
목차 (아래 챕터를 클릭하면 해당 챕터로 이동합니다.)
1.
2.
3.
4.
1. Intro
평소 소비자나 유저의 행동에 관심이 많아 행동에 관련된 데이터를 찾게 되었습니다.
데이터를 찾고 분석을 해야겠다고 마음먹은 데에는 최근 a/b 테스트를 공부를 한 것이 영향을 미친 것 같습니다. a/b 테스트 분석에서 UX(사용자 경험)에 집중하다 보니 이번 분석에서 유저의 행동에 더 집중하게 된 것 같네요. 
a/b 테스트를 공부하면서 결국 데이터를 통해 알고 싶은 건 “어떻게 될까?”(미래지향적) 보다 “뭐 때문에 그런 결과가 나올까?”(근본적)라는 것을 깊게 느끼고 있는 요즘입니다.
그렇기에 오늘 분석에서는 요즘 저의 최고 관심사인 “뭐 때문에 그런 결과가 나왔는지”에 대해, 하트카운트(데이터 인사이트 시각화 툴)을 이용하여 분석하는 시간을 갖도록 하겠습니다.
2. Dataset
데이터 출처 : 2020 행동 데이터 분석 인공 지능 대회
데이터 설명
대회에서 제공하는 데이터는 게임 플레이어의 행동 정보를 담고 있습니다. 이 데이터를 사용하여 게임에서 승리하는 선수를 예측합니다. 데이터는 5만여 개의 경기 리플레이 데이터로 이루어져 있으며, 각 리플레이 데이터는 총 경기 시간의 일부에 대한 인게임 정보를 포함합니다.
train.csv / test.csv
game_id | 경기 구분 기호 |
winner | player 1의 승리 확률 |
time | 경기 시간, 마침표(.)로 분과 초가 구분됩니다. ex) 2.24 = 2분 24초 |
player | • 0 : player 0
• 1 : player 1 |
species | • T : 테란
• P : 프로토스
• Z : 저그 |
event | 행동 종류 |
event_contents | • Ability : 생산, 공격 등 선수의 주요 행동
• AddToControlGroup : 부대에 추가
• Camera : 시점 선택
• ControlGroup : 부대 행동
• GetControlGroup : 부대 불러오기
• Right Click : 마우스 우클릭
• Selection : 객체 선택
• SetControlGroup : 부대 지정 |
3. Analysis in HEARTCOUNT
Data upload
하트카운트에서의 분석을 위하여 원본 데이터의 크기를 줄여야 했습니다.
파일 사이즈를 줄이기 위해 구글 코랩에서 해당 데이터에 대한 간단한 전처리 및 행 백만개를 랜덤으로 추출하는 샘플링을 진행했습니다.
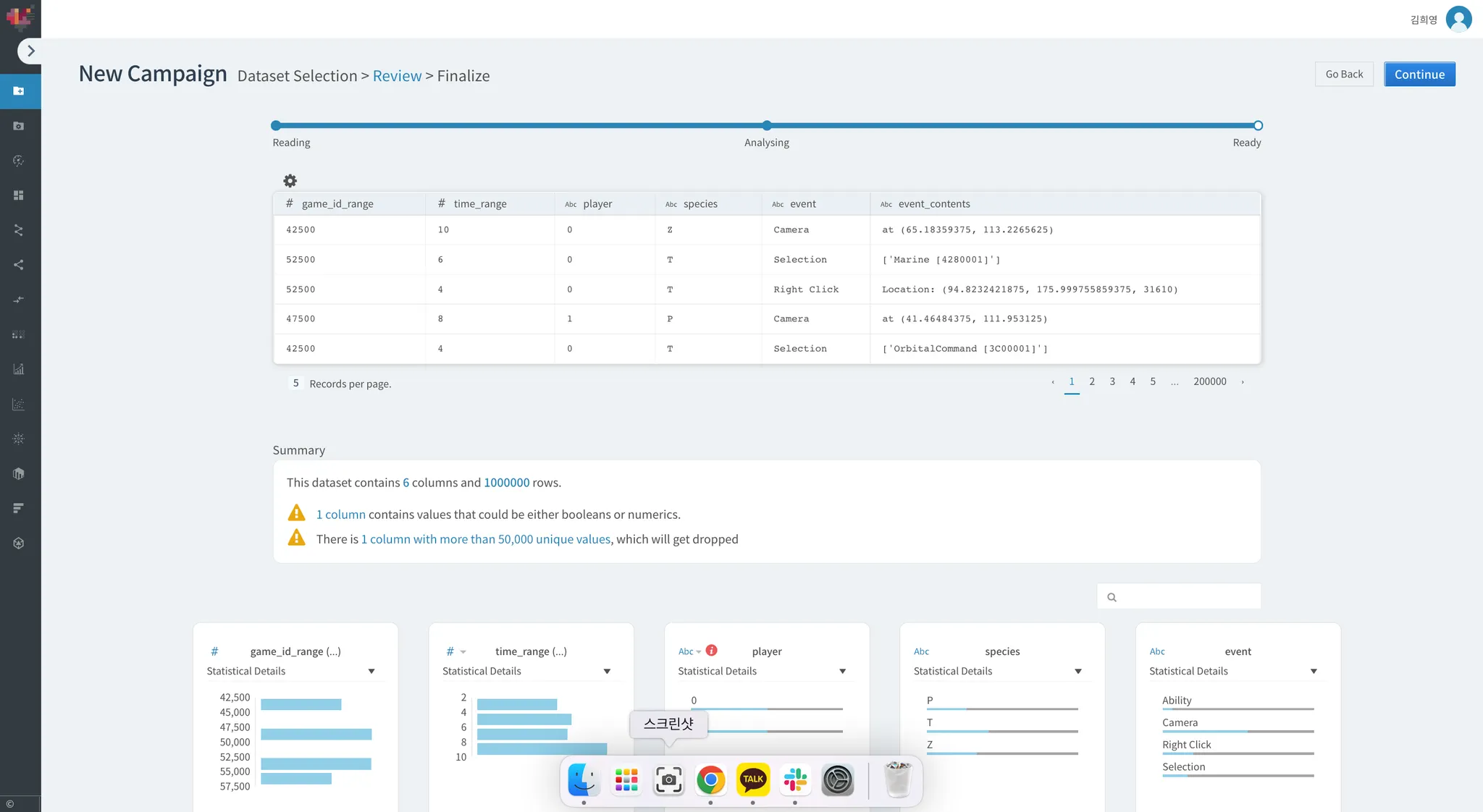
코랩에서 한 전처리 과정은 생략하고 하트카운트의 전처리 과정만 캡처본 첨부하겠습니다.
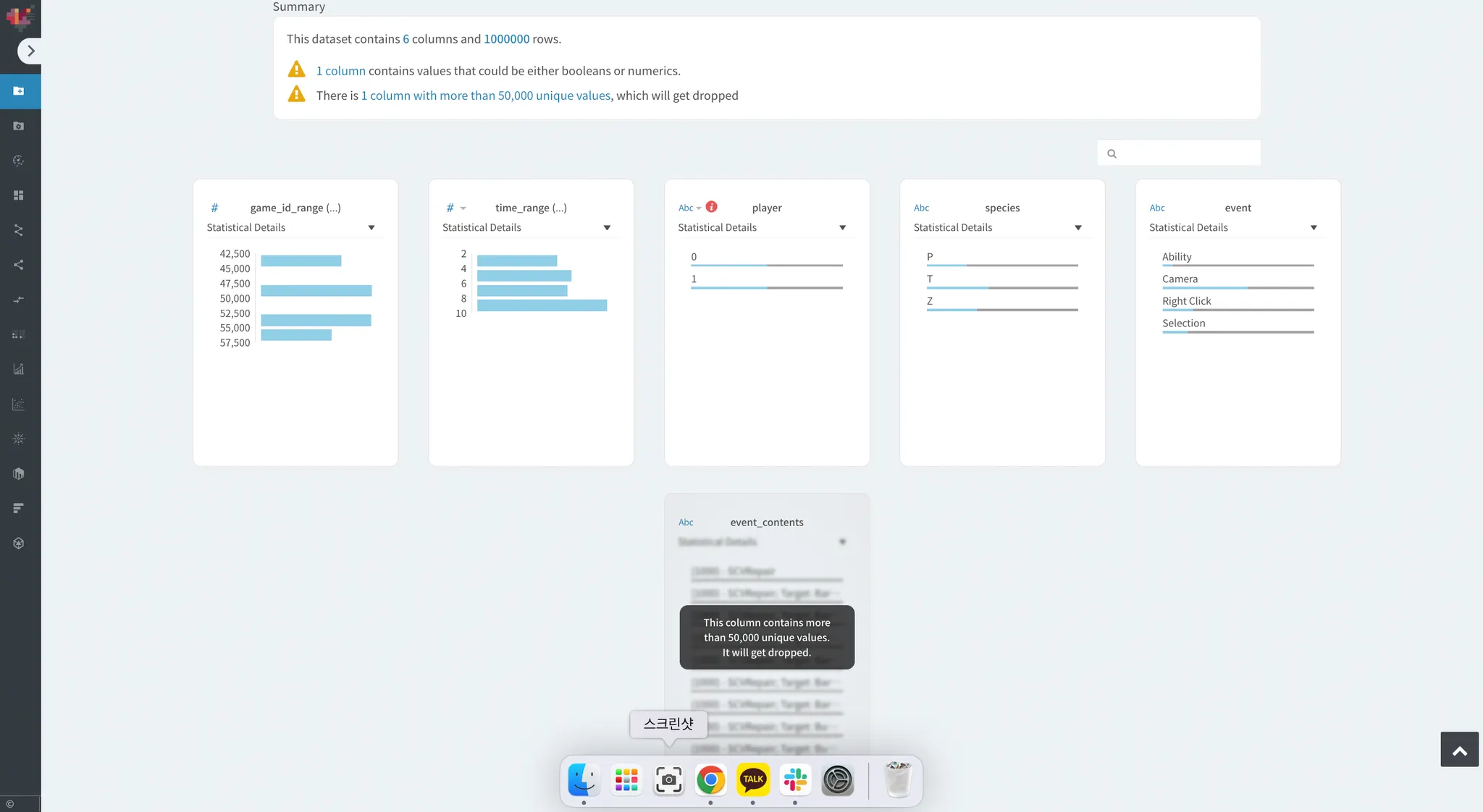
event_contents에 고유한 값이 50,000개를 넘어 분석에 노이즈를 만들어내는 형태가 되었습니다.
하트카운트에서 자동으로 해당 컬럼을 삭제하기로 합니다.
이러한 문제는 흔히 데이터 분석에서 cardinality 문제로 불려집니다.
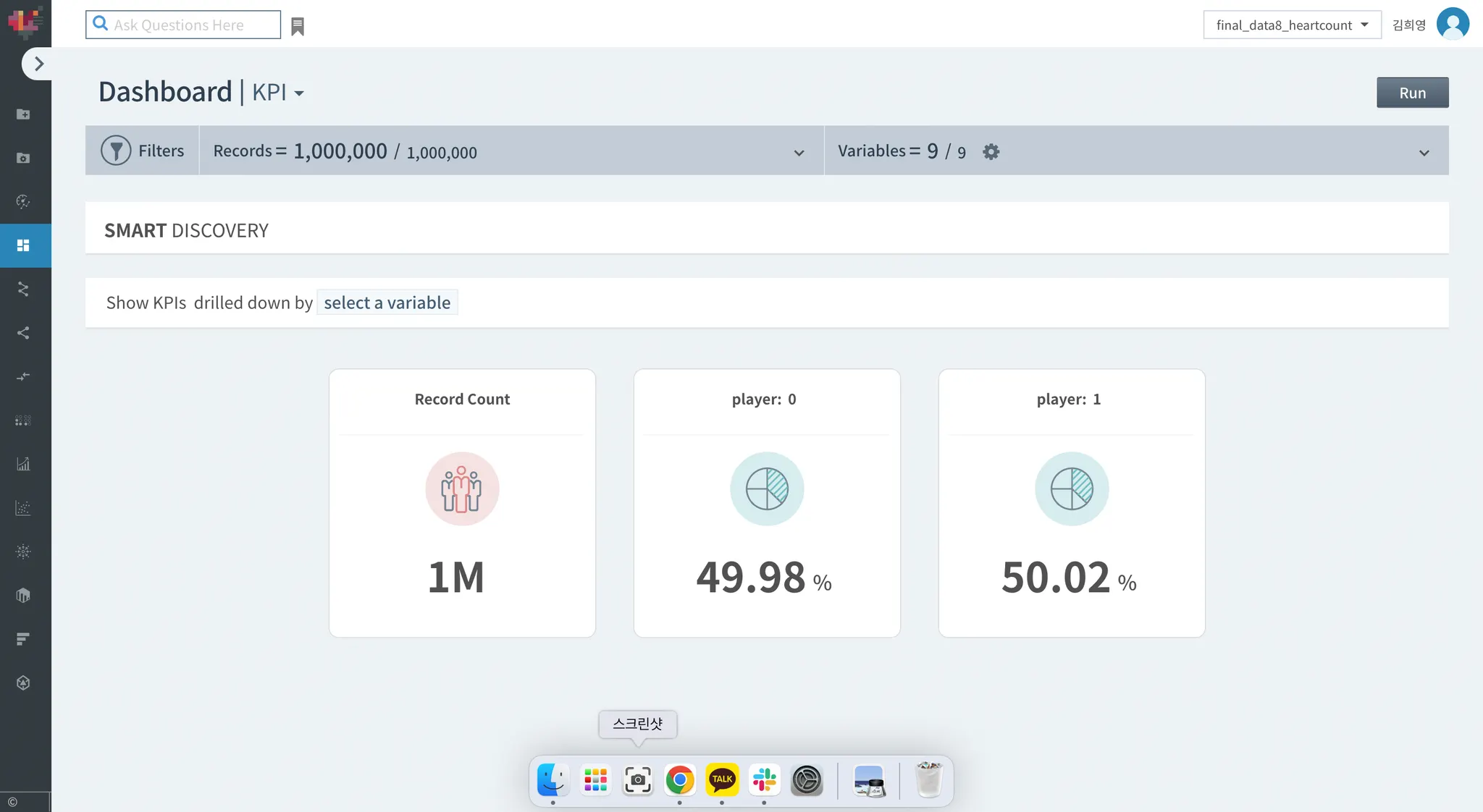
Dashboard
100만개의 데이터가 있고 kpi로 지정한 player 컬럼의 값별 퍼센트가 dashboard 에 표시되어 있습니다.
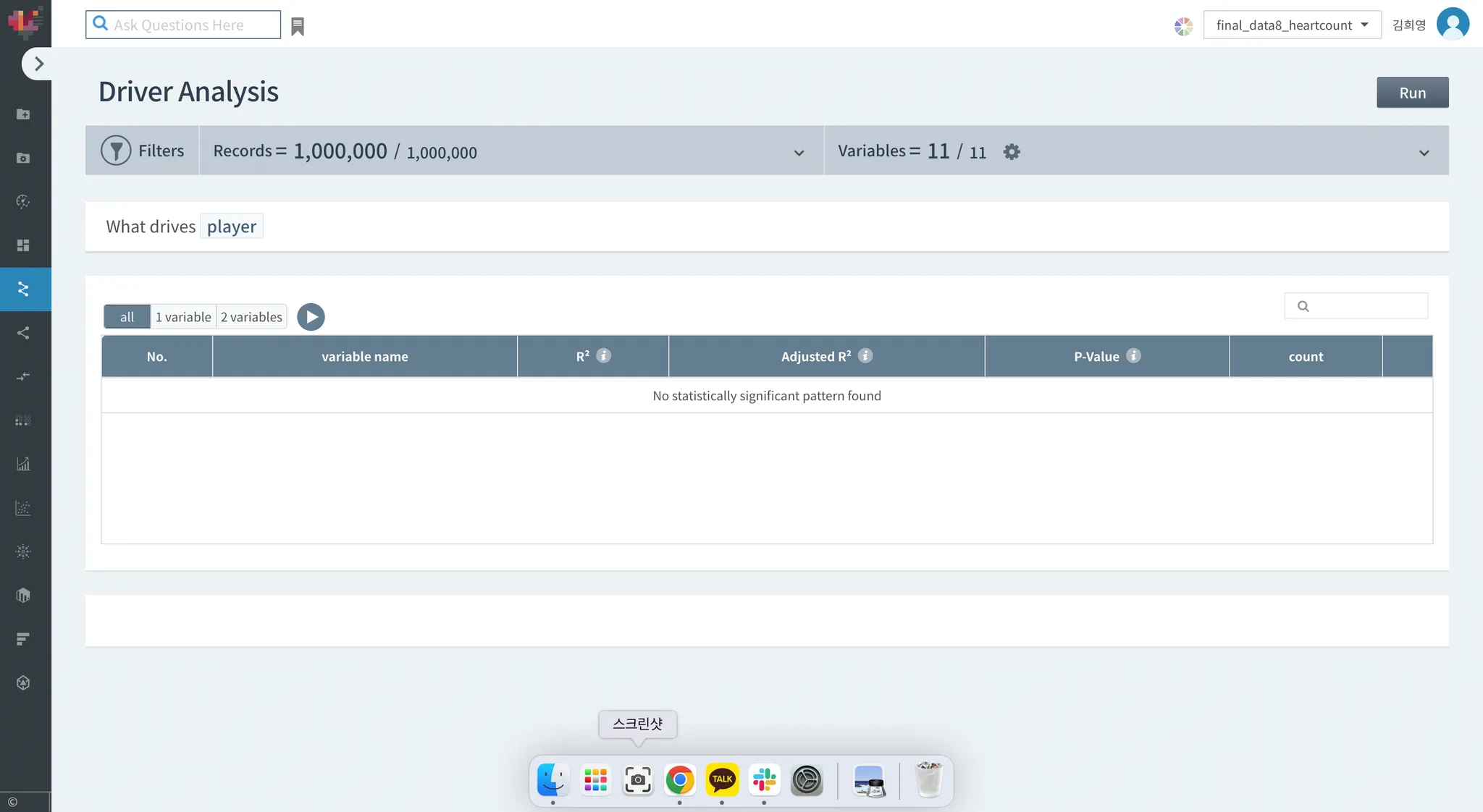
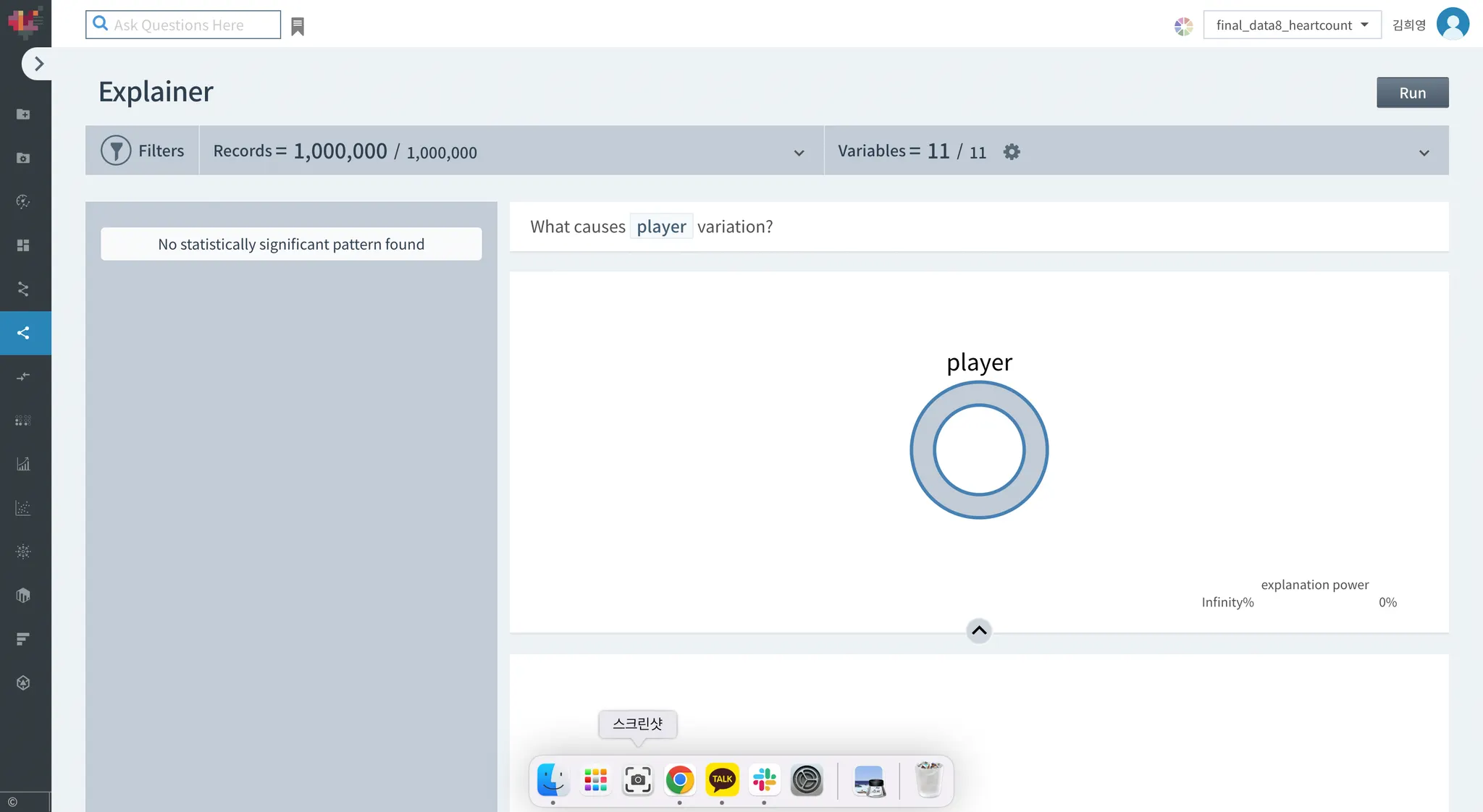
Driver analysis / Explainer
데이터 수가 적어서 그런지, 요인분석과 설명에서 아무것도 할 수 없었습니다ㅜㅜ
No statistically significant pattern found라고 나오네요ㅜㅜ
4. Insight (Optional)
로컬에서 데이터를 업데이트도 해보고, 구글 드라이브를 사용해서 데이터를 업데이트도 해봤는데 파일의 크기가 GB 를 넘어가면 하트카운트에서 지원이 되지 않는 것 같습니다.
해당 분석을 진행할 때는 파일 크기를 1.92GB에서 60MB까지 줄여야 데이터를 업로드 할 수 있었습니다.
GB의 데이터가 업로드 가능했다면 좀 더 유의미한 분석을 진행할 수 있지 않았을까 싶습니다.
일주일의 시간동안 해당 데이터의 전처리를 진행하느라 다른 데이터는 찾아보지 못했는데, 다른 데이터도 시도해볼껄 하는 아쉬움이 남는 미션이네요.