
때로는 대시보드만으로는 부족하다
전통적인 대시보드 레벨의 데이터 시각화 및 분석은 시간의 흐름에 따라 각 회사의 상황에 맞추어 미리 정의된 지표들의 추이를 확인하기 위한 목적성을 지니고 있다. 예를 들어 제품별 재고율의 월별 추이, 팀별 평균 판매량 비교 등이다. 추이의 변화를 확인하는 것만으로도 때로는 유의미한 데이터 분석이 될 수 있다. “너희 팀 원래는 이 정도는 했었는데 이번 달은 왜 그래?” 같은 이상 징후들을 빠르게 포착할 수 있다는 말이다.
그러나 대시보드에서 사용하는 집계 수준의 데이터는 “하나의 점으로 뭉뚱그려진" 값이다. 예를 들면 “월별 각 직원의 판매량 평균" 같은 것이 되겠다. 물론 판매량 평균값도 의미 있는 정보를 담고 있을 수 있지만, 평균을 구성하고 있는 개별 판매량들에 대한 정보를 명확하게 식별할 수는 없다.
숫자와 대시보드를 들여다보는 사람 입장에서는 단순히 “월별 평균 판매량이 감소 추세에 있다"를 알고 싶은 것이 아니다. 그것만 보고 싶은 거라면 굳이 비싼 돈을 들여서 대시보드를 구축하고 시간을 들여 숫자를 쳐다보고 있을 필요가 무엇인가. 결국에는 “뭐 때문에 판매량이 줄었는지"를 알아서 내 비즈니스에 당면한 문제를 해결하는 것이 목적일 것이다. 따라서 개별 레코드 단위(월별 평균 판매량을 구성하는 각 직원의 판매량 등)의 데이터를 심도 있게 들여다보아야 비로소 숫자에 대해 잘못된 해석을 방지하고 데이터로부터 유의미한 결론을 도출해 낼 수 있을 것이다.
평균이 왜곡하는 현실 세계
예를 들어 내가 맡아서 관리하는 실적이 유사한 두 팀 A, B가 있다고 하자. 두 팀 모두 100점 만점에 월평균 80점 정도의 실적(그 실적이 무엇이든 간에)을 내고 있다고 하자. 해당 월평균 실적이 표기된 대시보드를 보면 누구나 “두 팀이 월 평균 성과가 유사한 걸 보니 A팀이나 B팀이나 거기서 거기군. 이번 보너스 지급 때는 두 팀 다 각각 인당 30만원씩 줘야겠다" 등의 결론을 내릴 가능성이 있다. 하지만 실제 각 팀의 개별 직원 실적이 다음과 같았으면 어떨까?
각 팀 직원 # | 팀 A | 팀 B |
직원 1 | 80 | 90 |
직원 2 | 79 | 95 |
직원 3 | 79 | 92 |
직원 4 | 81 | 88 |
직원 5 | 81 | 35 |
평균 | 80 | 80 |
두 팀 모두 평균은 80점으로 같지만, B팀의 경우 전반적으로 A팀보다 좋은 성과를 내고 있음에도 불구하고, 팀 내의 말썽꾸러기(?) B-5 직원의 삽질로 인해 우리 팀보다 잘하지 못하고 있는 A팀과 동등한 취급을 받아야 하는 수모를 겪어야 하는 것이다. 오히려 이럴 때에는 팀 관리 시 B-5 직원에 대해서 개별적으로 다른 접근법을 취하고, 나머지 B팀 멤버들에 대해서 팀 A의 멤버들보다 더 좋은 보상을 해 주는 것이 좋을 것이다.
물론 위의 예시는 극단적이고 작위적이다. 하지만 집계와 추이에 집중하다 보면 이러한 실수는 언제든지 발생할 수 있다. 데이터 분석을 업으로 삼은 사람들 사이에서는 격언처럼 자리잡고 있는 문장이 있다. “평균만 보지 말고 분포를 봐라” 가 그것이다. 뭉뚱그려진 값이 아닌 개별 데이터들이 어떠한 위치에 있는지 그 분포를 확인해야 한다는 것이다.
HEARTCOUNT를 통해 간단히 해당 데이터를 시각화해보자. 대시보드에서 흔히 사용하는 바 차트를 통해 두 팀의 평균을 보면 다음과 같을 것이다.
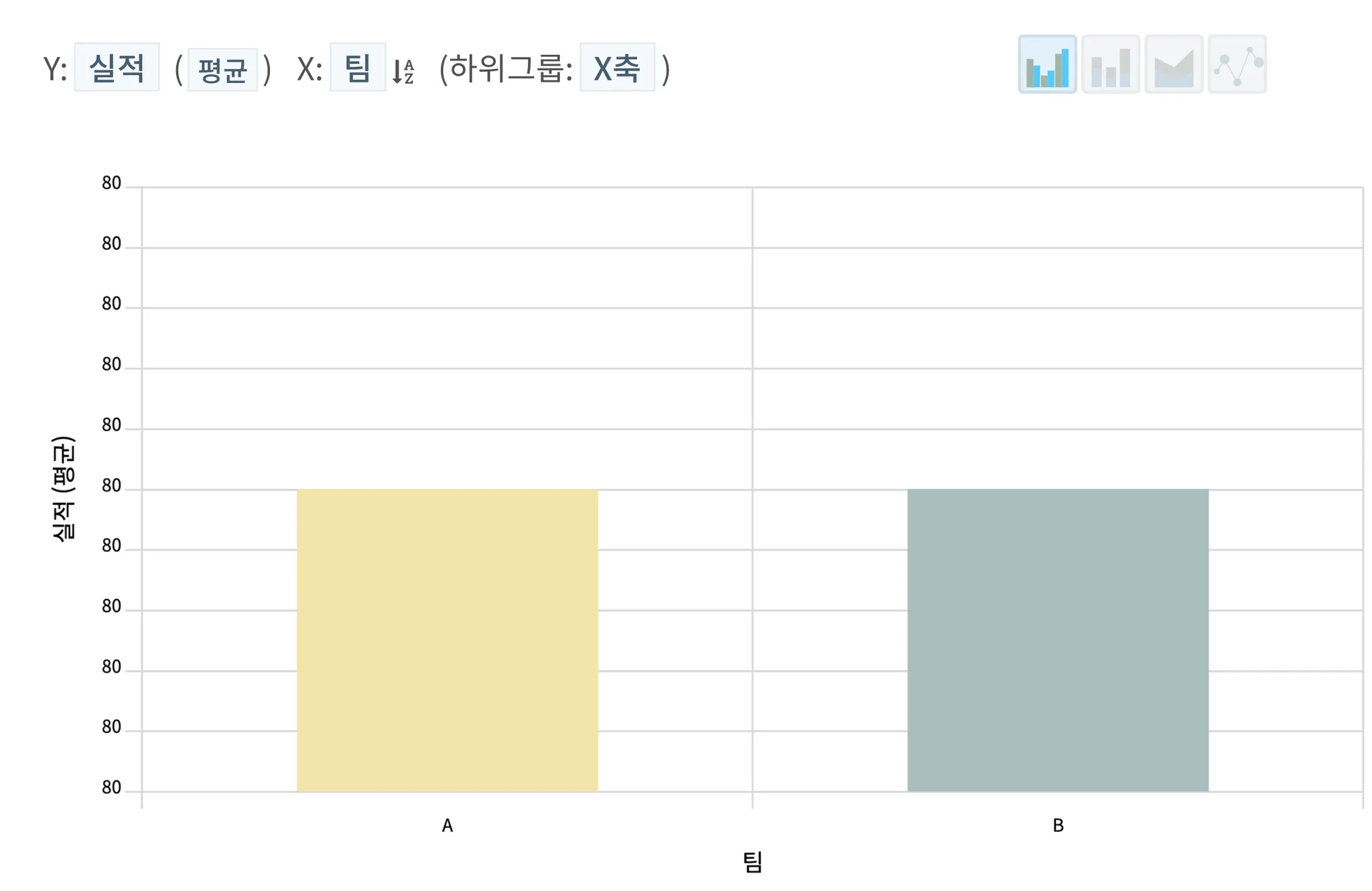
바 차트. 평균이 동일하니 각 팀의 실적 바의 높이도 동일하고 이런 경우 두 팀이 유사하다는 결론을 내리기 쉽다.
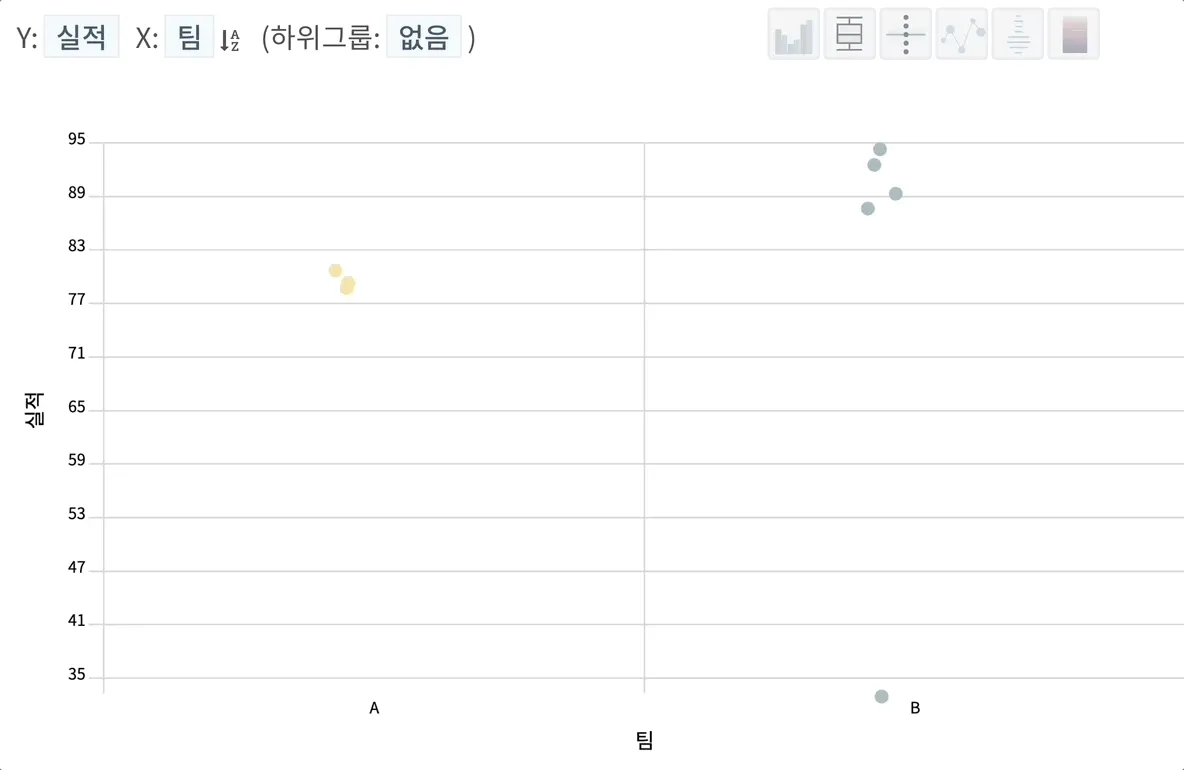
하지만 각 개별 데이터를 살펴보면 어떨까? HEARTCOUNT에서는 각 개별 레코드(행)을 각각의 점으로 나타내는 산점도를 빠르게 그려볼 수 있다.
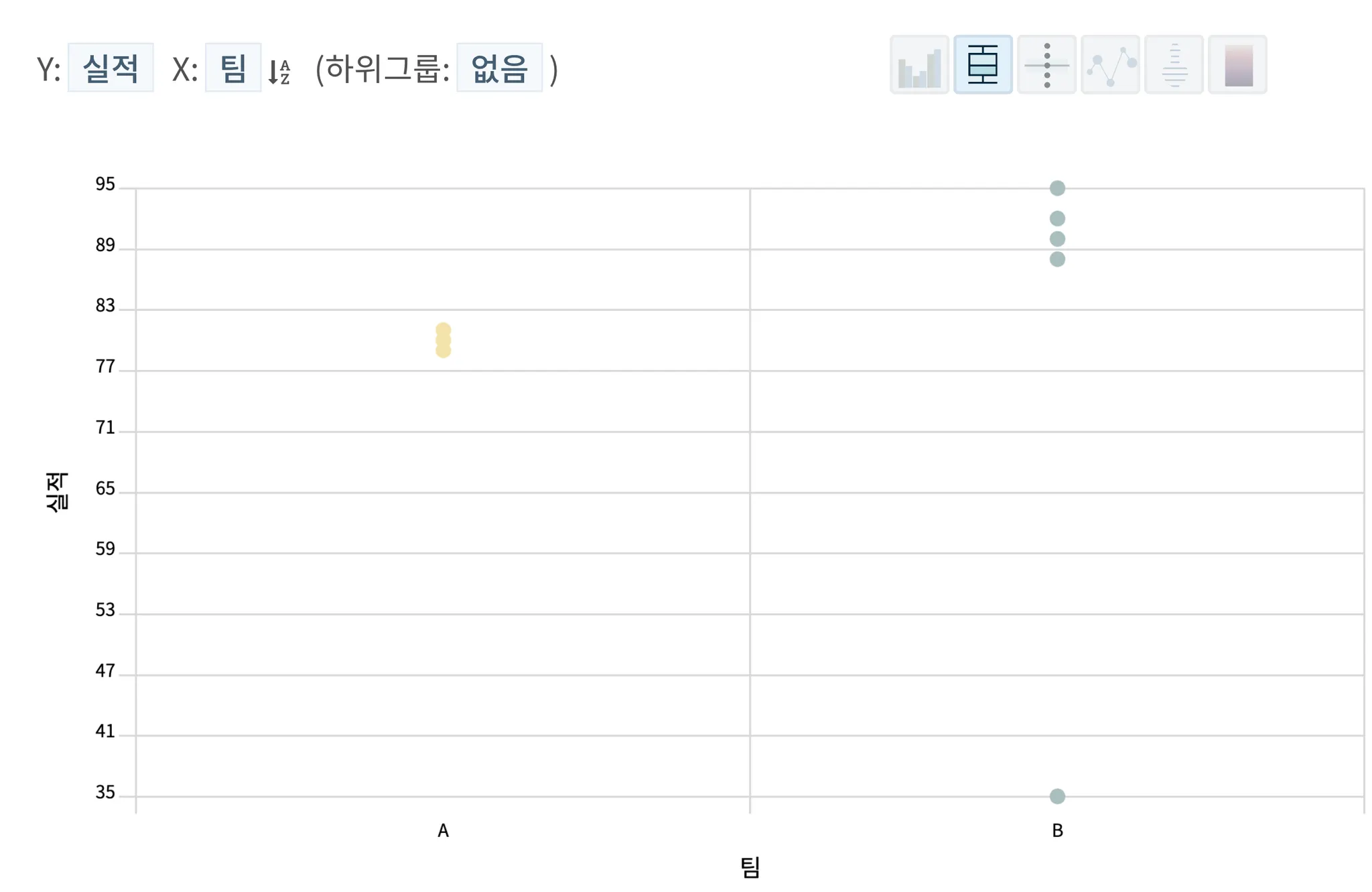
평균 수준에서는 동일하던 데이터가 개별 데이터로 보았을 때는 완전히 다른 양상을 보이게 된다.
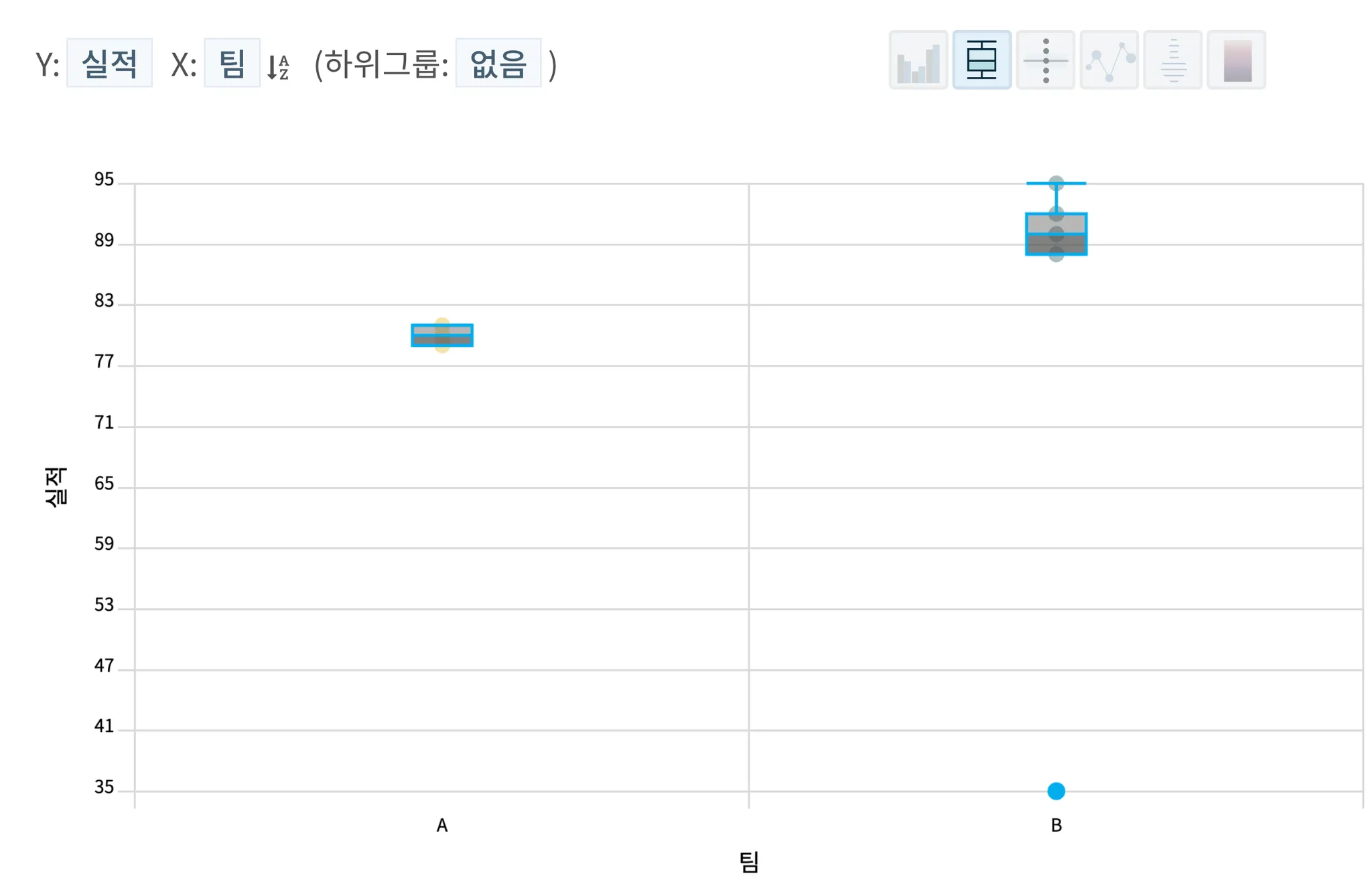
또한, HEARTCOUNT의 스마트 플롯에서는 박스플롯을 활용해 분포를 확인할 수 있다. 그리고 각 박스를 클릭하면 각 팀 A,B의 통계 정보를 확인할 수 있다. 두 팀은 평균은 같아도 중앙값(각 팀 직원들을 실적 점수별로 줄을 세웠을 때 중간에 위치한 직원의 점수)에는 분명한 차이가 존재한다.
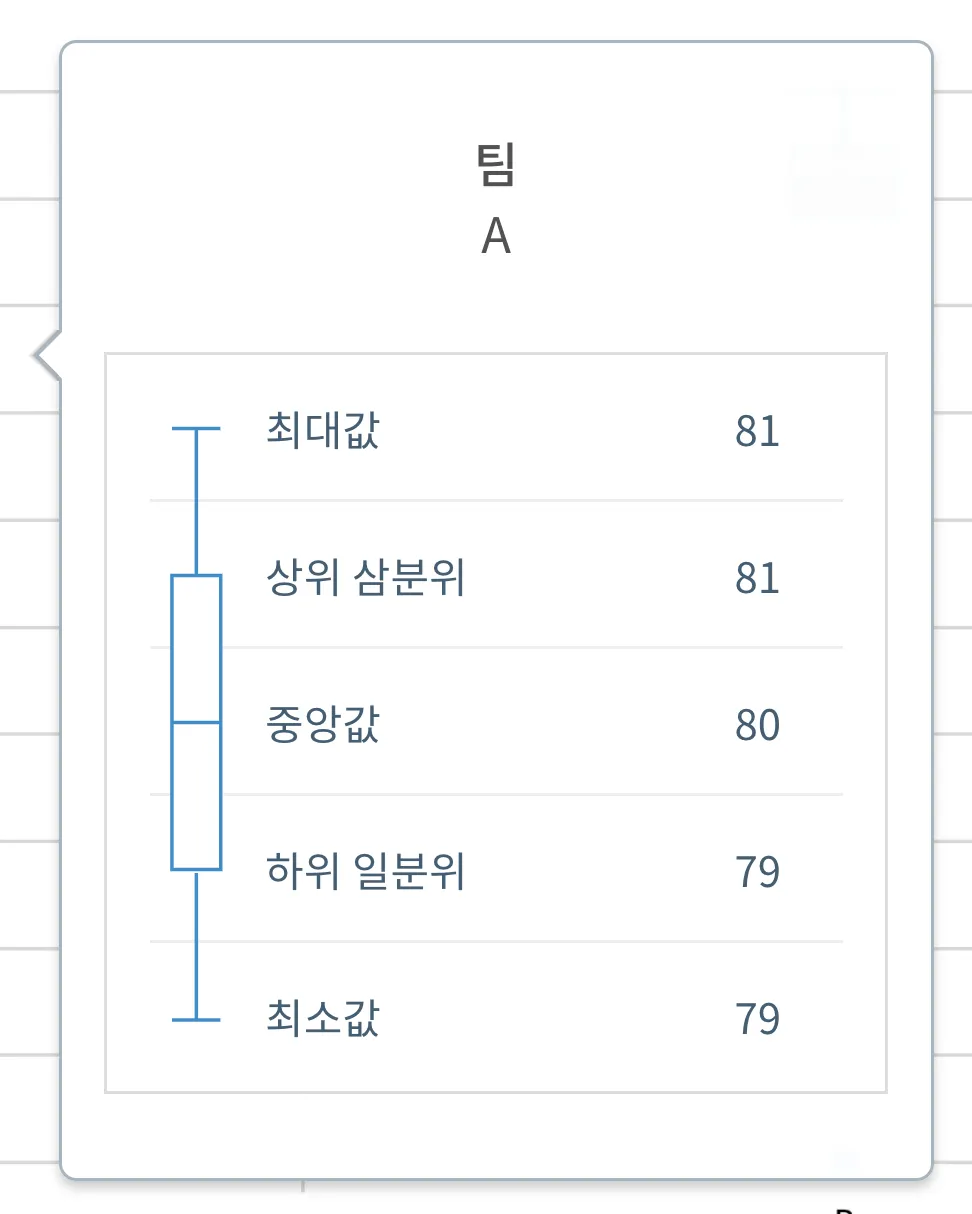

이처럼 개별 데이터를 보기 시작하면(그리고 때로는 평균이 아닌 다른 통계량에 관심을 가지기 시작하면) 평균 수준에서는 보이지 않던 유의미한 정보를 찾을 수 있게 된다.
또한 평균값에 왜곡을 주던 B팀의 골칫거리(?) 직원 5를 드래그 및 제거할 수 있다. 이때부터는 평균값이 현실을 적절히 반영하는 좋은 지표가 될 것이다.
변수를 쌓을수록 현실과 가까워진다
그렇다고 무조건 직원 5가 “못된 직원"이라고 낙인찍을 수 있는 것일까? 단순한 실적 점수가 아닌 다음과 같은 변수가 있다고 하자. 각 직원이 담당하고 있는 업무의 평균 난이도를 1~5점으로 측정하여 우측에 새로운 열로 추가하였다.
각 팀 직원 # | 팀 A | 팀 B | 각 팀 직원 # | 팀 A | 팀 B | |
직원 1 | 80 | 90 | 직원 1 | 3 | 1 | |
직원 2 | 79 | 95 | 직원 2 | 3 | 2 | |
직원 3 | 79 | 92 | 직원 3 | 2 | 2 | |
직원 4 | 81 | 88 | 직원 4 | 4 | 2 | |
직원 5 | 81 | 35 | 직원 5 | 3 | 5 | |
평균 | 80 | 80 | 평균 | 3 | 2.4 |
알고 보니 팀 B의 직원 5는 팀 내에서 어려운 일만 도맡아 하는 사람(예를 들면 판매량으로 치면 애초에 성과를 내기 어려운 target customer들만 골라서 판촉업무를 하고 있었다든지)이었고, 자연스레 실적이 낮아질 수밖에 없는 상황이었다. 해당 직원으로서는 “우리 팀 사람들은 본인들은 쉬운 일만 하고 나한테는 어려운 일만 시키더니 인제 와서 숫자만 보고 나보고 나쁜 놈이라고? 나도 쉬운 일 주던지!”라는 볼멘소리를 할 수 밖에 없는 것이다(물론 애초에 이 실적 점수가 업무 난이도 개념을 잘 반영하고 있었다면 이런 일도 없겠지만). 이런 경우에는 직원의 문제라기보다는 해당 팀을 관리하는 팀장의 업무 분배 실패로 인한 평균 왜곡 현상에 가까울 것이다.
HEARTCOUNT를 통해 개별 데이터 분석을 더 쉽게
이처럼 개별 데이터를 조금 더 자세히 들여다 볼수록 데이터를 해석하는 방식은 천차만별로 달라진다. 집계가 아닌 각각의 현상을 다양한 차원으로 보면 볼수록 데이터는 현실에 가까워지는 것이다.
세상은 하나의 변수(one-dimensional)로 설명할 수 없음에도, 대시보드는 많은 경우 “윗분들이 보시기에 편하다” 는 이유로 인해 자주 사용되지만 평균이라는 하나의 변수만 가지고 우리 회사의 복잡한 많은 현상을 설명하려 한다. 그러다 보니 상부에서는 “너네 이번달 실적 왜 이래"라고 아랫사람을 쪼고(?), 현장에서 실제로 업무를 하는 사람들 입장에서는 “대시보드에 있는 숫자만 쳐다보고 있는 윗사람들이 뭘 알겠어. 빅데이터 다 쓸 데 없네" 같은 이야기가 나오는 것이다.
기존에 개별 레코드 수준의 데이터를 분석하고 시각화하는 방법은 굉장히 다양하다. 문제는 “어디서부터 공부를 시작해야 할까?”이다. 학문의 영역에서는 통계학이, 툴의 영역에서는 전문적인 R, Python, SPSS, SAS 등이 이러한 질문들에 정답을 제공해주기는 한다.
전문적이고 일상적으로 데이터를 접하고 분석하는 사람들에게는 이러한 지식과 툴을 사용한 개별 데이터의 분석은 너무나도 당연한 일이겠지만, 대시보드 스타일의 엑셀 데이터 시각화에 익숙해진 대부분의 현실 직장인들은 어떻게 손을 대어야 할지도 모를뿐더러 절대적인 시간도 부족하다. 대부분은 퇴근하고 나서 하루의 피로를 풀기도 바쁘니 배우기 쉽지 않은 이러한 학문의 영역에 쉽사리 발을 들여놓지 못하게 된다.
HEARTCOUNT는 많은 것을 배우지 않고도 쉽고 직관적으로 데이터 분석을 하기 원하는 사람들에게 안성맞춤이다. 대시보드가 아닌 개별 레코드 수준의 데이터 분석을 HEARTCOUNT를 통해 수행해보기 바란다.
