Intro
안녕하세요. 저는 2016년도에 Expedia가 Kaggle에 공개한 데이터를 가지고 분석 및 시각화를 진행하였습니다. 사용한 데이터에는 2013~2014년에 Expedia를 이용한 유저들의 정보와 행동과 유저가 예약한 호텔 클러스터 ID가 저장되어 있습니다. Expedia에서 가격대, 별점, 위치 등등을 기반으로 비슷한 호텔끼리 묶어 ID를 부여하였는데, 이를 hotel cluster라고 합니다. Expedia는 어떤 유저가 어떤 hotel cluster에 있는 호텔을 예약을 하는지에 관심이 있었습니다.

Dataset
원본 데이터의 크기가 너무 커 분석을 하기에 어려움이 있으므로, 10만 row개의 데이터만 분리하여 사용하였습니다.
split -l 100000 train.csv
Bash
복사
시각화를 위해 파이썬에서 약간의 가공을 하였고, 원본에 없던 hotel_nights라는 값을 다음과 같이 추가하였습니다.
hotel_nights = pd.to_datetime(df["srch_co"]) - pd.to_datetime(df["srch_ci"])
df["hotel_nights_str"] = hotel_nights
hotel_nights_float = (hotel_nights / np.timedelta64(1, "D")).astype(float)
df["hotel_nights"] = hotel_nights_float
Python
복사
원본 데이터
사용한 데이터
Analysis in HEARTCOUNT
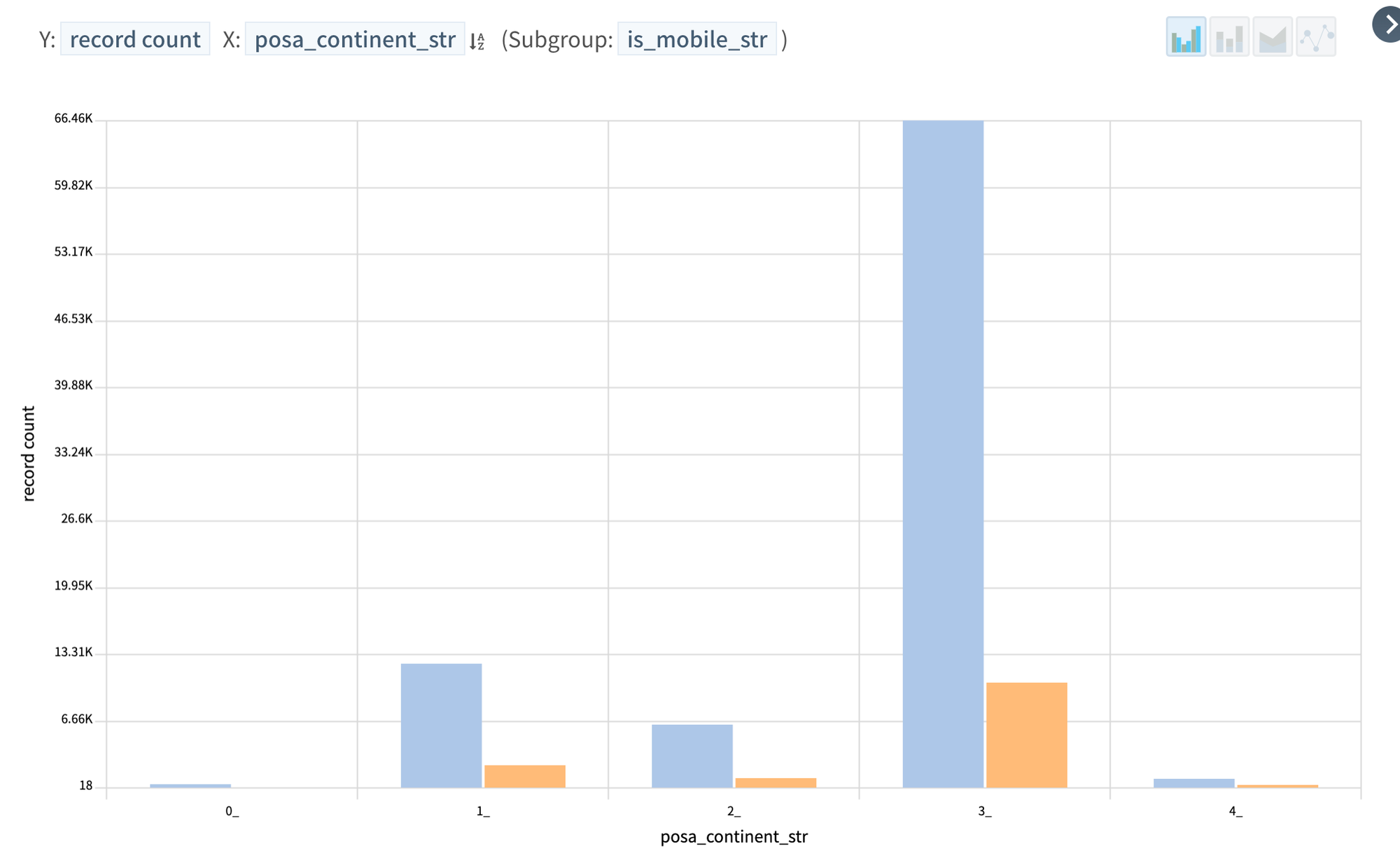
Preferred continent destinations
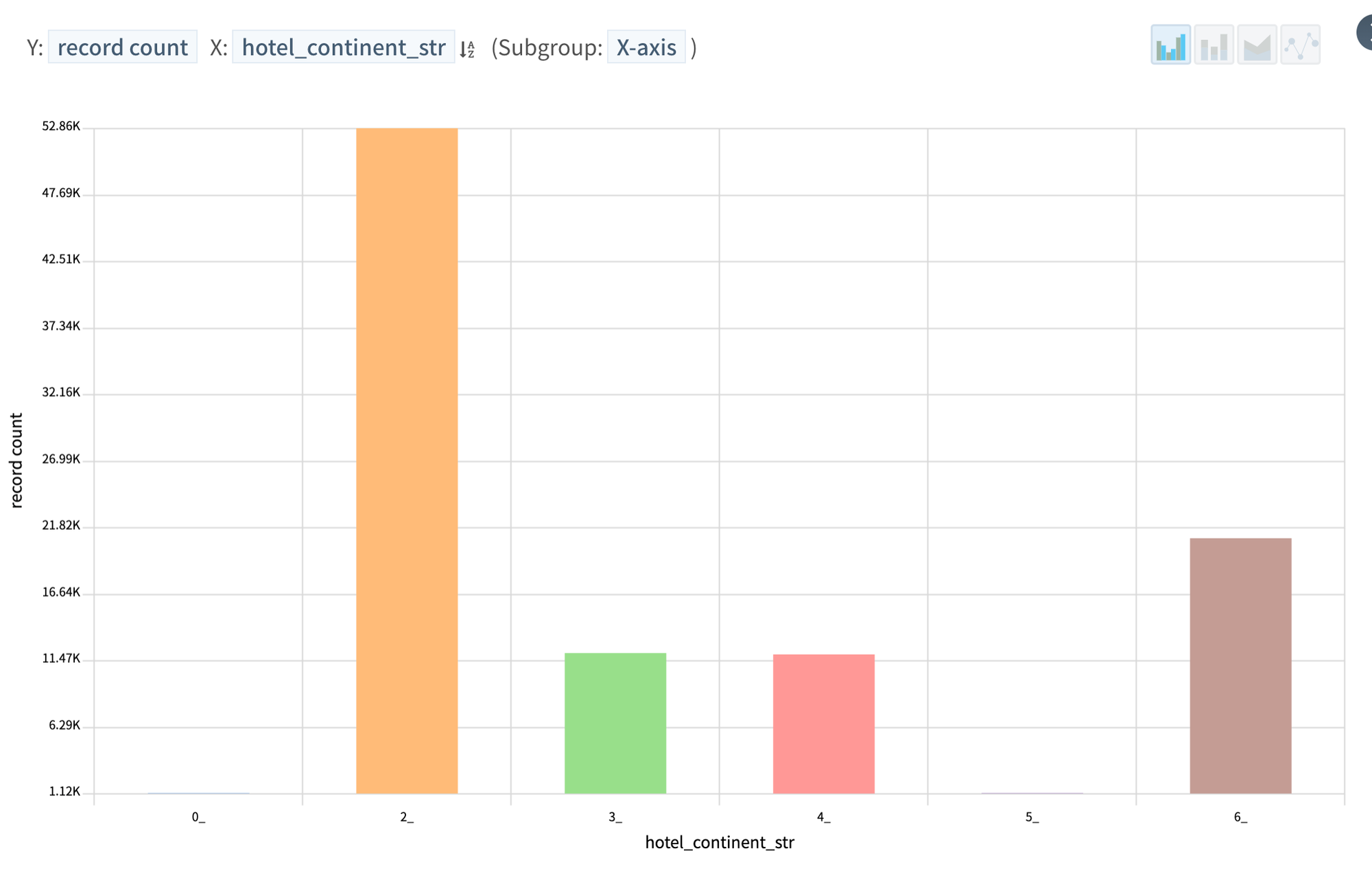
Most of people booking are from continent 3
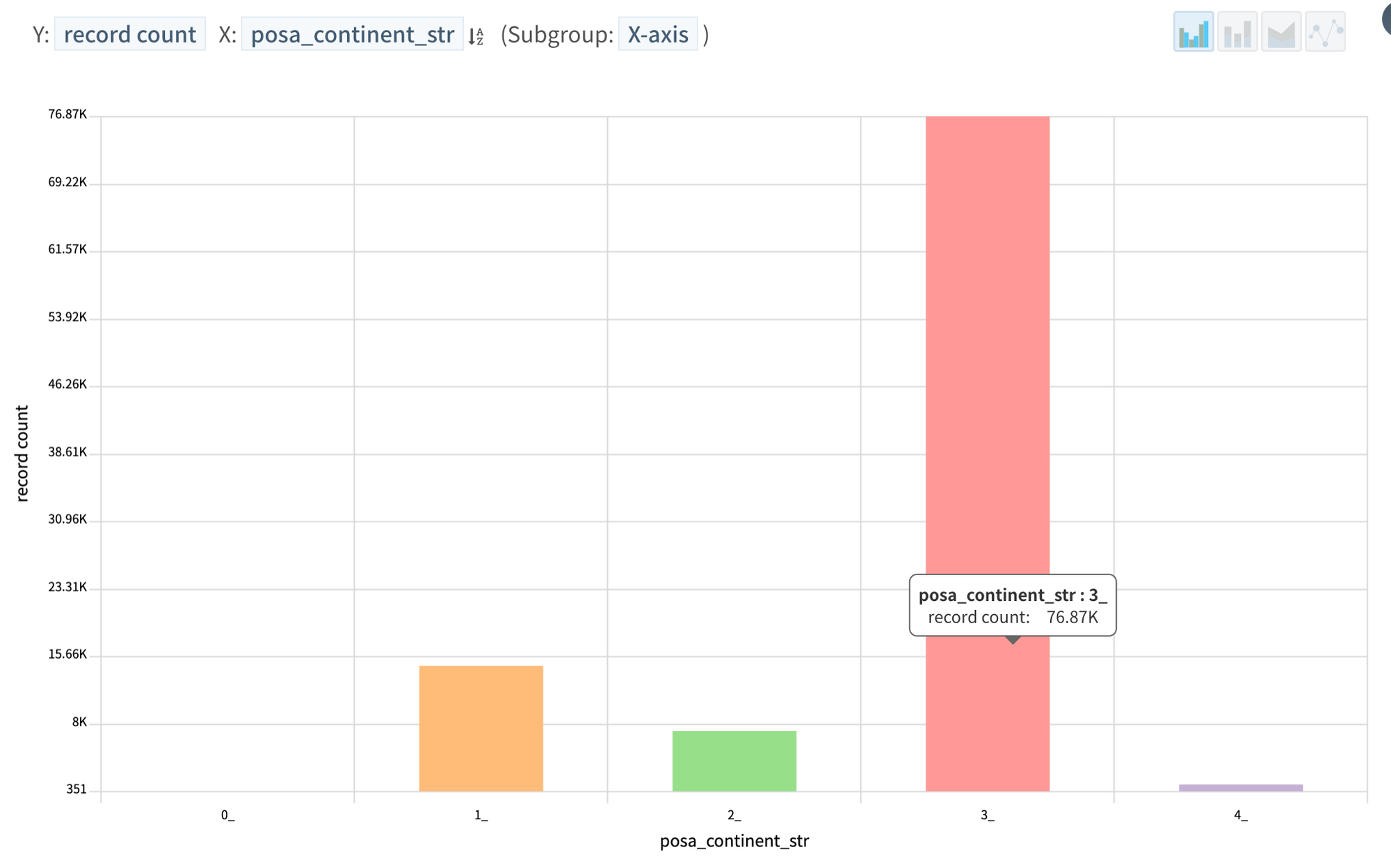
Putting the two above together
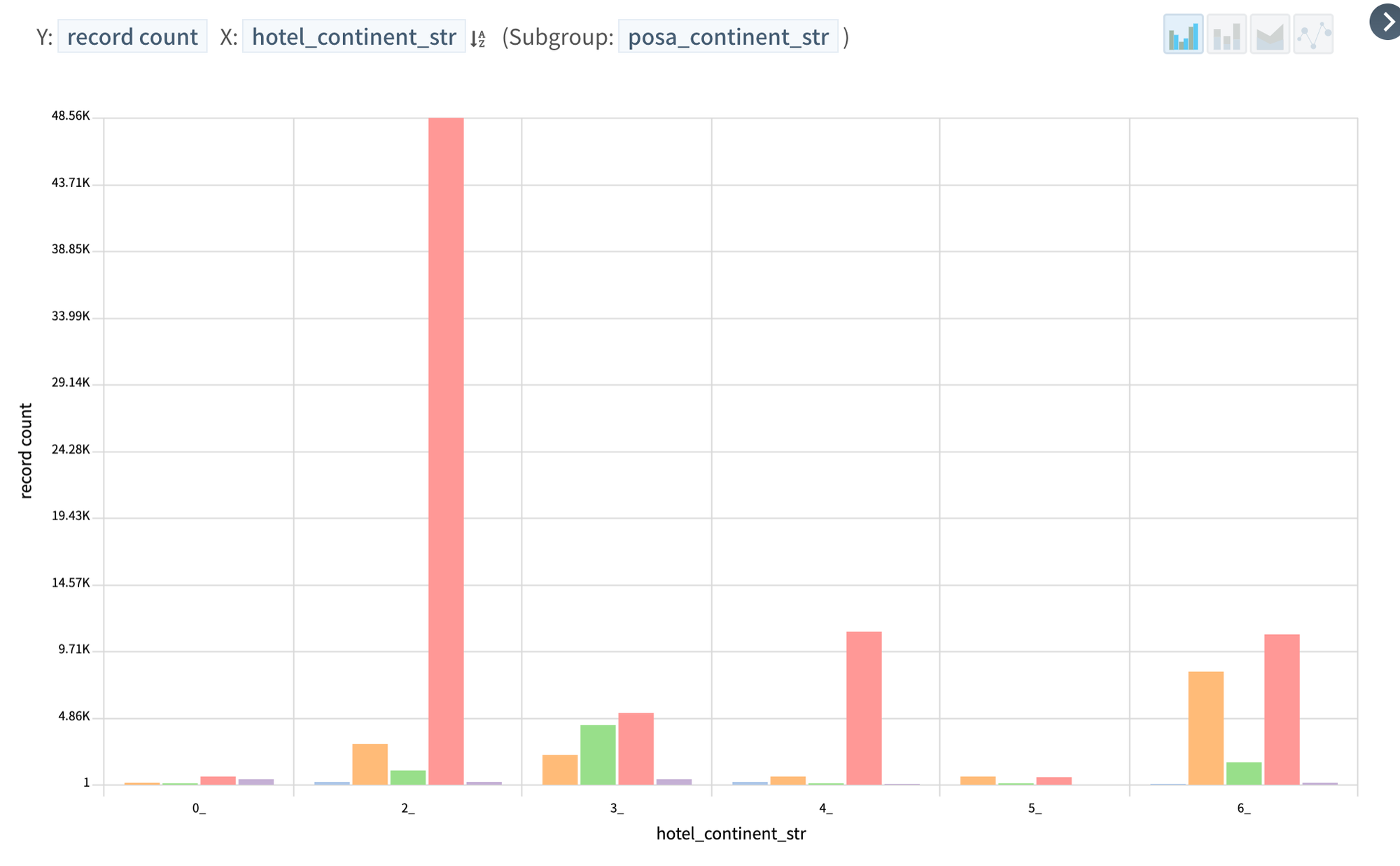
How many people by continent are booking from mobile
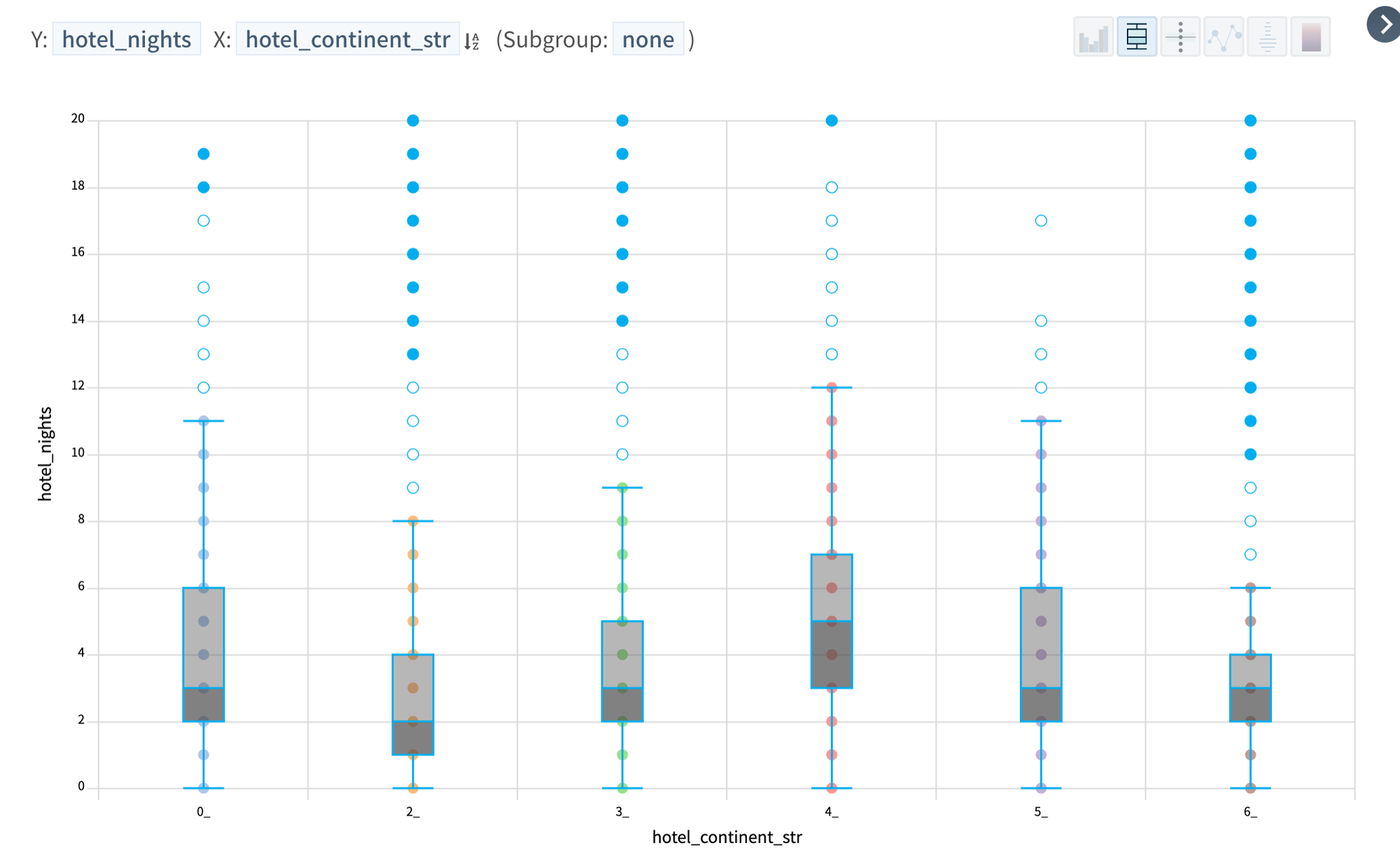
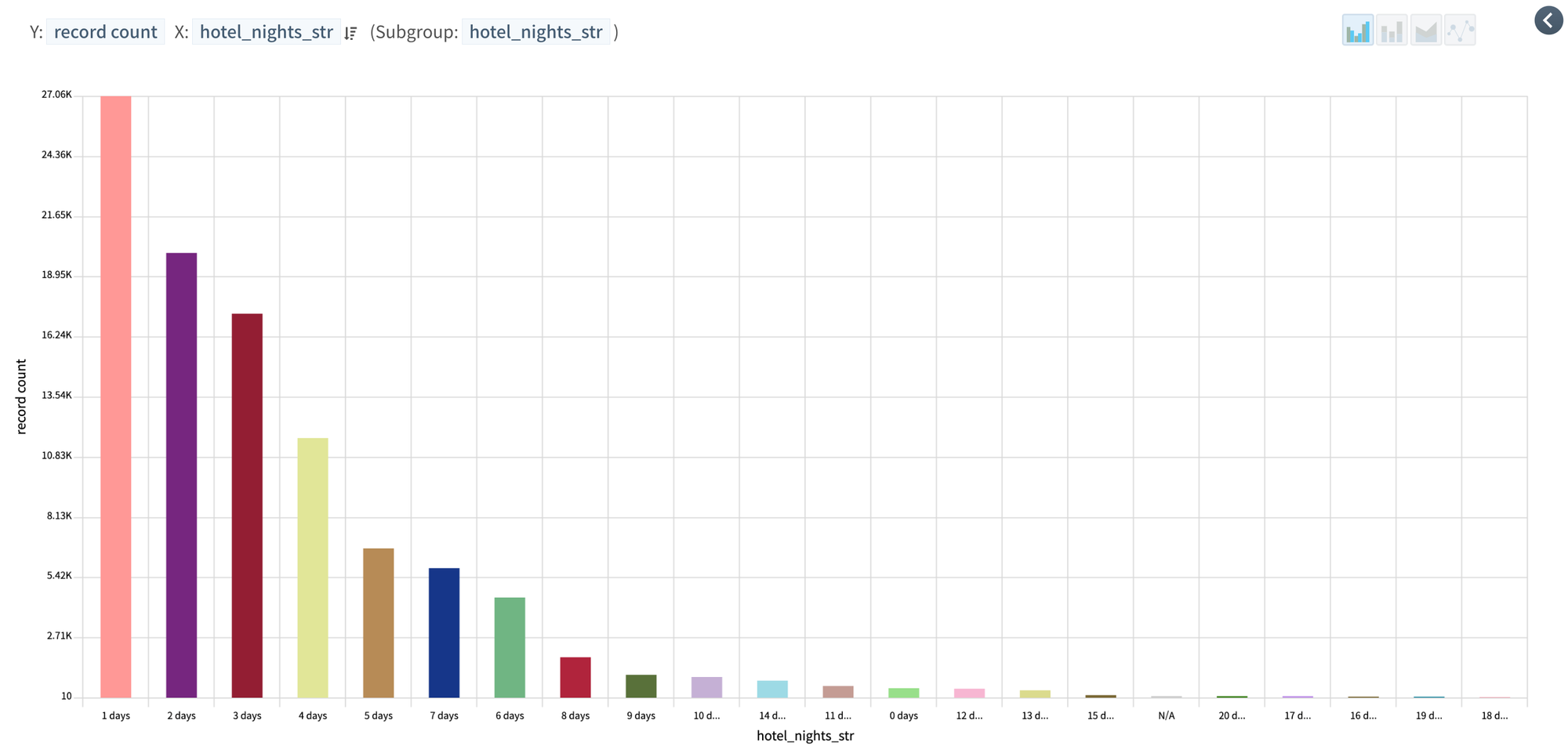
Number of booked nights as difference between check in and check out
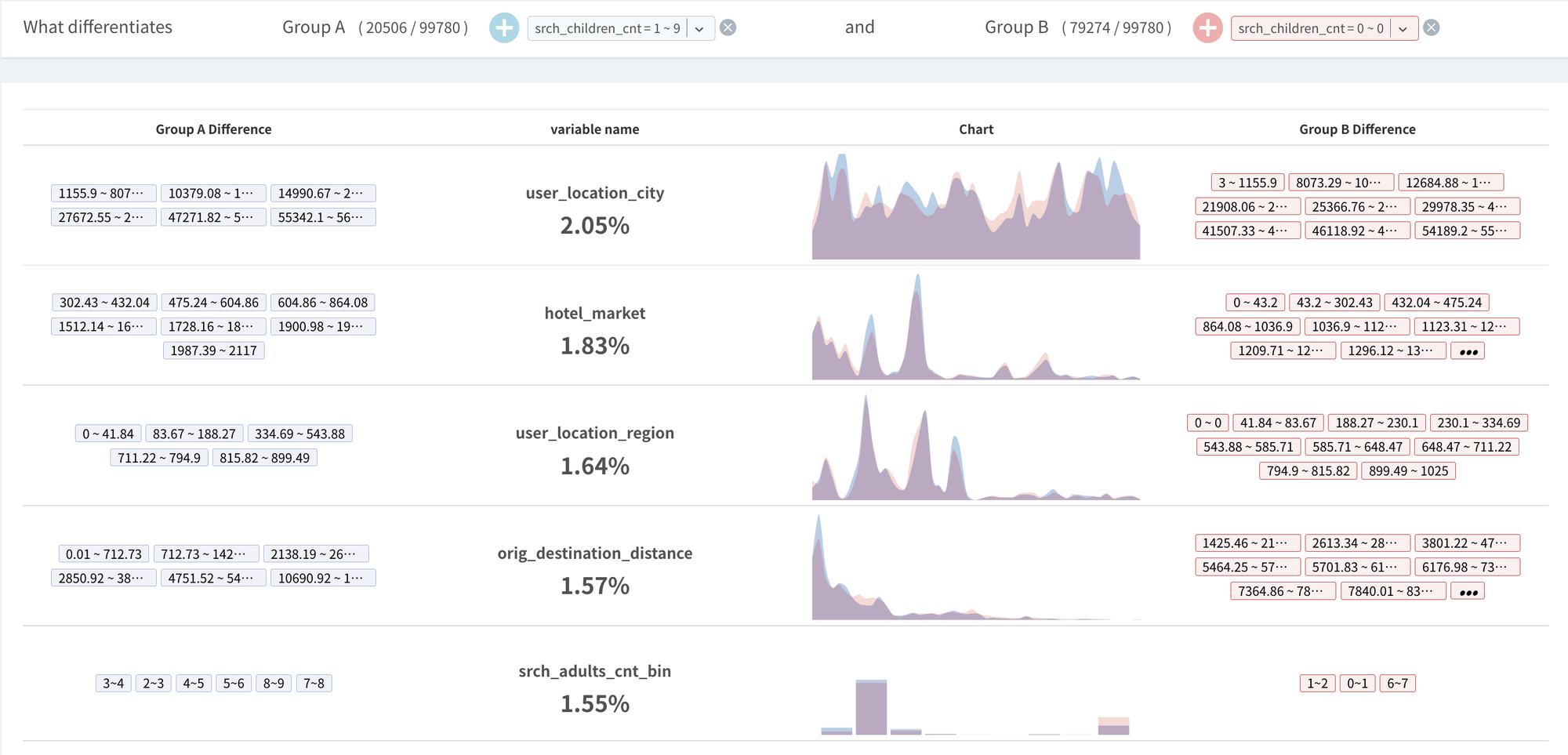
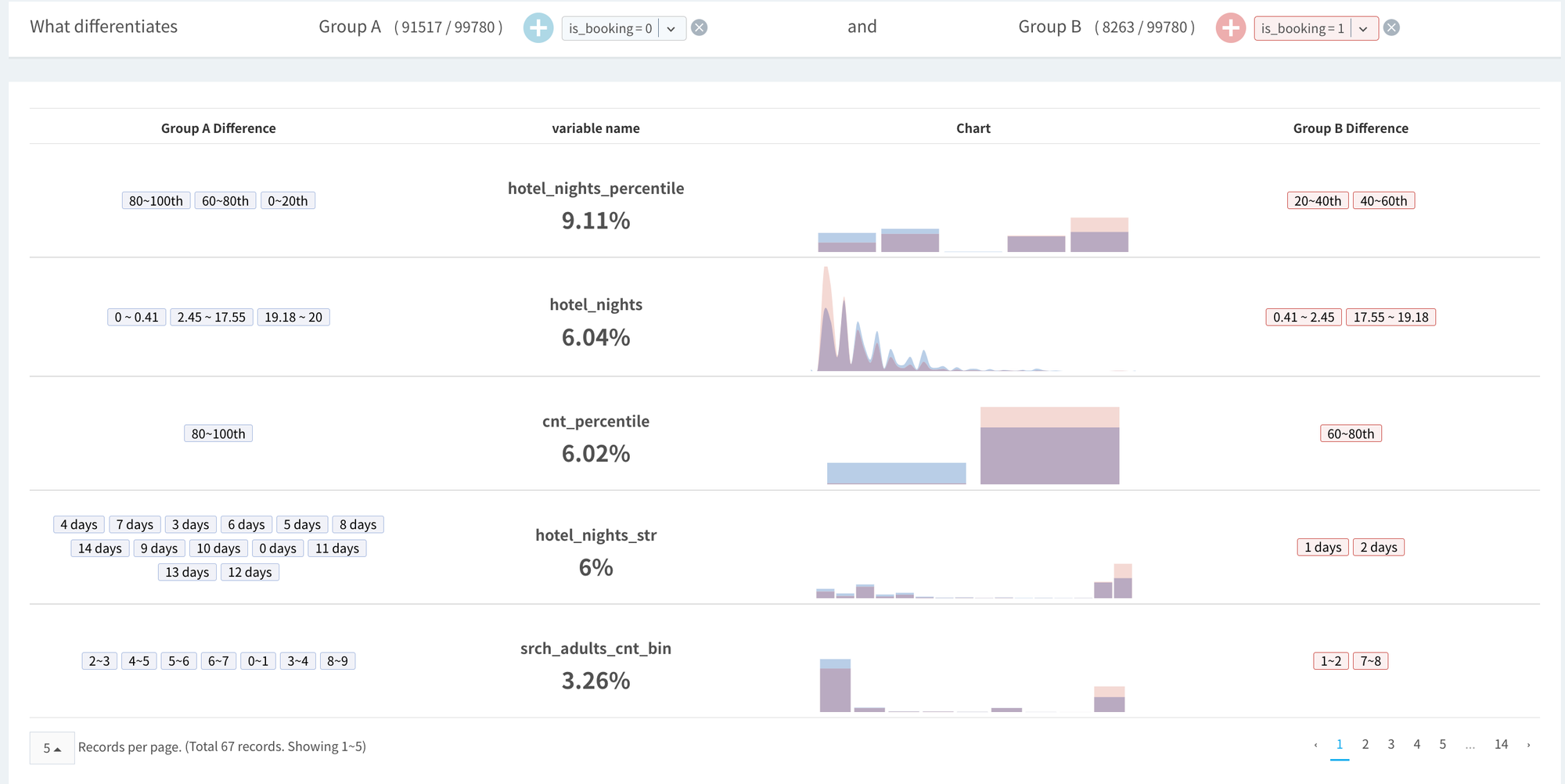
Difference Analysis: is booking
Difference Analysis: #children