

데이터셋 (출처: Kaggle) “Korea Income and Welfare”
>> 상기 첨부파일 클릭시, 해당 데이터셋 다운로드 가능
데이터셋 개요 및 설명
해당 데이터셋의 경우, 대한민국 정부를 통해 2005년부터 14년간 축적된 데이터로, 한국의 부에 대한 연구(KOWEPS; Korea Welfare Panel Study)로 각 가정 내 생활환경, 교육 및 직업 등에 대한 다양한 요소들을 통해 어떻게 각 가정의 소득이 영향을 받고 있는지를 보여준다.
데이터셋 내 14개의 컬럼 설명
•
id
•
year 년도 : 연구조사가 실행된 년도
•
wave : 2005년을 Wave 1st로 시작하여 2018년 Wave 14th까지 표현
•
region 지역:
1) 서울
2) 경기도
3) 경상남도
4) 경상북도
5) 충청남도
6) 강원도 & 충청북도
7) 전라도 & 전주
•
income 소득: 만원 단위의 년소득
*실제 캐글 내 데이터셋 설명에는 백만원 단위로 기재되었으나, 전체적인 데이터를 확인 시 만원단위로 보여짐
•
family_member 가족 구성원 : 가정 구성원의 수
•
gender 성별 : 1) 남성, 2) 여성
•
year_born 출생년도
•
education_level 교육수준 :
1) 교육받은 적 없음 (7세 미만)
2) 교육받은 적 없음(7세 이상)
3) 초등학교
4) 중학교
5) 고등학교
6) 2년제 대학교
7) 4년제 대학교
8) 석사
9) 박사
•
marriage 혼인여부 :
1) 비해당 (18세 미만)
2) 기혼
3) 사별
4) 이혼
5) 미혼
6) 기타
•
religion 종교: 1) 종교있음, 2) 무교
•
occupation 직업: 하기의 첨부된 “직업 코드 시트”를 통해 각 직업 코드에 대해 설명
>> 각 코드별로 어떤 직업군인지 설명된 “직업 코드 시트” - 클릭 시, 파일 다운로드 가능
•
company_size 회사 규모:
1) 1-4명
2) 5-9명
3) 10~29명
4) 30~49명
5) 50~69명
6) 70~99명
7) 100~299명
8) 300~499명
9) 500~999명
10) 1000명 이상
11) 잘 모르겠다
•
reason_none_worker 무직 사유:
1) 근로무능력
2) 군복무
3) 정규 교육기관 학업
4) 진학 준비
5) 취업 준비
6) 가사
7) 양육
8) 간병
9) 경제활동 포기
10) 근로의사 없음
11) 기타
데이터 분석 접근 방향
가장 중요하게 살펴볼 종속변수는 연소득 컬럼으로, 어떤 요소에 따라 소득이 증가하고 감소하는지를 확인하고자한다. 실제 데이터셋을 분석 및 시각화 해보기 앞서 본 데이터셋 내 각 요소들을 통해 다음과 같은 분석 방향 및 결과 예상, 추후 활용법을 생각해보며 데이터 분석에 접근해보고자 한다:
•
해가 지나갈 수록 국내 물가상승 및 여러가지 최저임금 상승에 따라 년도가 커질수록 가구별 평균 소득도 증가했을 것이라 예상한다. 다만, 해가 바뀔 때 한 가정 내 가족 구성원수의 변화, 지역의 이동, 직업의 변화 등 다른 변수에 따라 달라질 수 있기에 어떤 변수가 소득에 영향을 주는지를 확인하는 작업이 필요하다.
•
지역은 서울과 경기도 순으로 가장 높은 년소득을 보여줄 것이라 예상한다. 그 외 지역들의 경우 관련 인사이트가 부족하기에 EDA를 통해 확인해보고자한다.
•
가족 구성원의 수는 1인 가구의 경우 스스로 경제활동 및 스스로를 부양해야하기에 그만큼 더 열심히 소득을 높일 수 있을 것이라 생각되지만, 부부가 맞벌이를 한다는 가정하에 1인 가구 일 때 보다 2인 가구 일때 조금 더 년소득이 높으리라 예상되며, 3인 이상으로 자녀의 출생이 있는 경우 부부 중 한 쪽의 육아로 인해 경제활동이 어려우리라는 판단하에 2인, 1인, 3인, 4인, 5인 이상의 순으로 년소득은 더욱 낮게 보여질 것이라고 예상해본다. 단, 해당 데이터 표본의 태어난 년도에 따른 당시 나이에 따라 1인가구의 소득이 더 낮게 보여질 수도 있을 것이라 예상하며, 연령대에 따른 소득 변화에 대해서도 확인이 필요해보인다.
•
성별의 경우, 현재는 다를 수 있지만 본 데이터셋 내 데이터가 수집된 시기의 사회적 여성 근로자들의 근무 환경이나 여러가지 사회 현상을 돌이켜 보았을때, 여성보다는 남성의 소득이 조금 더 높을 것이라 예상해본다.
•
추가로 교육수준의 경우 석사 이상부터 조금 더 높은 소득을 보여줄 것이라 예상되며,중요한 변수 두가지는 “직업”과 “회사 규모”로, 직업군에 따라 소득금액이 차이가 날 것이라 판단되나 정확히 어떤 직업군에 따라 달라질지는 EDA를 통해 확인해보고자한다. 회사 규모는 크면 클수록 대기업이라는 가정에 따라 소득이 더 높게 보여질 것이라 예상된다.
•
혼인여부, 종교, 무직 사유의 경우 다른 변수들과 연관되어 종속변수인 소득에 영향을 줄 수 있으나 그 자체만으로는 년소득에 큰 변화를 주지는 않을 것이라 생각된다.
하트카운트 데이터 분석
•
해가 지나갈 수록 국내 물가상승 및 여러가지 최저임금 상승에 따라 년도가 커질수록 가구별 평균 소득도 증가했을 것이라 예상한다. 다만, 해가 바뀔 때 한 가정 내 가족 구성원수의 변화, 지역의 이동, 직업의 변화 등 다른 변수에 따라 달라질 수 있기에 어떤 변수가 소득에 영향을 주는지를 확인하는 작업이 필요하다.
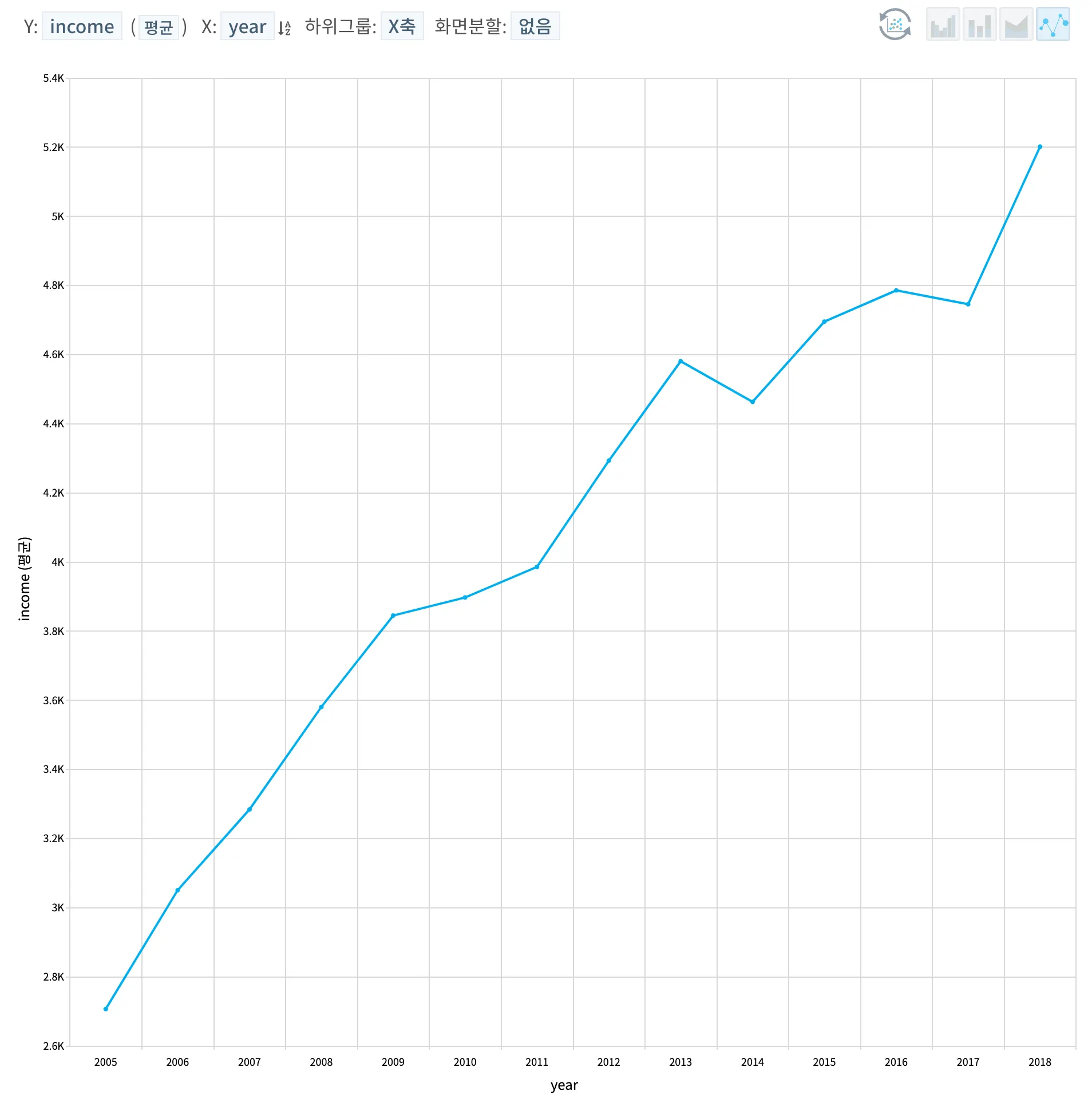
•
지역에 따른 평균 연소득을 보았을 때, 서울과 경기 지역의 연소득이 가장 높을 것이라고 예상하였으나, 2) 경기도 지역이 1위, 5) 충청남도가 2위, 7) 전라도&전주 지역이 3위, 그 다음이 1) 서울 지역으로 보여지고 있다. 의외의 결과로 보여지기에 혹시 데이터가 편향된 것이 아닌지 확인하고자 드릴다운으로 들어가보았다.
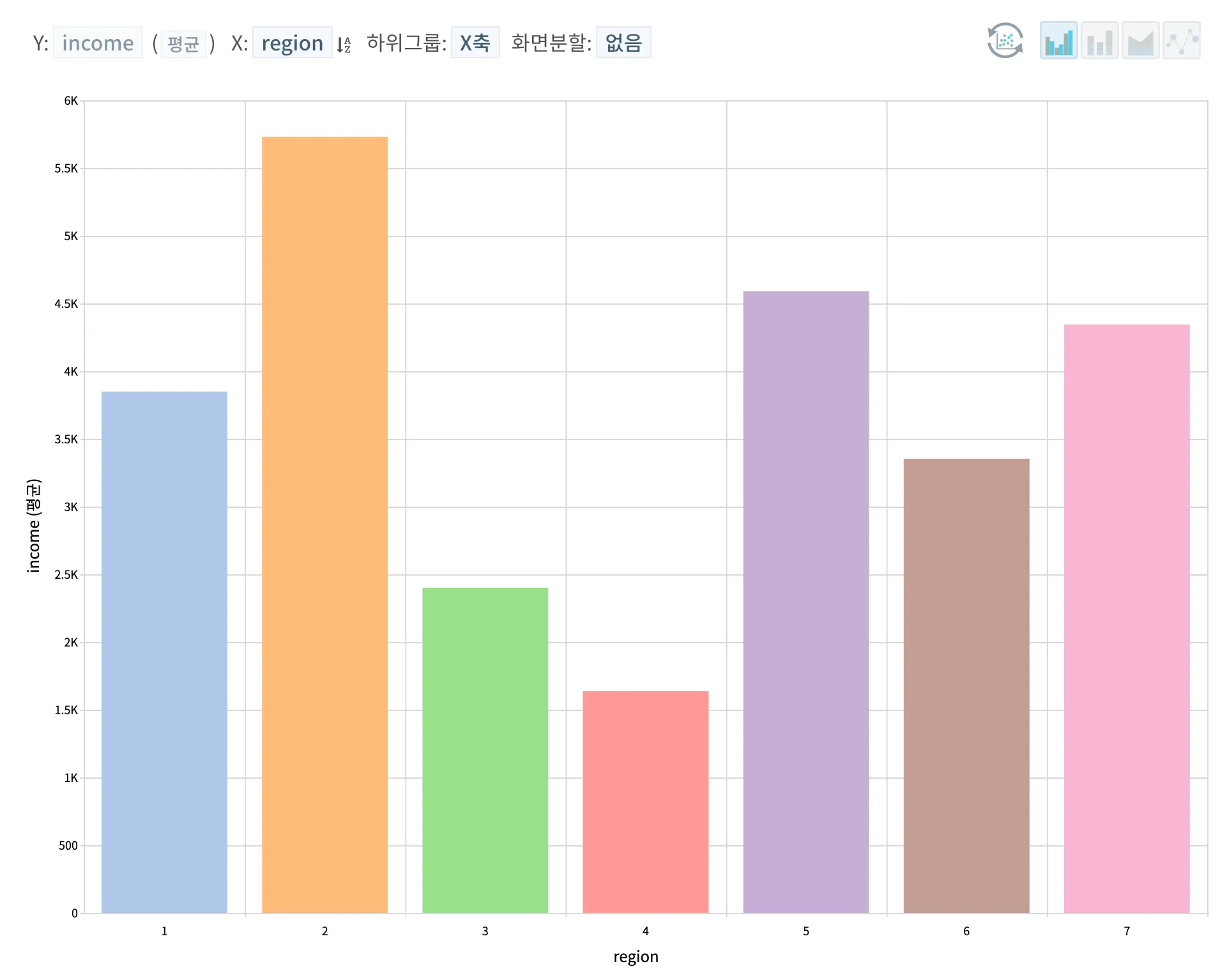
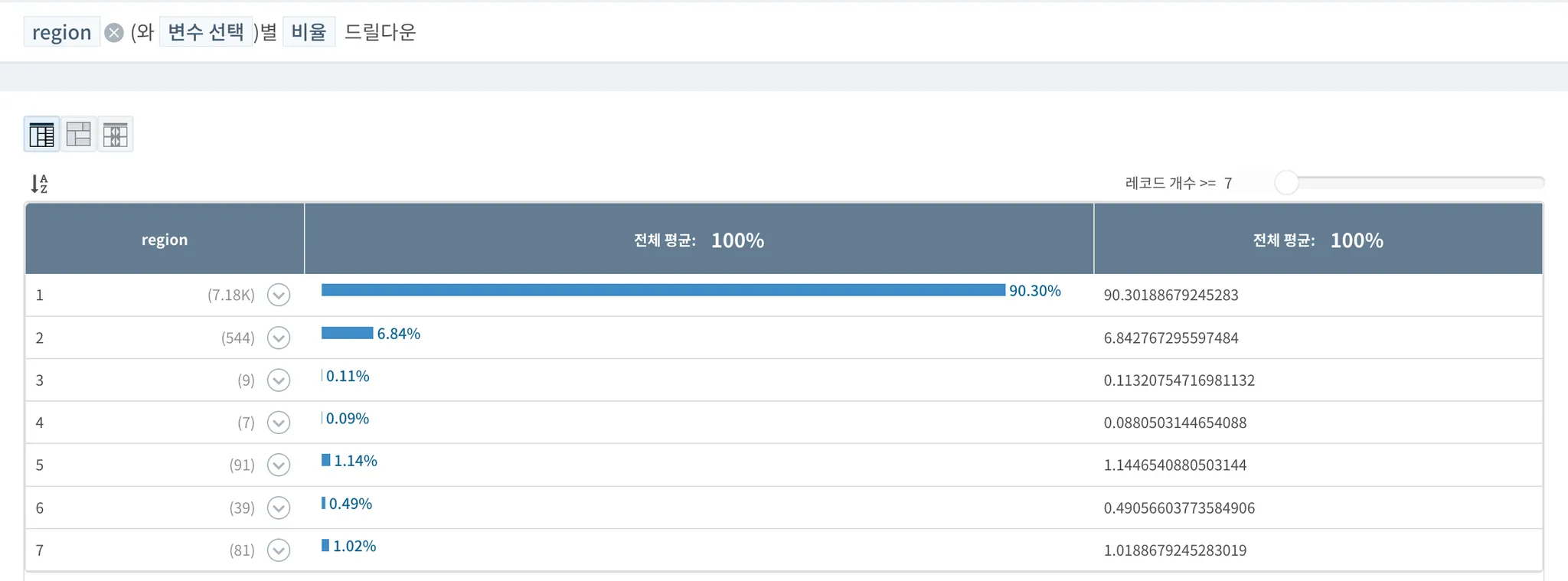
•
드릴다운을 통해 각 지역 내 교육수준에 따른 전체적인 분포를 확인한 결과, 90% 이상의 표본은 서울에 거주하는 것으로 확인되었다. 이에 따라 상단에서 확인한 지역별 평균 연소득의 시각화 결과는 서울 지역에 90% 이상 편향된 표본집단을 통해 분석된 만큼 지역별 정확한 평균 연소득 금액이라고 보기에는 힘들 것으로 판단되며, 지역별 데이터로 다른 변수들과의 상관관계를 보는 것은 어려울 것으로 판단된다.
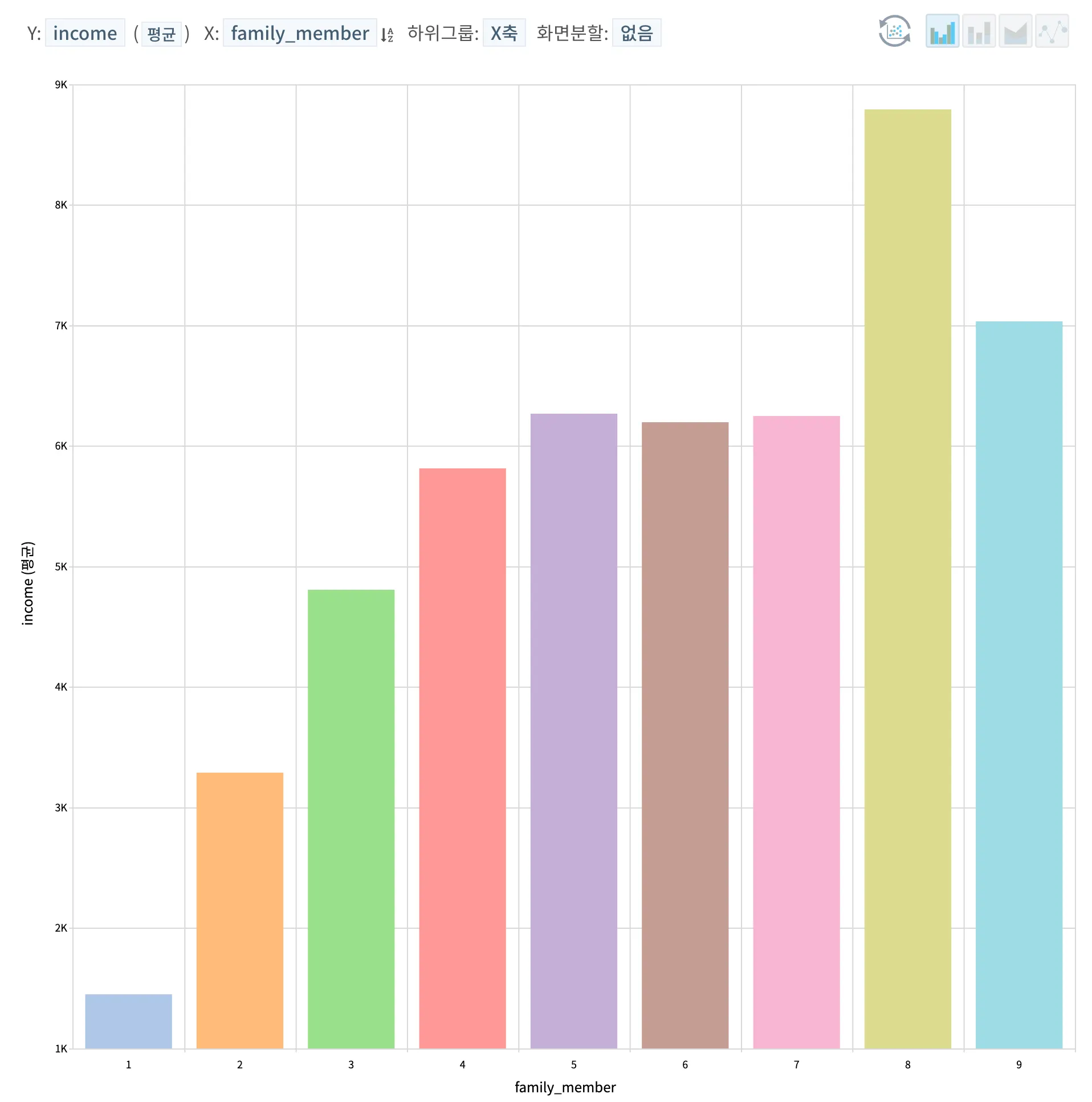
•
가족 구성원의 수는 1인 가구의 경우 스스로 경제활동 및 스스로를 부양해야하기에 그만큼 더 열심히 소득을 높일 수 있을 것, 그리고 부부가 맞벌이를 한다는 가정하에 1인 가구 일 때 보다 2인 가구 일때 조금 더 년소득이 높을 것, 그리고 3인 이상으로 자녀의 출생이 있는 경우 부부 중 한 쪽의 육아로 인해 경제활동이 어려우리라는 판단하에 2인, 1인, 3인, 4인, 5인 이상의 순으로 년소득은 더욱 낮게 보여질 것이라고 예상하였지만, 하기의 결과에 따라 부양가족이 많으면 많을 수록 연소득도 월등하게 높아지는 것으로 확인이 된다. 8인 가족의 경우 특이하게 상당히 높은 연소득을 보이는데 해당 데이터를 확인한 결과 표본 데이터 개수는 12개로 소수의 데이터가 상당히 높은 연소득 갖고 있기에 나온 결과로 보여진다.
•
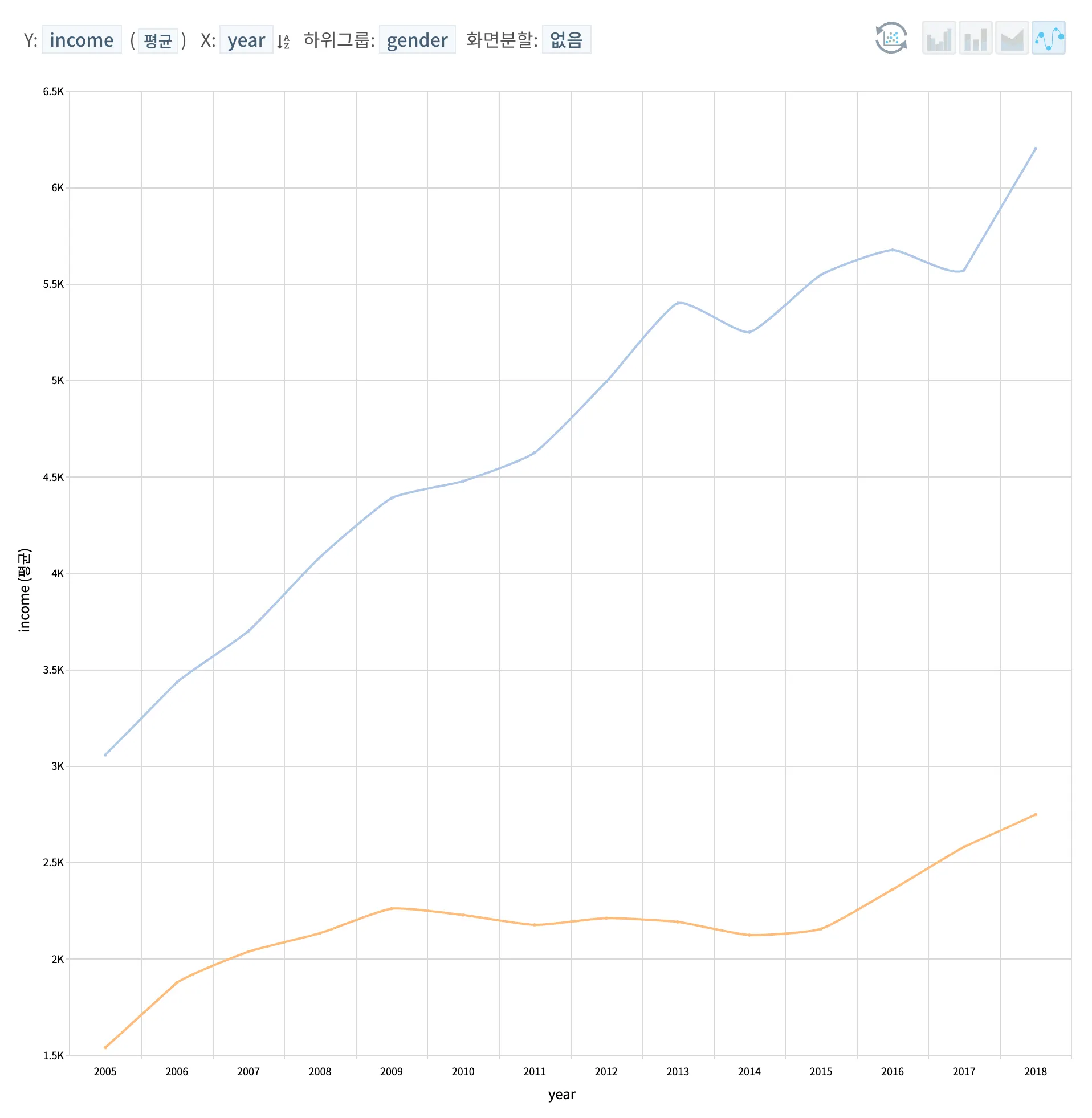
성별의 경우, 본 데이터셋 내 데이터가 수집된 시기의 사회적 여성 근로자들의 근무 환경이나 여러가지 사회 현상을 돌이켜 보았을때, 여성보다는 남성의 소득이 조금 더 높을 것이라 예상하였고 시각화를 통해 남성 가구주일 때 2005년 기준, 약 1.5천만원 차이나던 남녀 가구주 일때의 각각 년 소득 차이가 2018년 기준, 약 3천만원 이상으로 남성 가구주일 때의 가구 년소득이 월등하게 높은 것으로 보여진다.
•
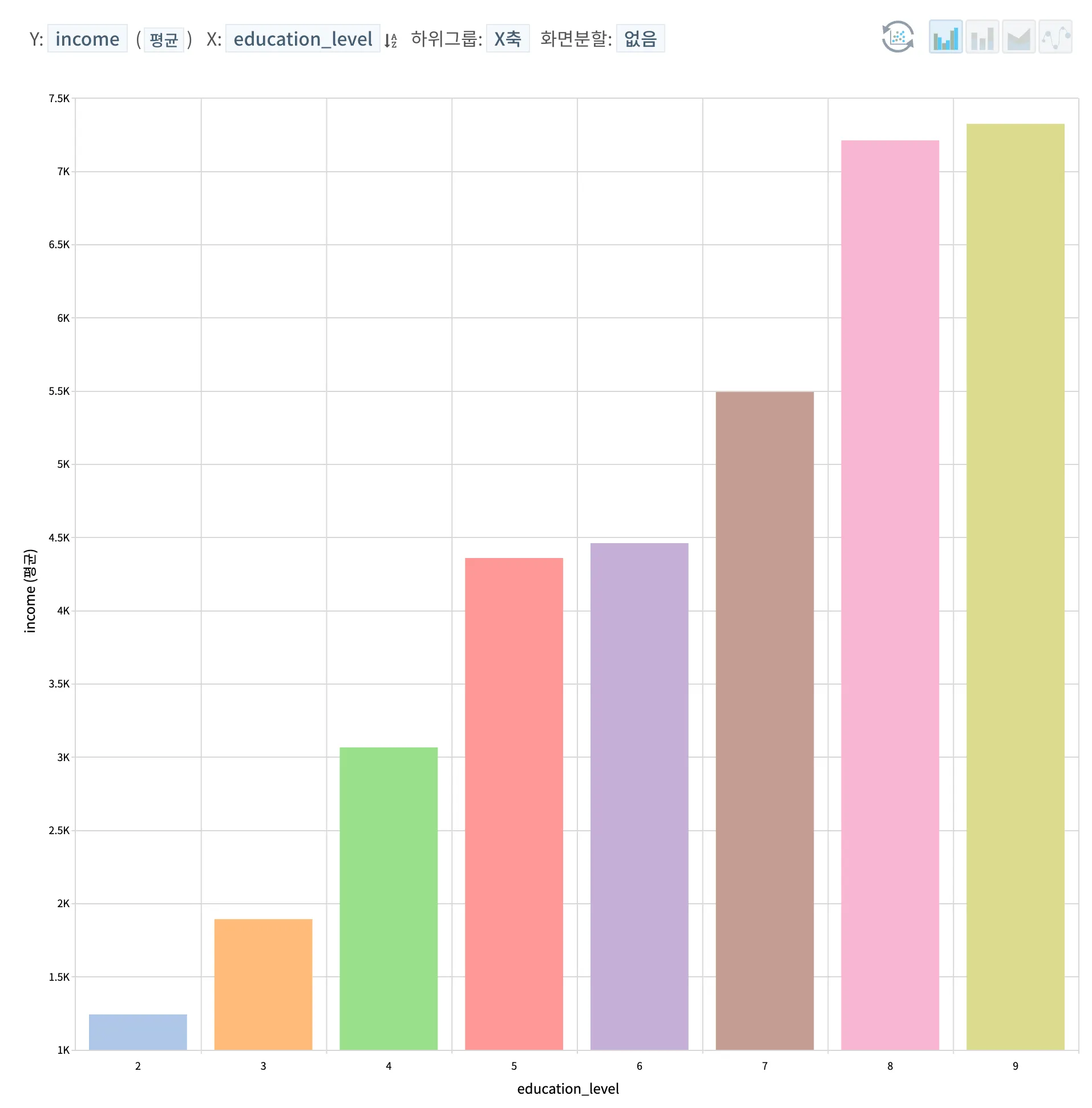
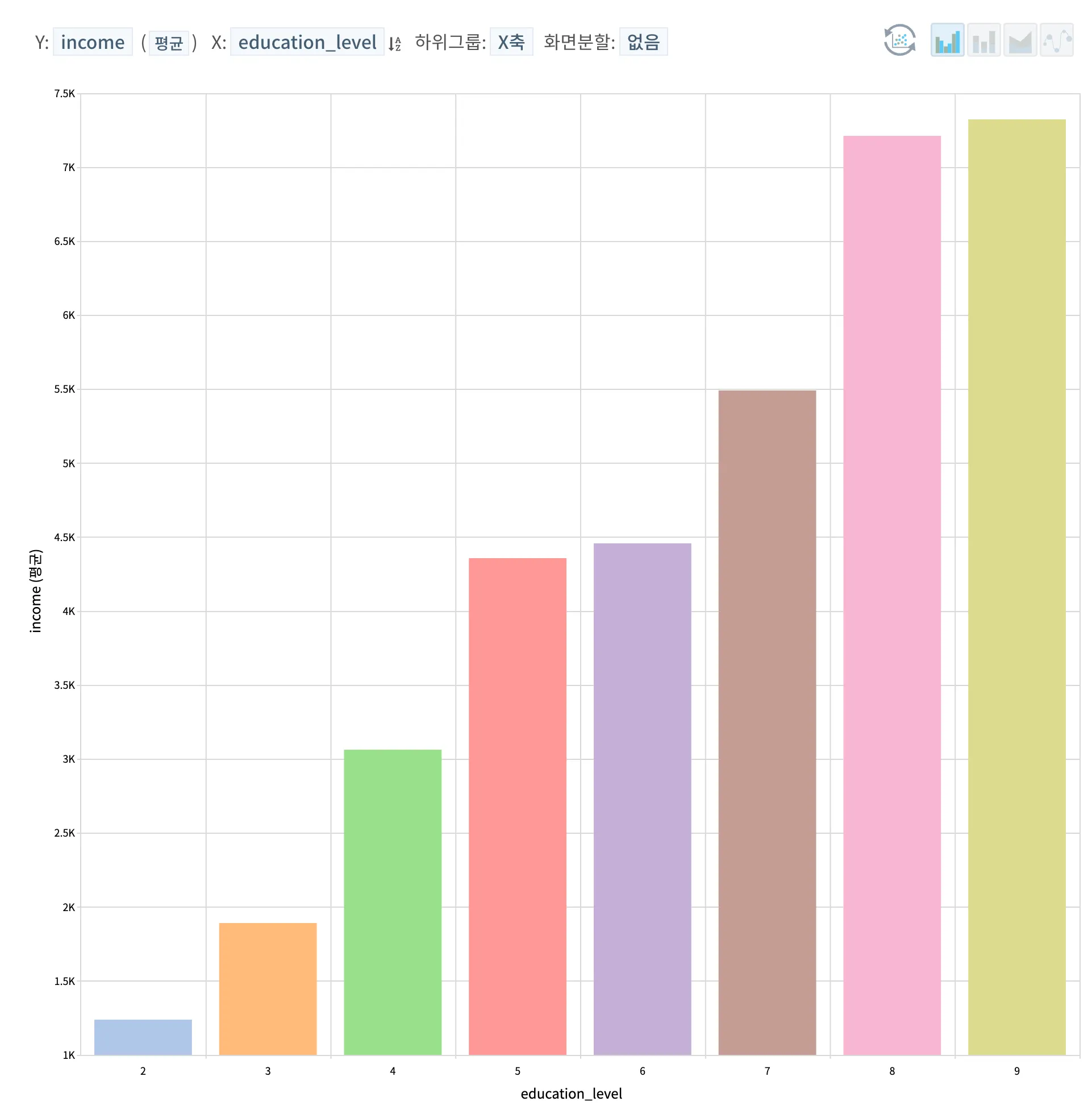
예상했던 것처럼 교육 수준에 따른 연소득의 변화는 분명했다. 고등학교 졸업과 2년제 대학졸업, 그리고 석사와 박사 학위의 경우 각각 큰 소득 차이가 크지 않았지만 중학교 졸업과 고등학교 졸업, 2년제 대학졸업과 4년제 대학 졸업, 그리고 4년제 학사와 석박사의 연소득 차이는 각각 약 1천만원에서 2천만원까지 나는 것을 확인할 수 있다.
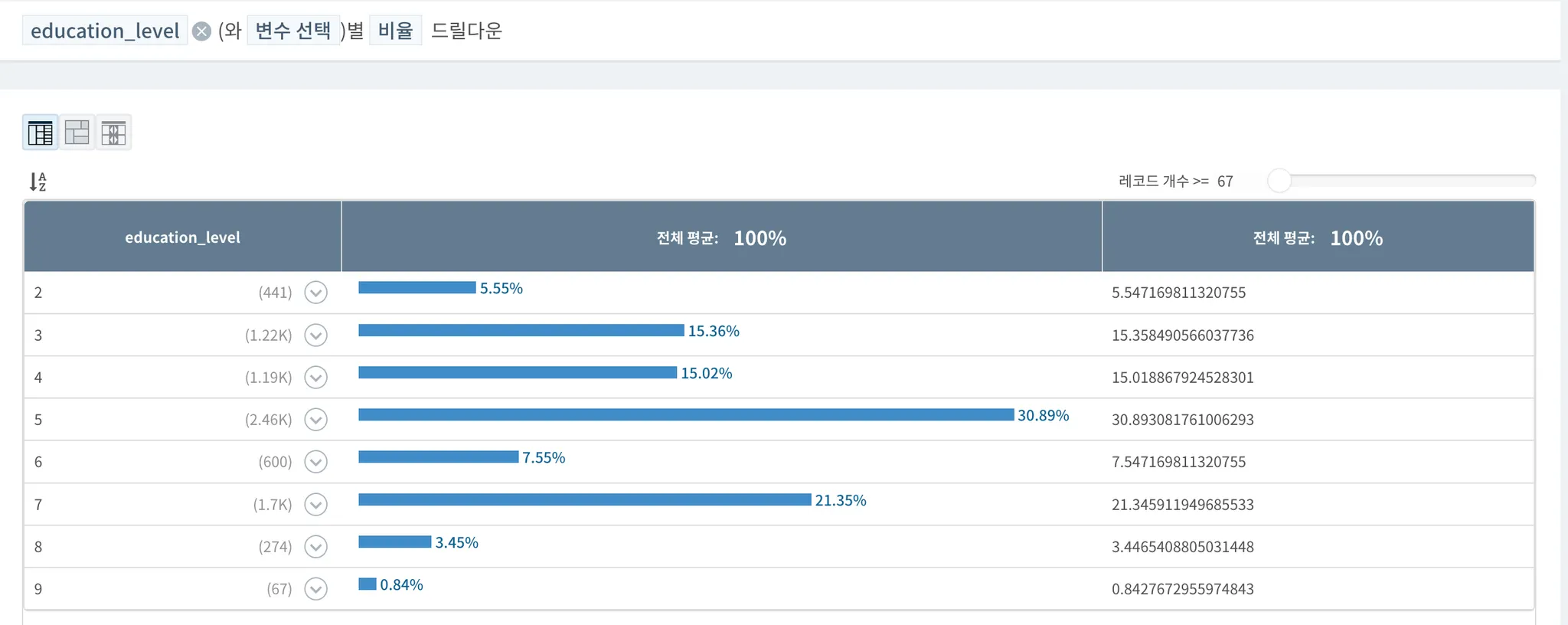
◦
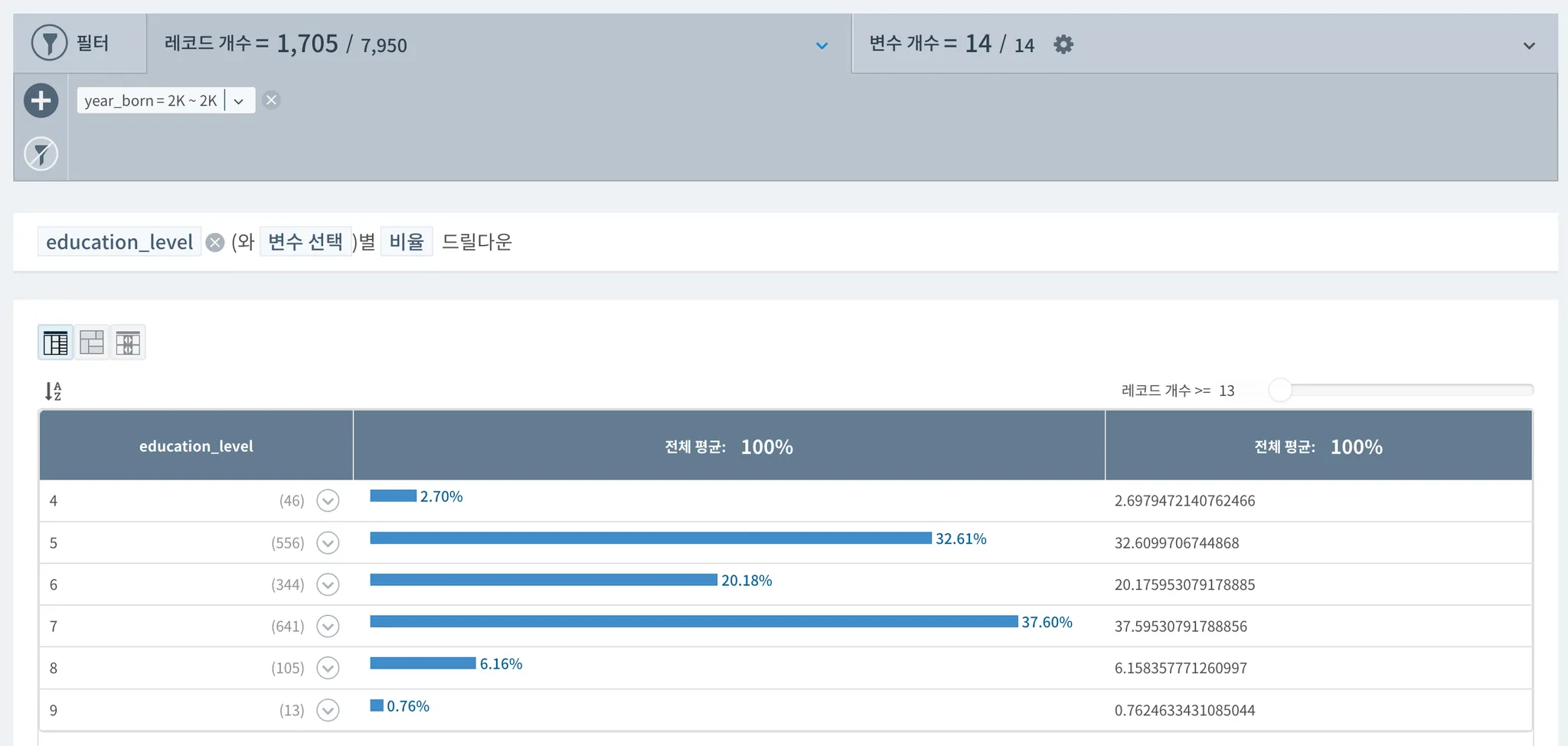
대졸자 (2년제 포함) 이상의 학력을 갖고 있는 표본수는 전체 중 약 33.19%로 확인되는데, 전체적인 데이터 표본의 연령대가 높았던 것을 기억하여, 필터링을 통해 표본 수집 마지막 시기인 2014년 기준 30-40대로 들어갈 수 있는 출생년도를 1970년도 이상으로만 놓고 보게되면 대졸자 이상의 분포가 확연하게 높아지는 것을 볼 수 있다. (하단 그래프 참조)
•
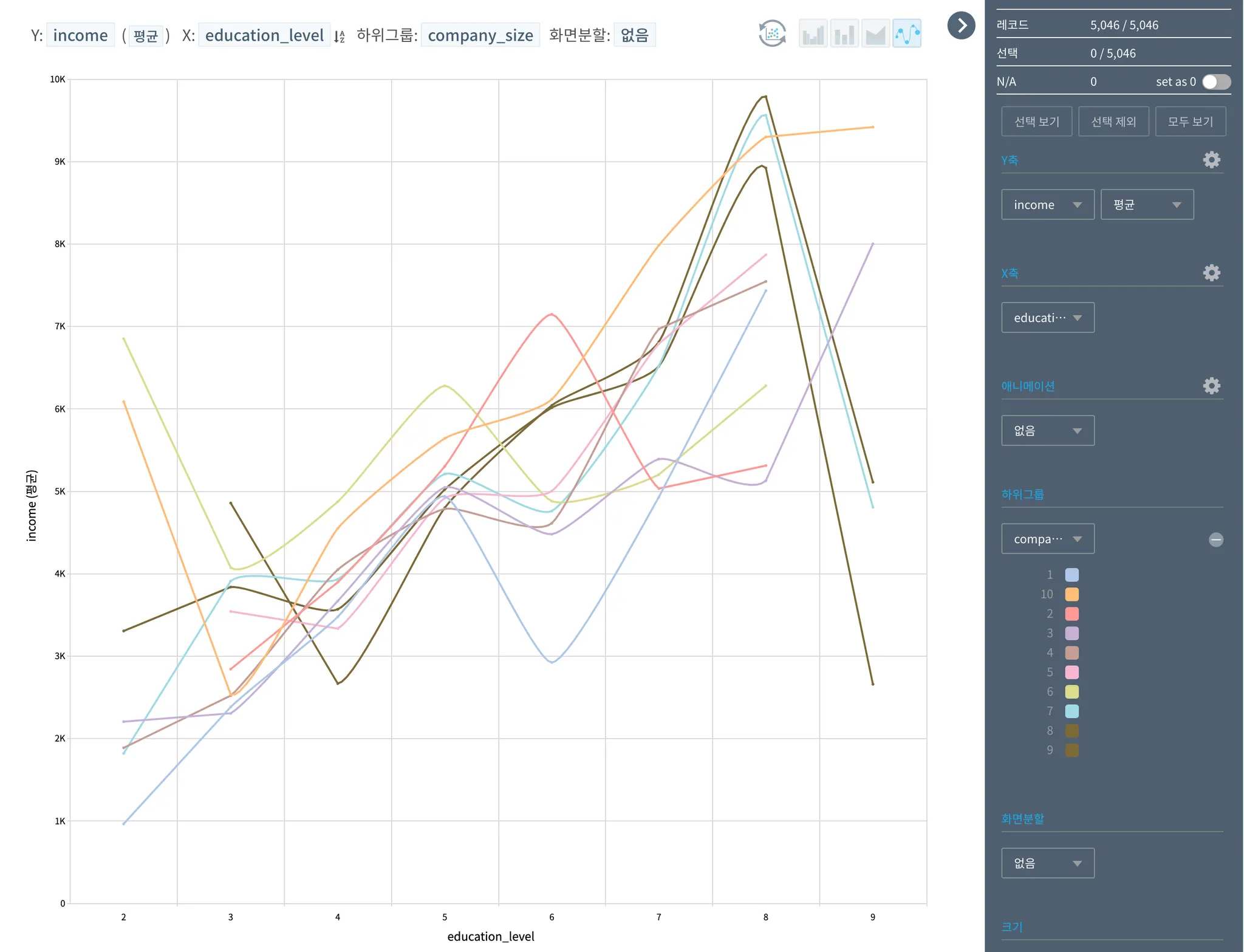
추가로, 상기 추가로 확인한 연령대와 상관없이 교육 수준에 따른 연소득을 각 근무하는 회사 사이즈에 따라 추가로 구분해보았고, 교육 수준 및 회사 사이즈에 따라 평균 연소득 역시 차이가 날 것이라 예상했던 것처럼 교육수준이 7) 4년제 이상 대학을 졸업자의 경우 회사 규모가 작을 수록 (1~3) 연 소득도 낮으며, 회사 사이즈가 커질 수록 연소득이 높은 것으로 보여지나, 8) 석사 학위자의 경우 회사 규모가 최소 100인 이상 되는 기업에 근무 시 연소득이 높은 것과 함께, 근무 회사의 동일 사이즈 기준으로 보았을 때 석사 이하의 교육수준을 갖고 있는 집단보다는 확연하게 석사 학위자들이 높은 연소득을 갖고 있는 것을 확인 할 수 있다. 1000명 이상의 직원수를 갖고있는 대기업은 석사보다는 박사 학위자가 높은 연소득을 보여주나, 석사 학위자의 연소득과 확연하게 큰 차이는 없는 것으로 보여지며 그 외 다른 사이즈의 회사를 다니는 박사 학쉬자들은 오히려 연소득이 확연하게 떨어지는 것으로 보아 데이터 표본수가 너무 적어 미정확한 결과를 보여주는 것으로 판단된다.
직업분류의 경우, 대분류 없이 수천가지의 코드로 나뉘어져있다보니 오랜시간의 데이터 전처리가 필요하여 이번 데이터 분석에서는 제외시킴
•
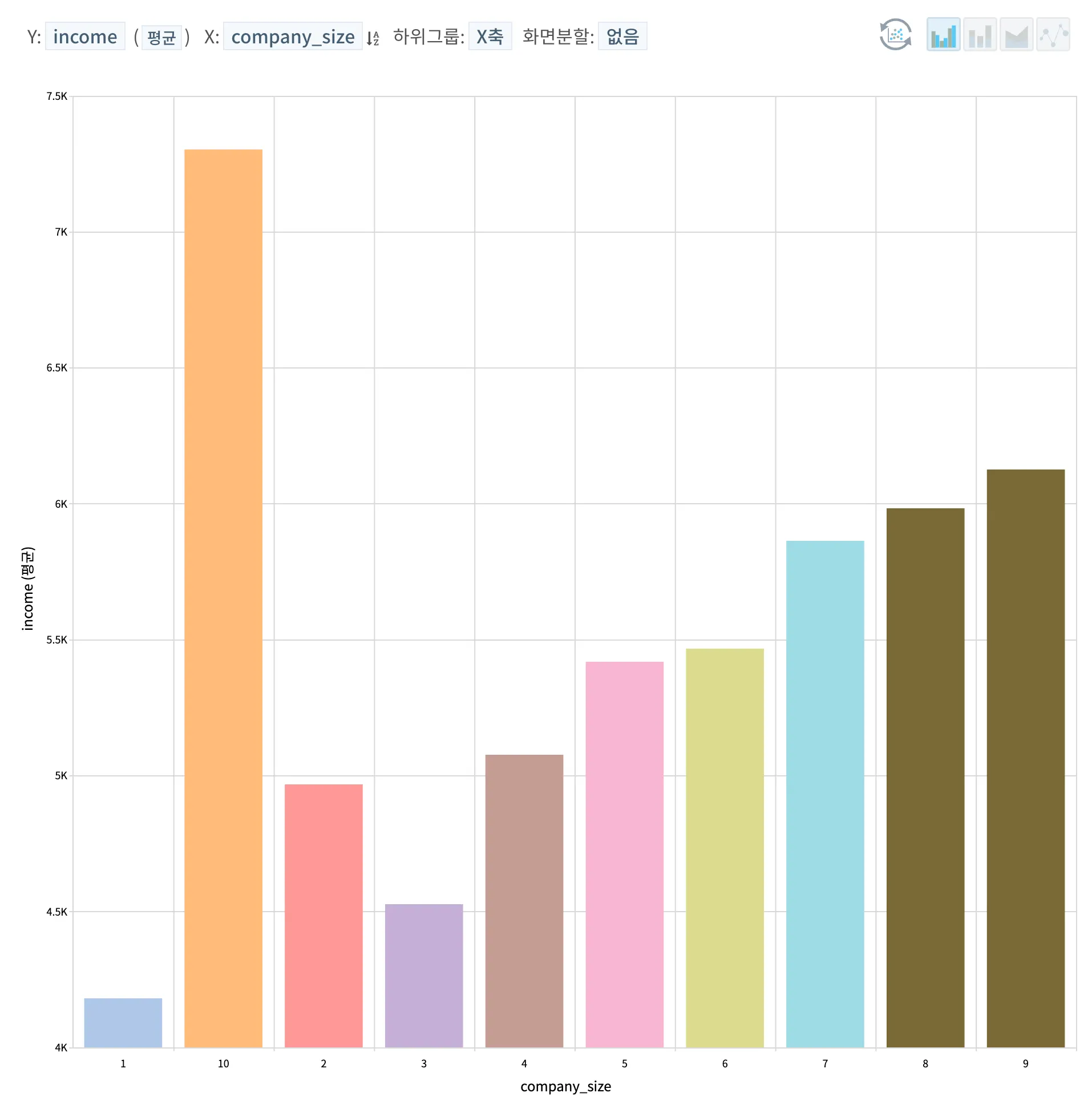
상단 분석 결과에 따라 단순 근무 회사 사이즈에 따른 평균 연소득을 비교해보았고, 하기의 데이터 시각화 결과에서 99 및 NA 등 오류, 결측 데이터와 함께 회사 사이즈를 모른다는 11) 항목은 삭제하였으며, 시각화 당시 10) & 11)의 대기업 사이즈가 1) 다음으로 나오는 것을 염두해두고 확인해야한다. 시각화 결과에 따라 근무하는 회사 사이즈에 따른 연소득의 경우, 2) 5-9인 인 회사의 경우, 4) 30-49인과 비슷한 평균 연소득을 보여주나, 그 외 전체적으로 근무하는 회사의 사이즈가 크면 클수록 연소득도 높아지는 것으로 보여진다.
•
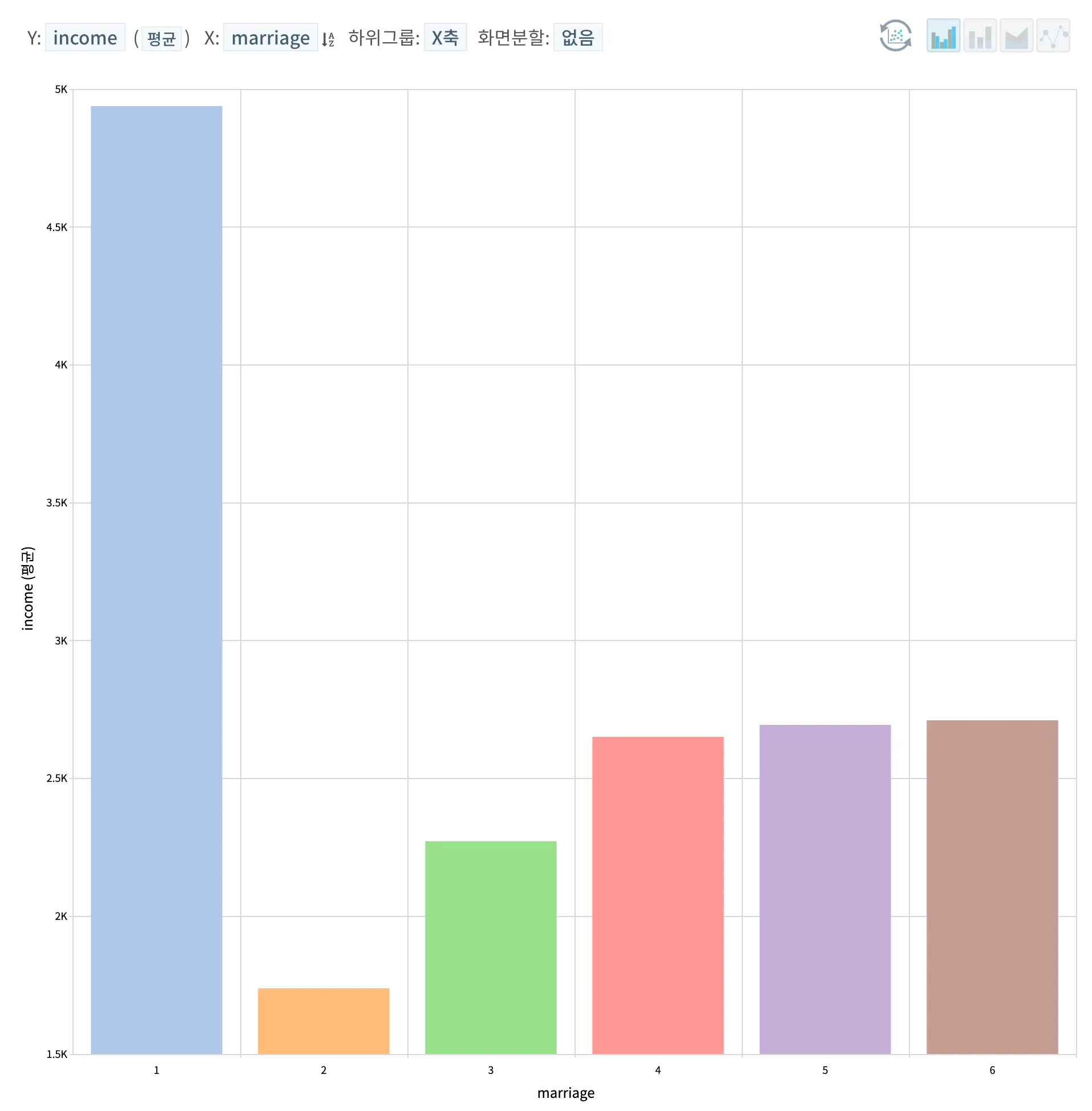
혼인여부에 따른 평균 연소득을 확인하고자하였으나, 조금 당황스러운 결과는 가장 높은 연소득을 보여주고 있는 1) 데이터의 경우 비해당으로 18세 미만으로 국내에서 현실적으로 18세 미만의 미성년자가 이와 같은 가장 높은 연소득을 갖고 있기에는 어려움이 있다. 추가적으로 2) 기혼의 경우에도 연소득이 가장 낮게 보여지는만큼 해당 데이터셋의 각 범주명의 설명자체가 잘못되었거나, 데이터셋의 수집에 문제가 있었던 것으로 판단된다. 하여, 혼인여부의 데이터를 갖고 추가적인 상관점을 분석하기에는 어려움이 있을 것으로 보여진다.
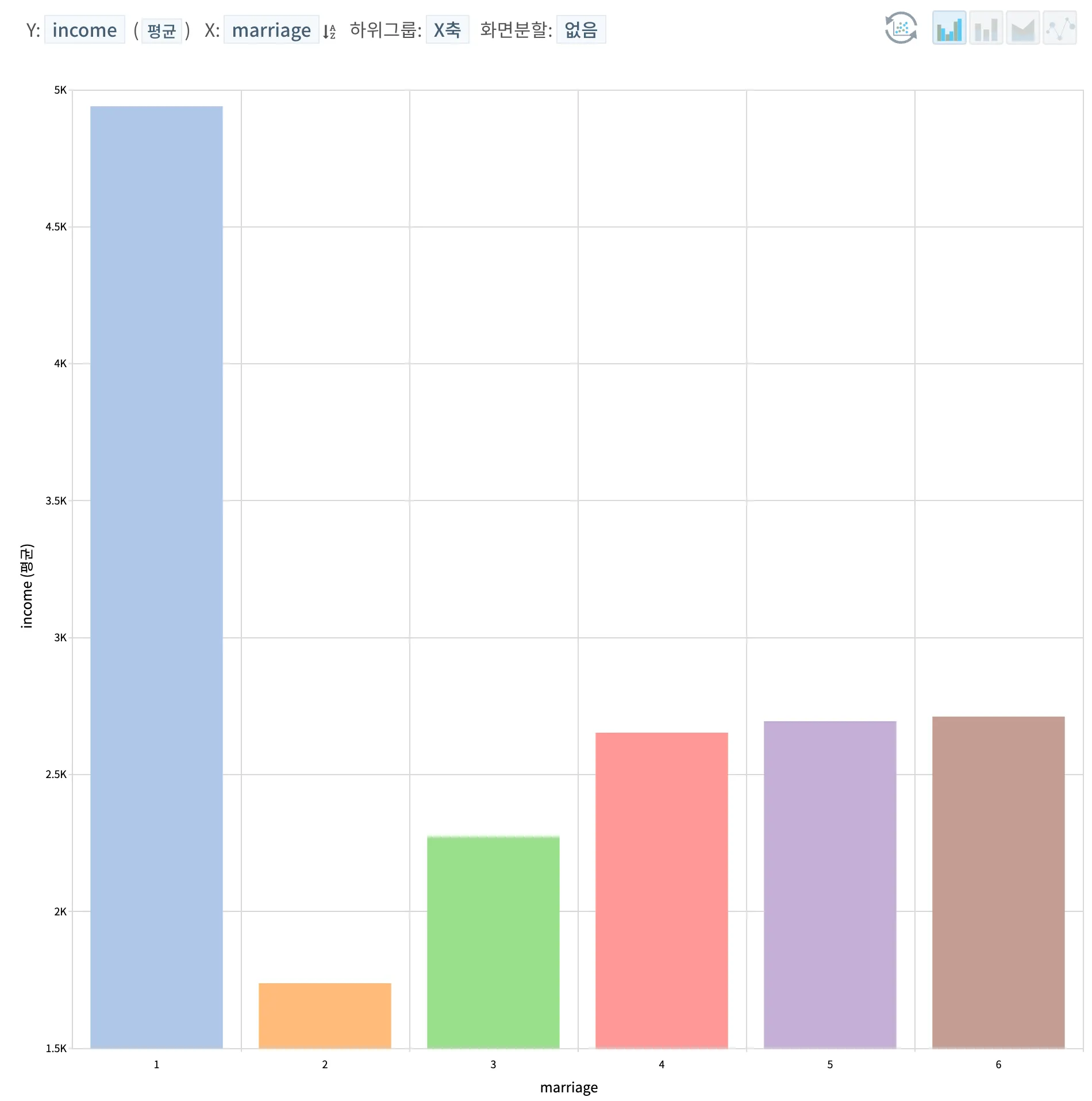
혼인여부를 기준으로 시각화 했을 때, 조금 당황스러운 결과가 보여지는데 1) 비해당 (18세 미만) 인 집단의 평균 연소득이 상당히 높은 수치를 보여주고 있다. 이는 본 데이터셋의 설명자체가 잘못되었거나 데이터의 오류가 있지 않았나 싶다. 아울러, 기혼자들의 경우 배우자와의 맞벌이가 이루어질 경우 조금 더 높은 연소득을 보여줄 수도 있을거라 예상했지만 미혼자, 사별자, 이혼자 등이 조금 더 높은 연소득을 보여주는 것도 본 시각화를 통해서는 이해할 수 없는 결과인 듯 싶다.
•
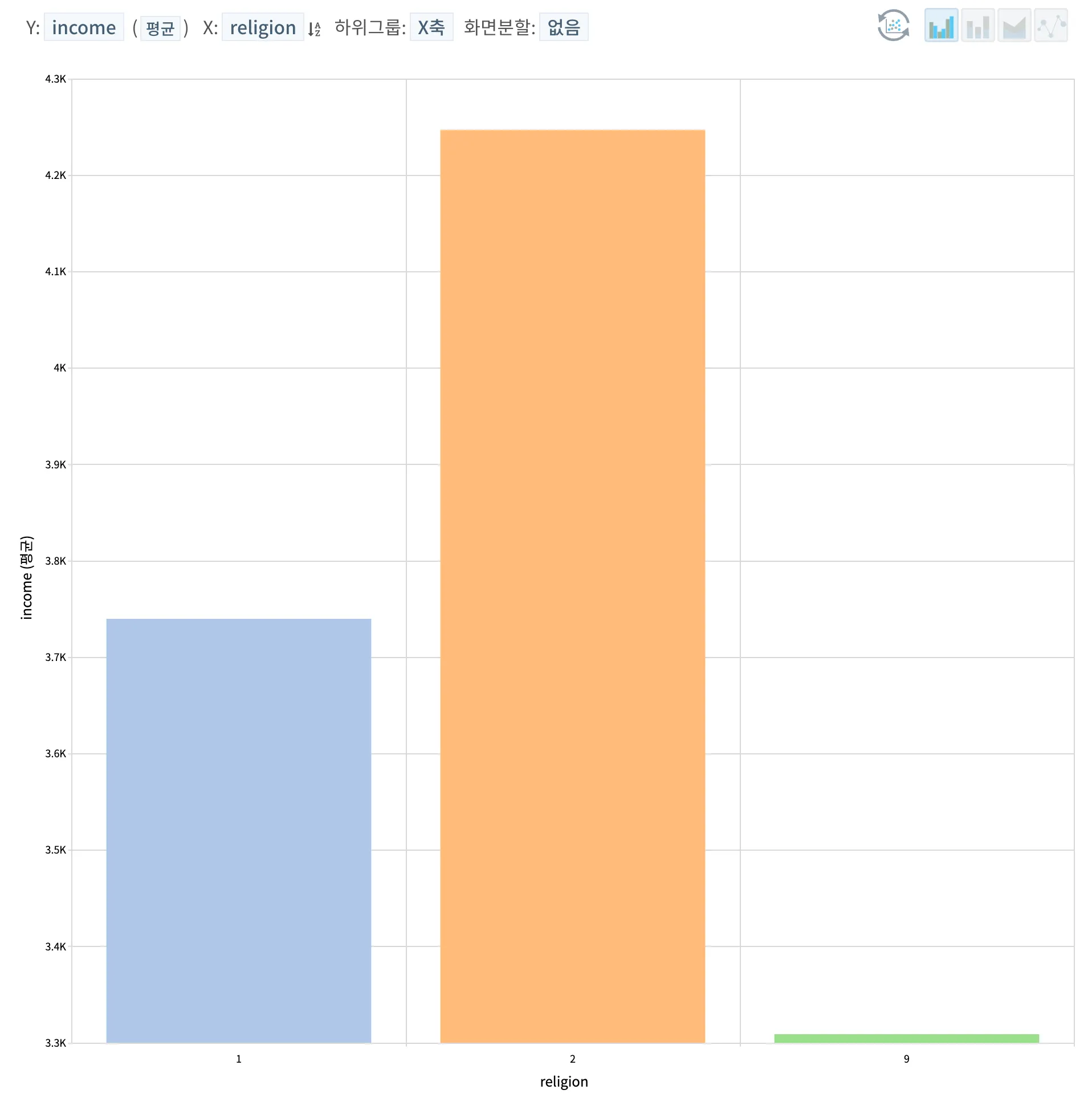
종교의 경우, 종교 보유 여부에 따른 직접적으로 소득에 영향을 주지 않을 것이라 예상하였지만 2) 무교의 경우 조금 더 높은 연소득을 보여주고 있다는 것이 흥미로웠다. 9) 데이터 범주의 경우 오류로 보여져 무시하기로 하였다.
전반적 피드백 by David from Team HEARTCOUNT
시각화를 통해 세우신 가설을 글로 풀어내는 부분 잘 읽었습니다. 저희 툴을 사용해 주셔서 감사합니다!
두가지 코멘트를 드리고 싶은데요!
1. 전반적으로 바 차트와 라인 차트를 통해서만 패턴을 찾으려 하셨는데, 저희 제품의 큰 특장점이 개별 레코드 시각화이니만큼! 분포를 확인하시면서(박스플롯, 95% 신뢰구간 등) 이상치로 색출되는 각각의 레코드들에 대한 자세한 탐구가 있다면 더 좋은 스토리를 찾으실 수 있지 않을까 싶습니다.
2. 세부 코멘트들로도 말씀 드렸지만, 데이터에 기반한 스토리를 작성하실 때에는 인과관계와 상관관계를 혼동하지 않는 것이 정말로 중요합니다! 시각화한 데이터가 정말로 A ⇒ B라는 인과성을 나타내고 있는지, 아니면 단순한 상관관계를 드러내는 현상인지 확인해 보시는 것이 좋을 것 같아요! 가장 간단한 방법은 위의 종교 부분 예시에서 말씀드린 것처럼, 내가 A ⇒ B라고 확언한 관계가 B ⇒ A라는 문장으로도 말이 된다면 아마도 인과관계와 상관관계가 혼동되었을 가능성이 높습니다!