의사결정을 내리는 데 있다.
•
추론 분석은 상대적으로 적은 샘플 데이터에서 발견한 패턴을 전체집단(모집단; 현실세계 전체)에 대해 일반화하기 위해 전통적 통계기법(p-value, 무슨무슨 검정 등)을 사용하는 일이다. 데이터가 상대적으로 흔한 요즘에 그 유용성이 상대적으로 낮아지고 있지만, 내가 발견한 패턴에 의심을 품고 있는 사람들을 “통계적으로" 설득하기 위해 활용할 수 있겠다.
•
인과분석은 기술로만 가능한 것은 아니고, 현실의 작동 방식에 대한 지식과 믿음에 기반해서 RCT나 Conditioning 등과 같은 분석기법으로 인과성을 찾는 분석 방법이다. 최근에는 실험데이터(RCT)가 아니라 관측데이터를 사용해 인과적 관계를 찾는 연구들이 활발히 진행되고 있다.
참고자료
•
Hans Rosling의 사상에 대해 더 자세히 알고 싶다면 "Factfullness"라는 책을 읽어 보아도 좋겠다.
•
•