What is Modern Data Stack?
modern data stack(for enterprise)이란, 데이터를 활용하는 조직에서 데이터 통합 및 분석에 사용하는 모든 소프트웨어/툴, 기술 등 제품군의 집합체를 의미합니다. 데이터는 내부 프로세스에 따라 스택을 통해 흐릅니다. 이를 통해 직원들은 필요할 때 필요한 정보에 액세스할 수 있습니다.
이번 글에서는 하트카운트팀이 제시하는 잘 짜여진(best-practice) modern data stack을 보여드리고, 구성 요소들을 주요 기술 - 관련 직무순으로 살펴 본 후에, 현업들의 Self-Analytics가 잘 안 되는 이유와 해결 방법을 제시하고자 합니다.
데이터가 단순히 목표가 아니라 수단이라는 가정 하에서 기술과 기능의 나열이 아니라 데이터를 실제로 다루는 사람들의 경험을 통한 데이터에 대한 이야기를 해보려고 합니다. 데이터 엔지니어, 사이언티스트, 애널리스트, 그리고 현업 및 C-Level(의사결정권자들)까지. 조직 내에서 데이터를 둘러싼 주요 인물들이 어떤 역할을 수행하고 있는지 알아보겠습니다.
데이터를 활용하는 기술: Statistisc, Analytics, AI·ML
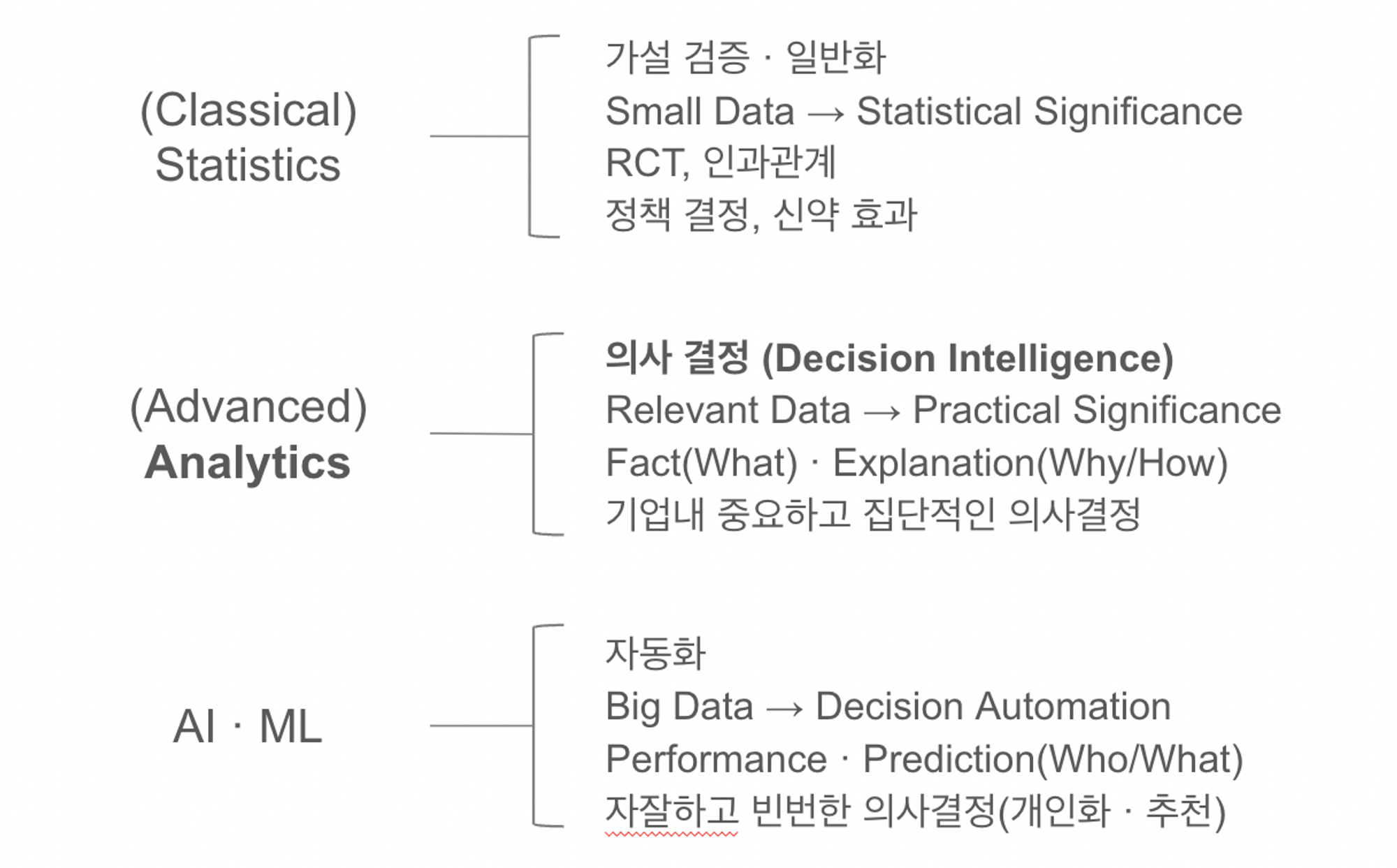
위 표에서 '데이터'하면 많이 들어본 단어들이 보이시죠? 하나하나 뭐가 다른지 설명해드리겠습니다.
우선, 현대 데이터 분석의 기반인 Statistics(전통적인 통계학)의 경우, 가설을 검증하고 일반화하기 위해 이루어집니다. 이 과정을 통하여 과거에 수집해놓은 작은 데이터가 통계적으로 중요한 데이터가 되기도 하고, 데이터간의 인과관계를 발견하기도 합니다. 실제로는 정책을 결정하거나 신약 효과 등 연구를 위하여 사용됩니다.
두 번째로, 데이터 집중 직무가 아닌 일반 현업들에게도 활용되는 Analytics입니다. 애널리틱스는 기업내 중요하고 집단적인 의사 결정을 위해 이루어집니다. 의사 결정과 관련 있는 데이터들을 수집하고 Fact(What)/유용한 패턴을 파악하고 더 나아가 Why(설명적 분석)와 How(예측 분석)을 통하여 실용적인 가치를 발견하고 이를 동료들에게 공유합니다.
마지막으로, AI와 ML(머신러닝)은 '자동화'를 위해 수행됩니다. 플랫폼 내 사용자들의 개인화/추천 시스템과 같이, 자잘한 일들을 자동화시키기 위하여 빅데이터를 활용, 개별 데이터를 분석하고 예측까지 이루어집니다.
Context of Digital Transformation
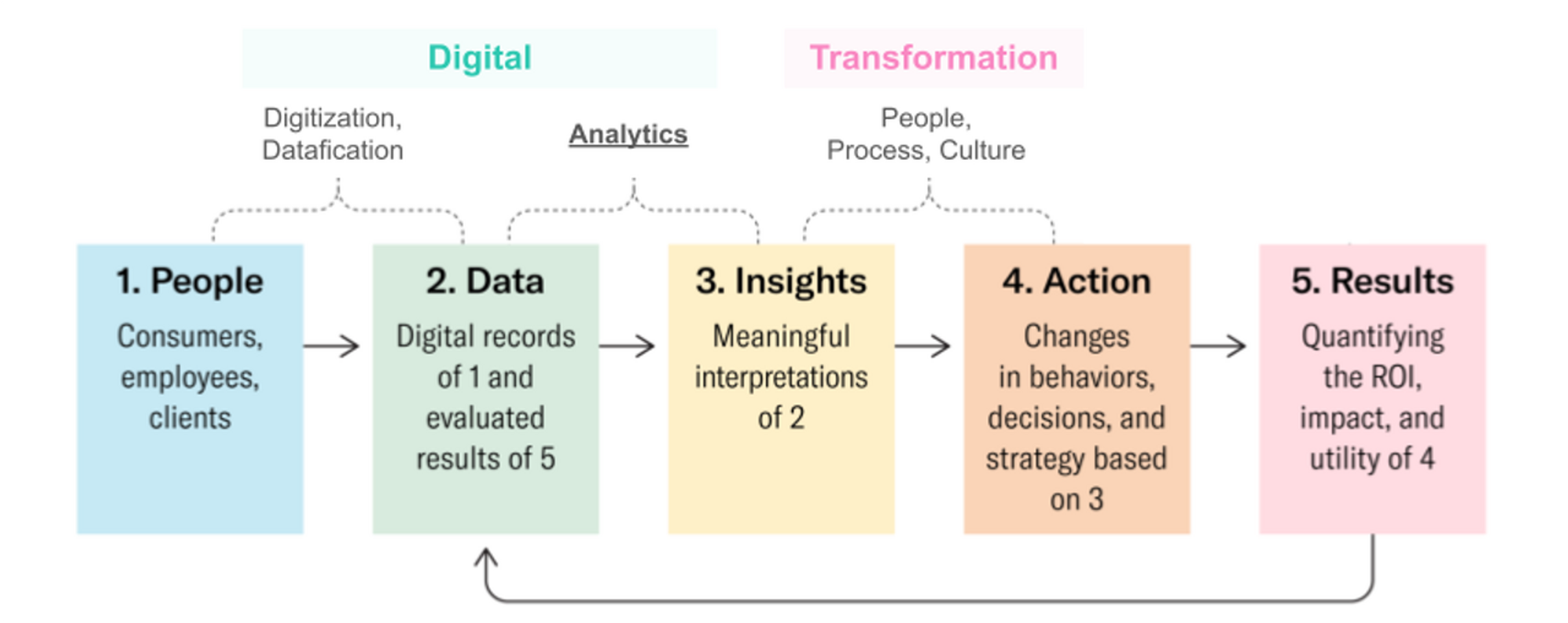
데이터가 조직 내에서 활용되는 일련의 과정을 청사진 형태로 표현한 장표입니다. 비즈니스 조직에서 DT는 결국 Data-Driven Decision Making(데이터 기반 의사결정)을 위한 과정이라고 볼 수 있습니다. 아래와 같이 D와 T의 영역으로 구분하여 전체 과정을 살펴볼까요?
Digital의 영역
1) People로부터 데이터를 수집하고
2) 수치화/데이터화합니다.
3) 실제 레코드 및 추정 결과를 분석(Analytics)하여 의미 있는 가치/패턴(Insights)을 발견합니다.
Transformation의 영역
4) 3로부터 얻은 인사이트를 조직 내 의사결정에 활용합니다. 이 과정에서 개별 조직의 일하는 방식(프로세스)/문화/사람이 개입됩니다.
5) 4에 대한 평가를 기록합니다. (ROI 등 주요 지표를 정량화하여)
Enterprise Modern Data Stack
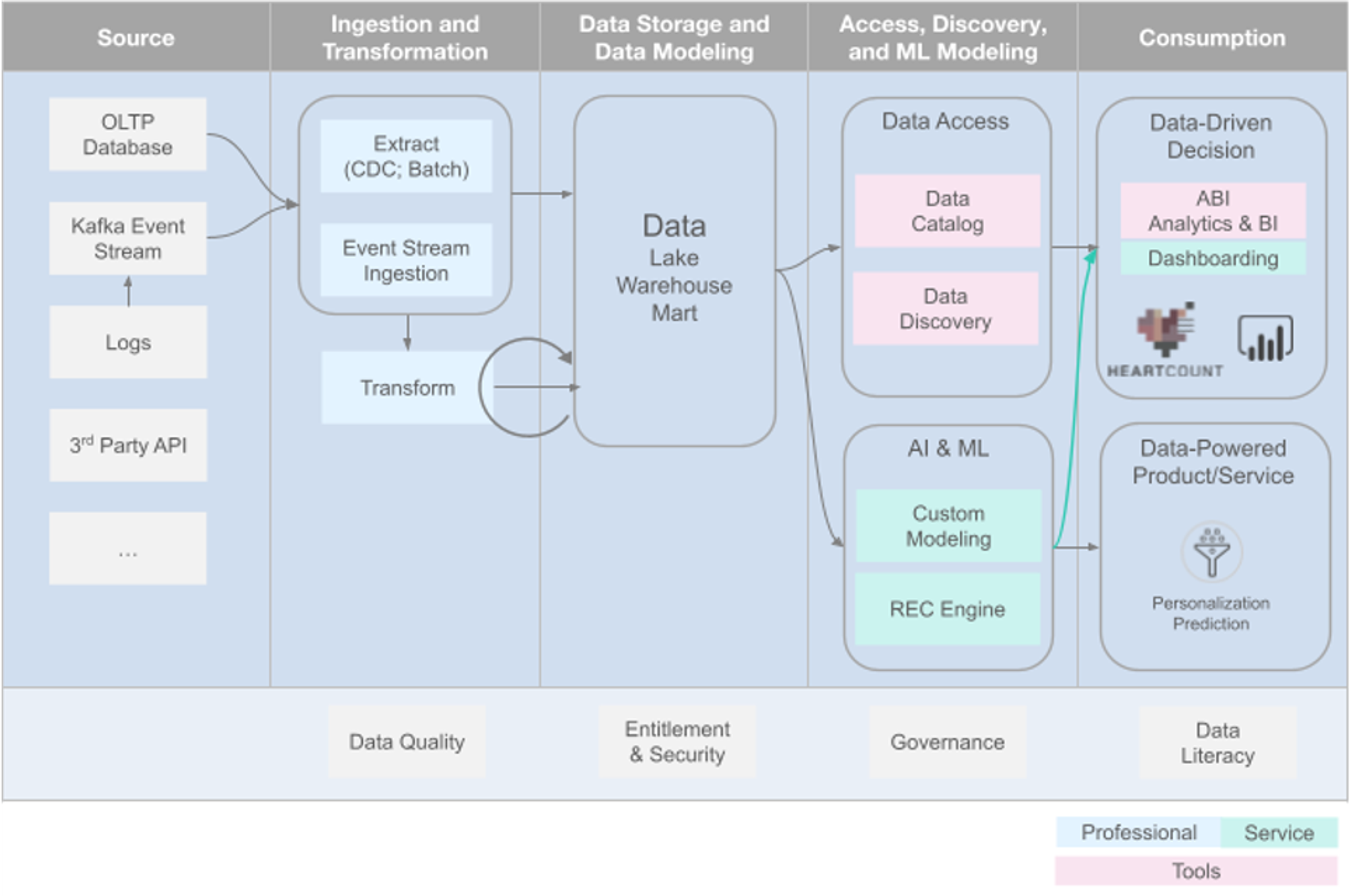
데이터 관련된 tool/product/technology가 어떤 것들이 있는지 보여주는 Data Stack(2020년 작성)입니다.
지나치게 세부화된 category들과 각 category 안에서 백가쟁명식으로 자신의 유용성을 주장한 수많은 tool들을, 기업들이 데이터를 다루면서 얻은 최신 경험과 best practice에 기반하여 좀 더 단순하게 구분하여 일종의 청사진 형식으로 제시했습니다.
결국, modern data stack은 데이터의 가치 사슬이라고도 생각할 수 있습니다. 지금 처음부터 다시 데이터 관련 인프라와 플랫폼을 구축할 수 있다면 이런 framework를 따라 하는 것이 조직 내에서 데이터가 잘 흘러 목적지에서 가치를 만들기 위한 best practice라는 것이죠.
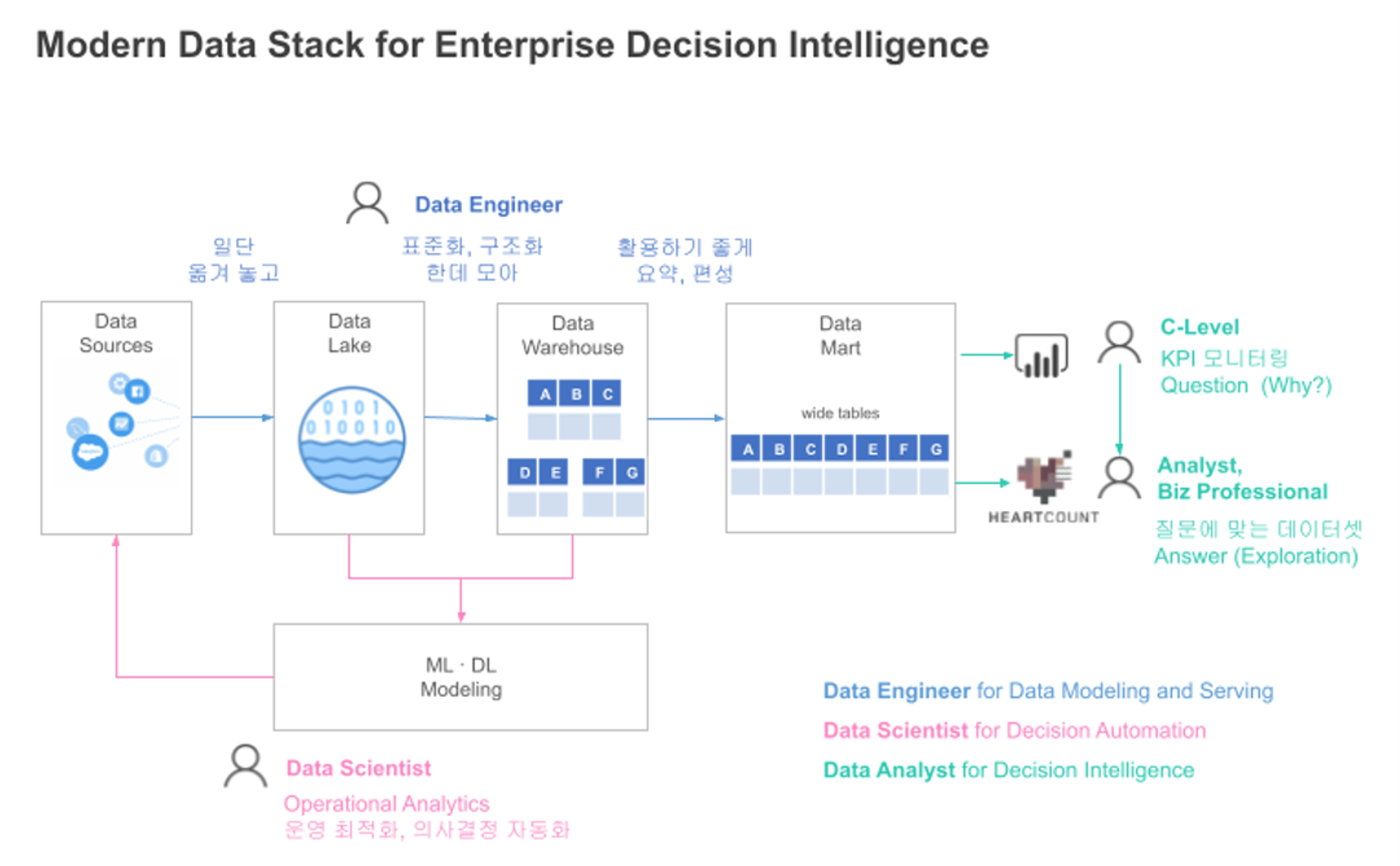
Data를 다루는 직무들, 각자의 역할
지금부터 간략하게 Data and Analytics 관련 주요 업무 영역을 살펴보겠습니다.
1. 데이터 수집/관리 등 기초를 담당하는 Data Engineer(데이터 엔지니어)
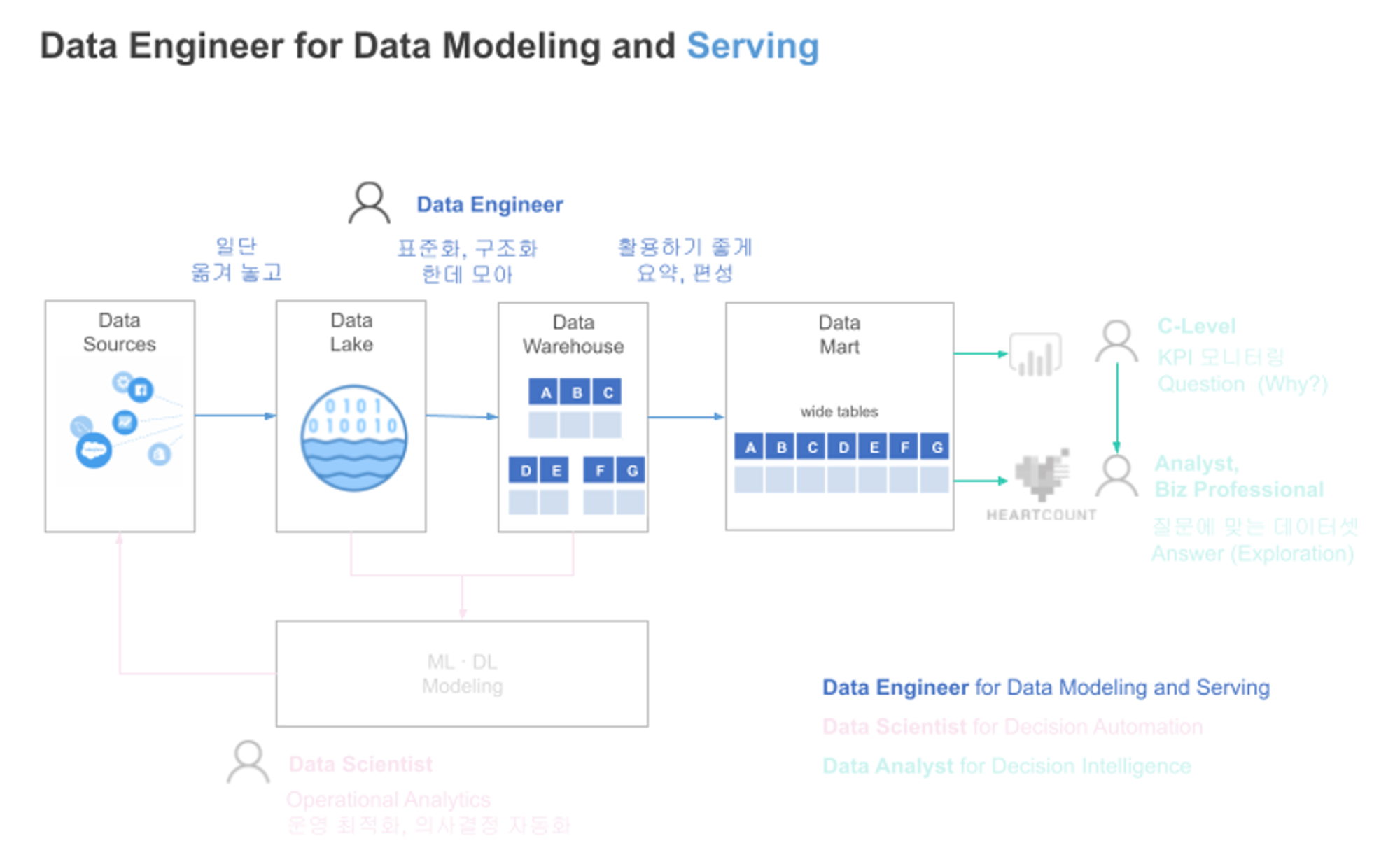
데이터 엔지니어는 분석가나 현업이 데이터를 활용하기 좋게 가공해서 제공하는 사람들입니다. 소스들로부터 데이터를 한 군데에 쌓고 다른 구성원들이 잘 활용할 수 있도록 가공 및 편성, 표준화 등의 작업을 하며 전체 시스템을 관리합니다. 이러한 과정에서 어떻게 효과적으로 수집하고 처리, 관리할지 고민하는 것도 주요 업무 중 하나입니다. 데이터 엔지니어는 DBA, S/W 엔지니어라고 불리기도 합니다.
2. 데이터에서 패턴과 현상을 발견해야 하는 Data Sceientist(데이터 사이언티스트)
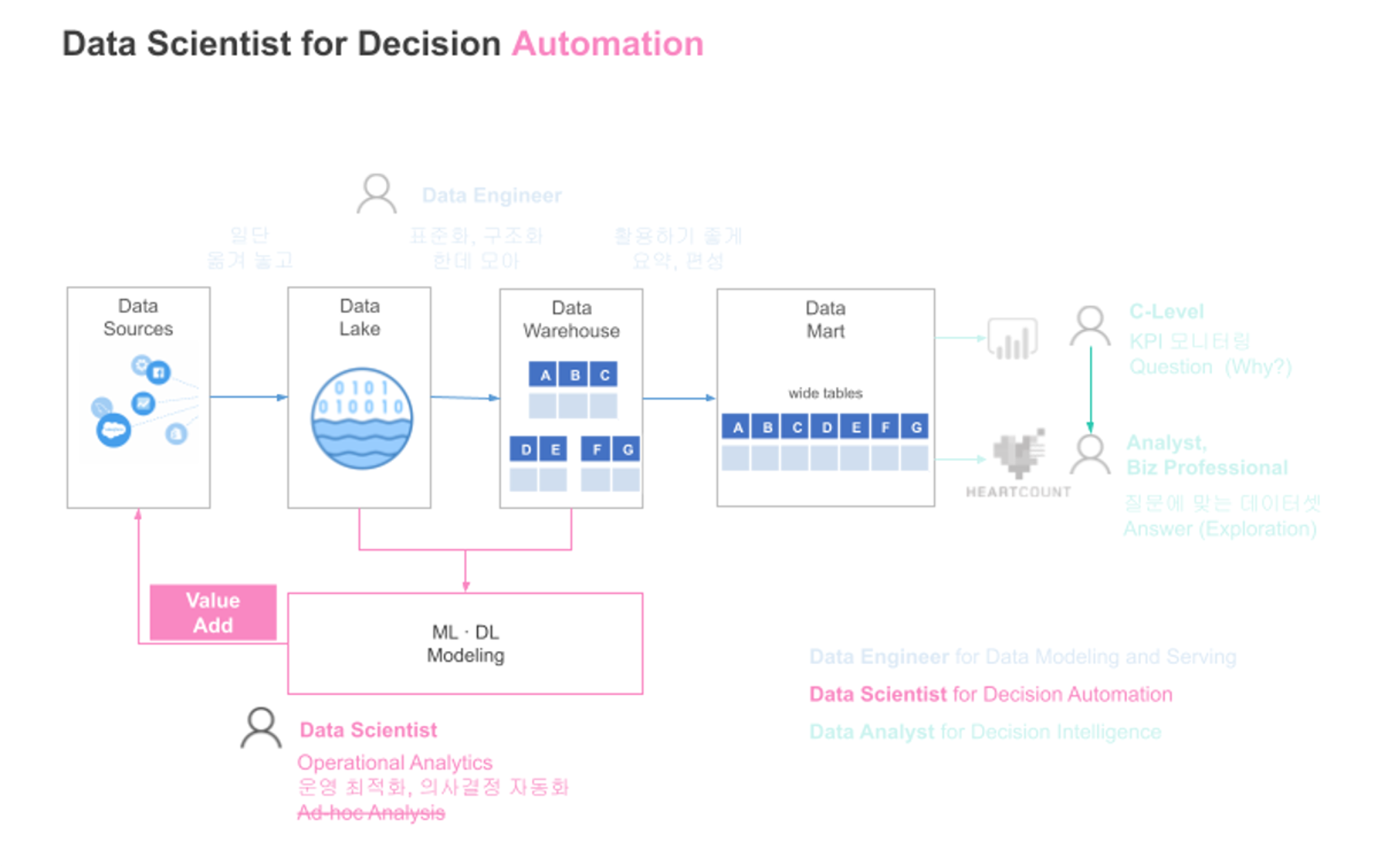
데이터 사이언티스트는 데이터에서 의미 있는 현상/패턴을 찾아내고 인사이트를 도출하는 사람들입니다. ML/DL Modeling 을 통해 '개인화/추천 알고리즘'과 같은 의사결정 자동화를 실현합니다. 전통적 CRM과 같은 운영 시스템에 모델링 결과, 예를 들면, 우리 제품 구매할 확률이 높은 고객을 점수화(lead scoring)해서 보내서, 운영 시스템을 지능화하는 operational analytics과 같은 작업도 주요 업무입니다.
3. Why에 대한 Answer를 찾아야 하는 Data Analyst(데이터 분석가)
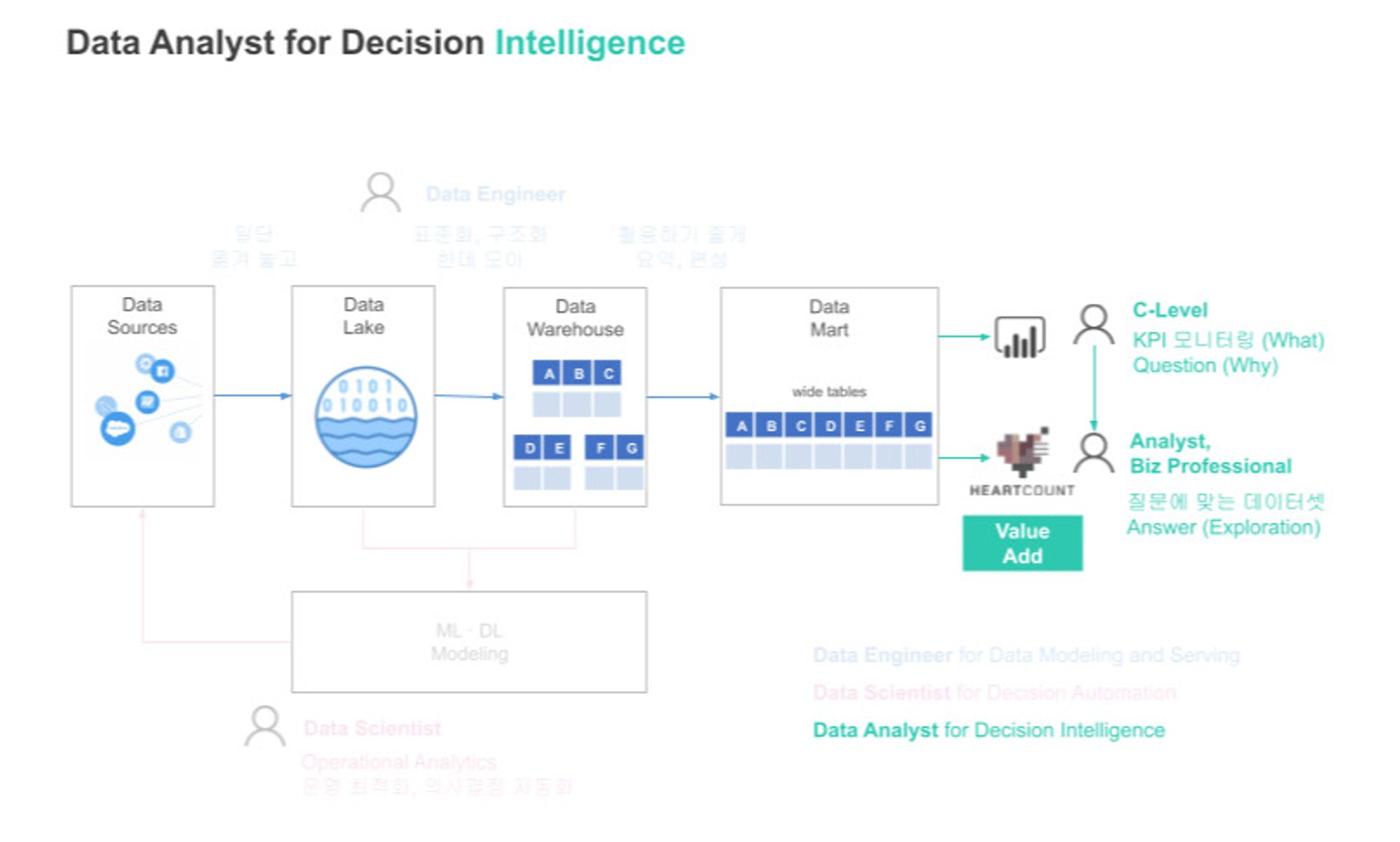
데이터 분석가는 조직의 Decision Intelligence를 돕는 사람들입니다. C-Level에서 주요 지표(KPI)를 보고 받고, 수치의 변화 이유를 물을 때를 위한 Data-Driven 답변, 관련 자료들을 준비하곤 합니다. 일반 현업들이 부탁하는 분석을 수행해주기도 하고, 새로운 프로젝트/제품 기획에 앞서 어떤 데이터를 수집할 것인지 정의하고 데이터 분석/시각화를 도맡아하는 등의 업무를 맡습니다. 데이터에서 인사이트를 발견해야 한다는 점이 데이터 사이언티스트와 유사하다고 볼 수 있습니다. 다만, 데이터 엔지니어/사이언티스트에 비해 더 비즈니스와 직접적으로 닿아 현업의 의사결정을 돕는다는 특징이 있습니다.
4. 데이터를 활용하는 현업 (ex. HR, Marketing, R&D 등)
데이터를 활용하는 직무에는 어떤 것이 있을까요? 우선 기획자는 서비스/프로젝트에 필요한 데이터를 정의하고 엔지니어와 사이언티스트/분석가에게 요청할 줄 알아야 합니다. C-level은 데이터를 활용하여 기업의 크고 작은 의사결정을 내릴 줄 알아야 하고요. 이외에도 고객 행동/매출 데이터를 활용하는 마케터, 구성원들의 데이터를 관리하는 HR, 연구원 등등이 있겠네요.
사실 데이터 드리븐 조직/데이터 민주화를 원한다면, 모든 구성원들이 이에 해당합니다.
"누구나 주체적으로"
1. 자신에게 어떤 데이터가 필요한지 정의하고,
2. 해당 데이터에 접근,
3. 분석 및 시각화하여
4. What(팩트/요약 정보), Why(요인) 그리고 How(전략)의 답을 찾고
5. 이를 보고/의사 결정에 활용할 줄 알아야 하는 것이죠(수집과 가공은 데이터 전문 인력들에게 맡긴다고 치면요..)
흔한 현실 (feat. “데이터가 너무 어려워요.”)
하지만 냉혹한 현실에서는, 현업들은 너무 바쁘고 동시에 데이터 분석은 너무 어렵습니다. 그렇기 때문에 다른 실무자들보다 상대적으로 데이터(혹은 분석 툴)를 더 잘 다루는 사람들을 지칭하는 직무들(데이터 마케터/퍼포먼스 마케터, 데이터 기획자 등)이 등장하고 있는 것이죠.
회사에서는 누구나 데이터를 활용하는 인프라를 만들어주기 위해 다양한 대시보드/BI 툴 등을 도입하고 있지만 사실 BI는 KPI에 대한 요약값(What)만 제공, 왜(Why) 성과지표가 변했는지, 어떻게(How) 최적화할 지에 대한 답을 주지 못합니다.
BI의 한계를 아래와 같이 정리할 수 있겠습니다.
현업들이 본인의 가설(질문)을 자유롭게 시각적으로 검증 가능, 하지만
•
Why, How에 대한 정보없이 과거에 대한 요약(What Happened) 정보만 제공
•
패턴 발견에 현업의 가설(수동 분석)에 전적으로 의지, 뻔한 패턴 발견에 머뭄
•
IT 의존도는 줄게 되지만 고급 분석을 위해서는 여전히 분석전문가 도움 필요
참고) 관련 내용을 중점적으로 다룬 아티클 : https://brunch.co.kr/@bef6d2c23e1c413/40
데이터 민주화로 가는 지름길, Self-Service Analytics
그렇다면 현업이 데이터 분석/모델링/통계학 등..에 대한 깊은 조예 없이도 쉽게 Why와 How에 대한 정보도 얻을 수 있는 방법은 무엇일까요? 셀프 애널리틱스 툴과 함께라면, 현업들은 기초적인 지식만 익히면 궁금한 것을 질문하고 탐색하고 결과를 활용할 수 있습니다.
다만, 셀프 애널리틱스 툴을 효과적으로 활용하기 위해서는 한 곳에 잘 정리된/유의미한 데이터셋 그리고 현업 스스로 다양한 관점으로 분석하고 해석하기 위한 기초적인 관련 지식이 필요합니다. 현업 수준에서 필요한 데이터 분석 기초 체력을 길러주기 위해서, HEARTCOUNT(하트카운트)에서는 자체 커뮤니티/무료 교육 캠프를 운영하고 관련 콘텐츠들을 발행하고 있습니다. 누구나 온라인상으로 self-paced 학습이 가능하니 관심이 있다면 아래 링크들을 참고해보세요.
현업에게 추천하는 통계학 기초 강의 :
https://youtube.com/playlist?list=PLFLxlucxymo8U4rsTM-D_NpgSq9M9RdIL
누구나 쉽게, 엑셀 데이터를 업로드하여 분석할 수 있는 데이터 시각화 및 자동 분석 솔루션 하트카운트의 특장점은 아래와 같습니다 :)
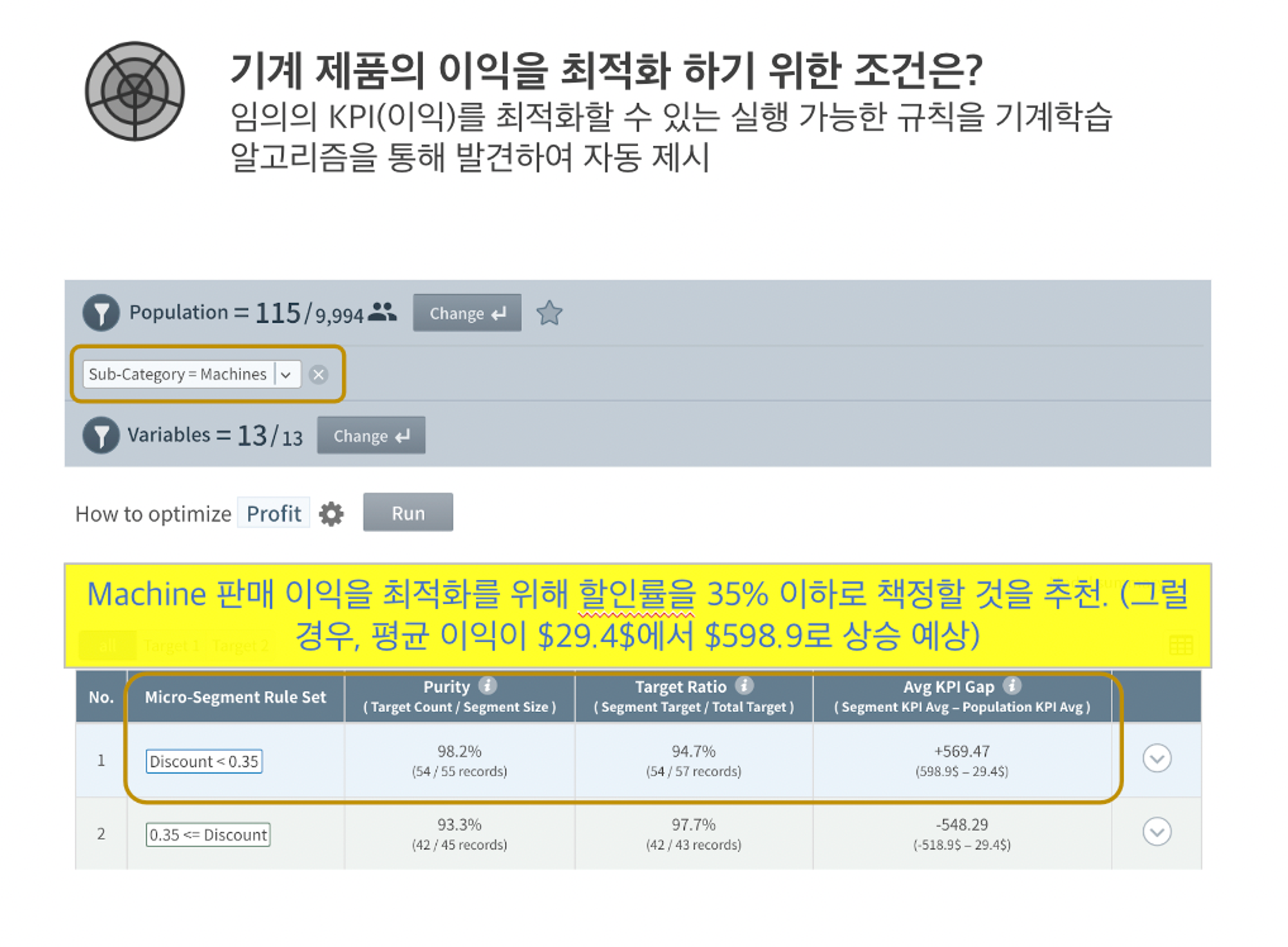
실무자가 과거 매출 데이터를 분석한다고 가정한다면,
데이터 분석가 도움없이도 주요 상품군별 성과 지표 최적화 전략을 아래와 같은 방법으로 수립할 수 있습니다.
•
Monetization Opportunity: 이익을 높일 수 있는 뻔하지 않은 판매 조건 발견
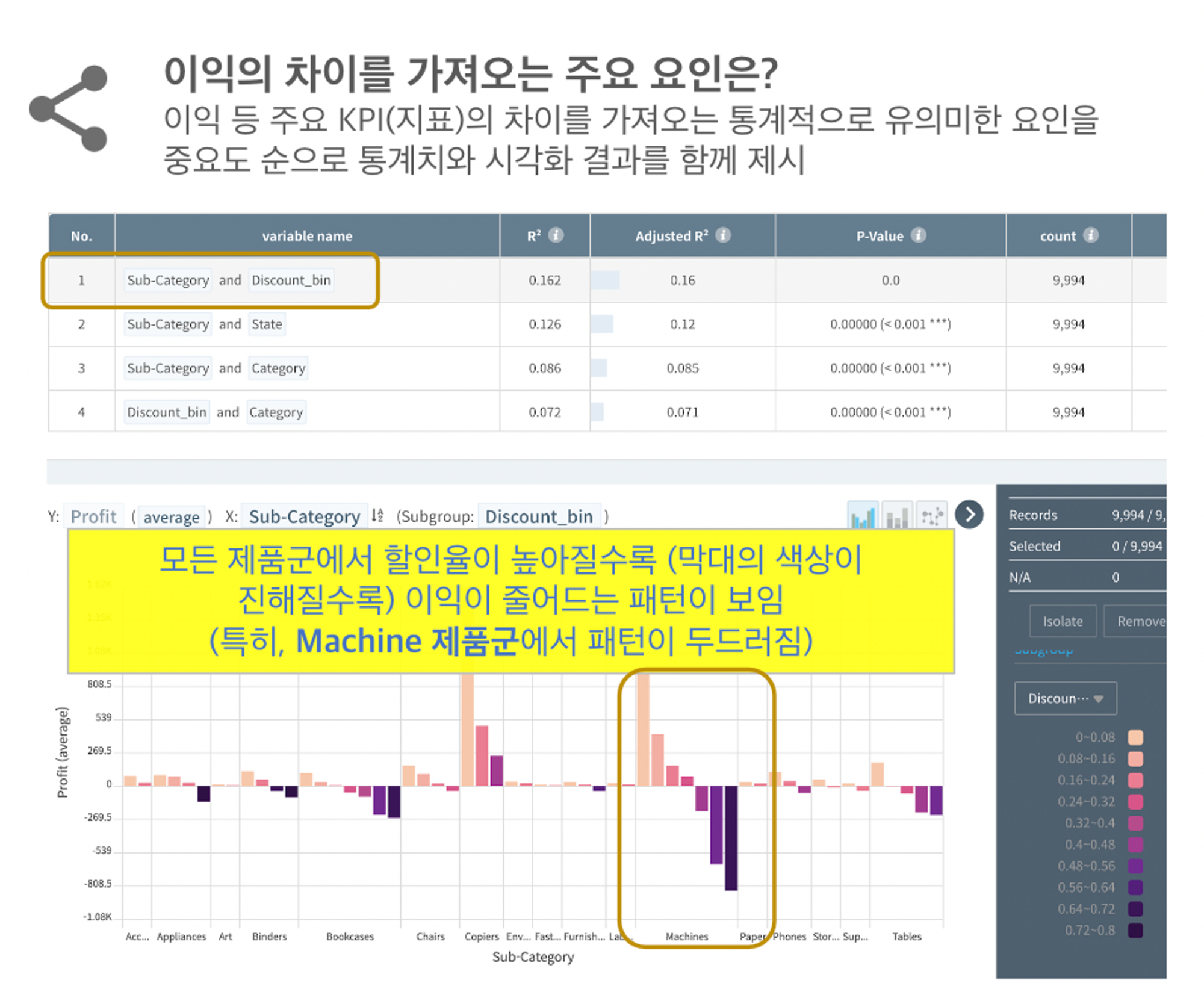
•
Focus on Key Factors: 이익 차이를 가져오는 핵심 요인에 대한 이해
•
Performance Metrics Optimization: 이익 최적화를 위한 타겟팅 전략 수립