
데이터 정리 및검토하기
v1? v2? 어떤 걸 활용하지?
v1 [Data_quality] 변수; 1 = 910개, 0 = 3964개
v2 [Data_quality] 변수; 1 = 923개, 0 = 4033개
변수 정리하기
변수명을 [번호. 이름]으로 수정
*음식(1~26), 담배(27) 교통수단(28~35), 공과금(36~38), 문화생활 (39~41), 교육(42~43), 의상(44~47), 주거(48~53), 수입(54~55)
이번 데이터셋은 변수가 엄청 많지는 않았지만.. 더 많을 경우에는..? 코딩을 할 줄 알았으면 쉬웠을까 ㅠ
EDA하기
월급이랑 나머지 변수 간의 상관관계 보기
→ 너무 많아서 한 눈에 알아보기 어려움..
월급 percentile로 보기
(1) 0-20th
→ 크게 눈에 띄는 상관관계에 있는 변수가 없음
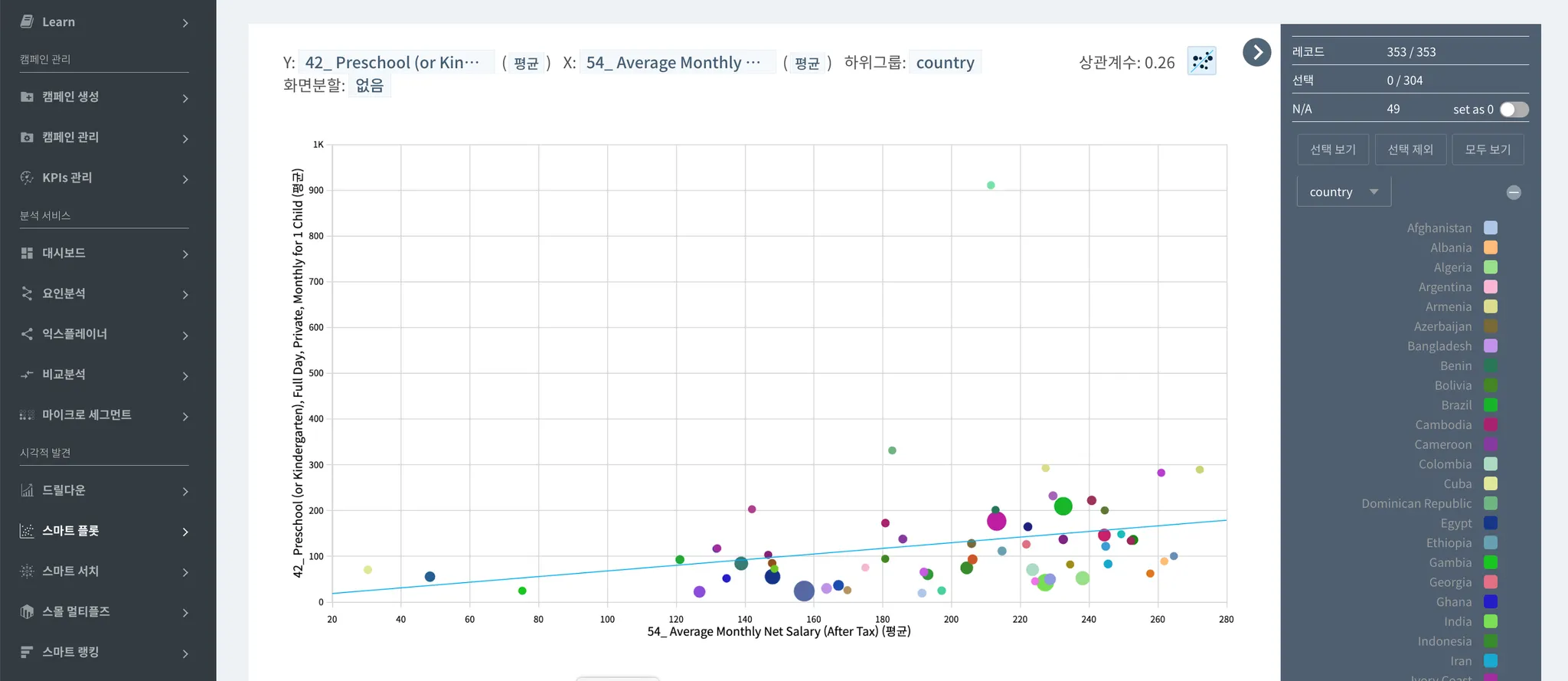
→ 이상치?로 보이는 두 개의 점을 제외하면 상관계수가 올라감
→ 수익이 높아지면서 유치원 교육비는 낮은 경우, NGO 같은 단체로부터 도움을 받는 국가가 많았음 (무상 교육 지원)
→ 다른 방식 시각화
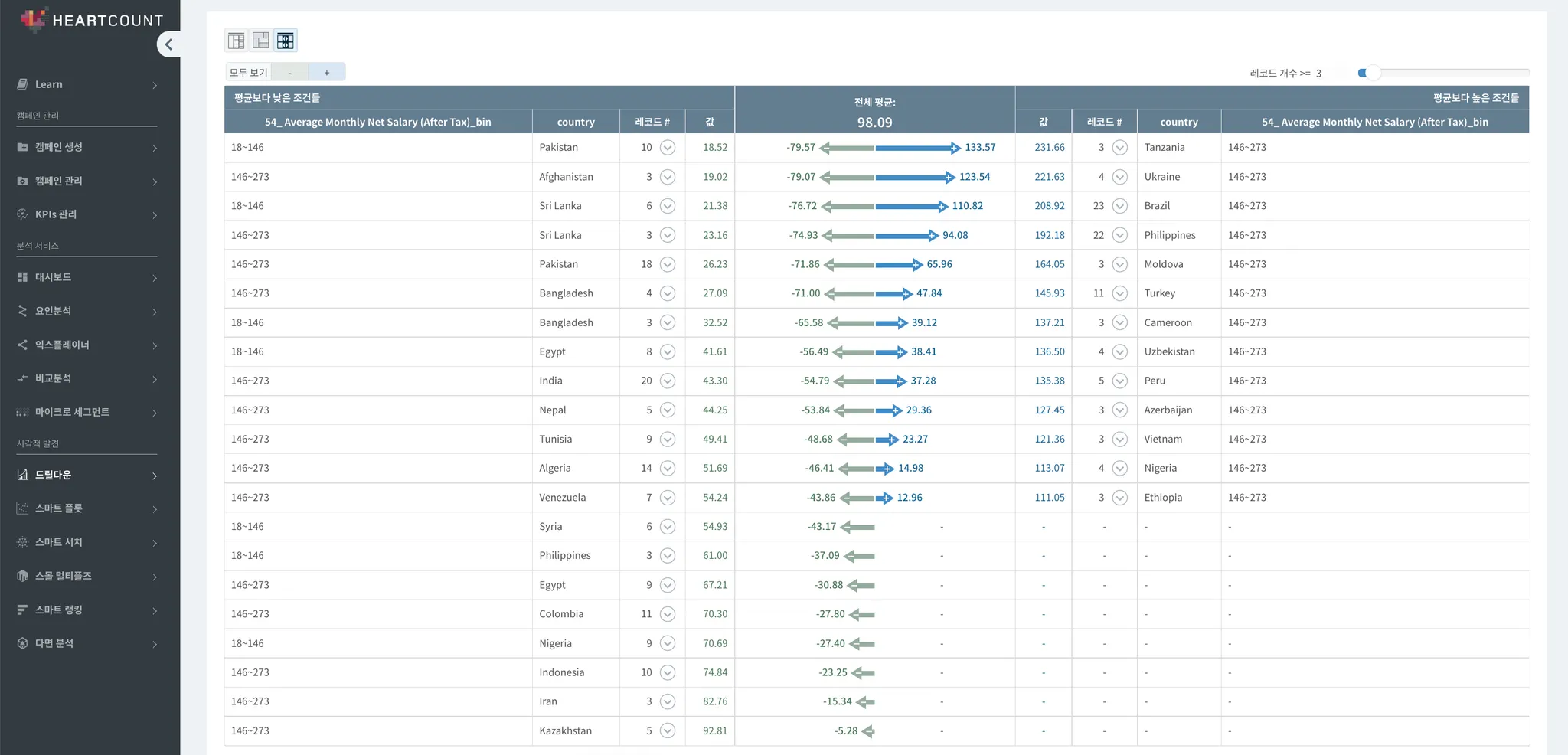
→ 그외 이유로 스리랑카의 경우 교육 복지가 잘 되어 있음

즉, GDP는 낮지만 국가의 교육 관련 복지가 잘 되어 있거나 주변국가의 도움이 있는 경우 유치원 비용이 적게 들었음
→ 상관관계가 높은 것들은 대체로 식음료였으며, 그 중에서도 레스토랑에서 사 먹는 물과 콜라가 높았음 (레스토랑의 물과 콜라가 비싸서 일까?)
→ 재밌는 건 레스토랑에서 먹는 경우를 제외한 주류의 경우 약하지만 음의 상관관계를 보였음
임금의 전체 구간에서 큰 상관관계를 가진 변수가 보이지 않음.. 다시 필터를 풀어 전체 구간으로 보기로 함
(3) 전체 임금 구간
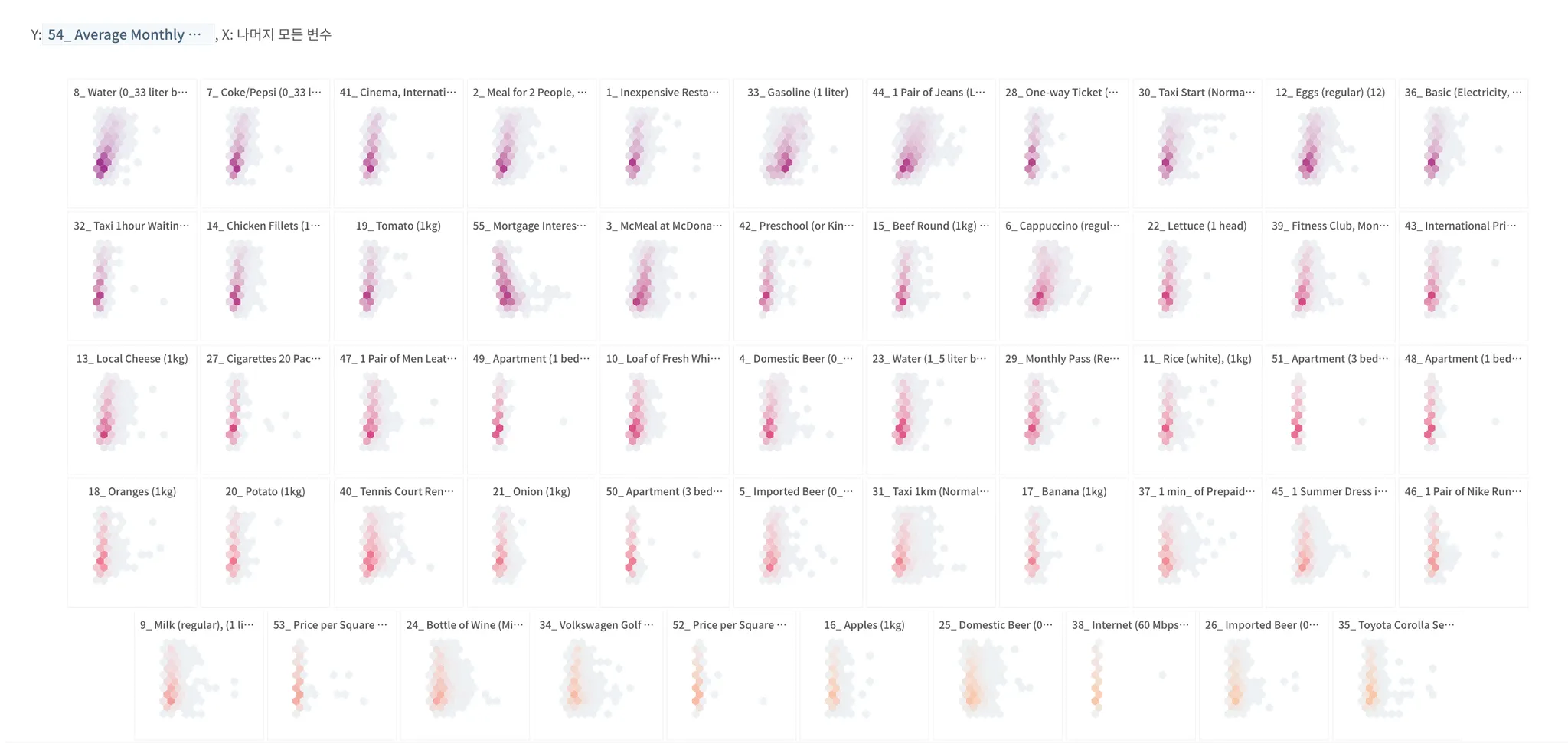
→ 임금 변수를 제외한 나머지 수치형 변수는 총 53개, 상관관계가 높은 순서대로 몇 가지를 살펴 보겠음
→ 음의 상관관계인 변수는 없었음
→ 상위 10
•
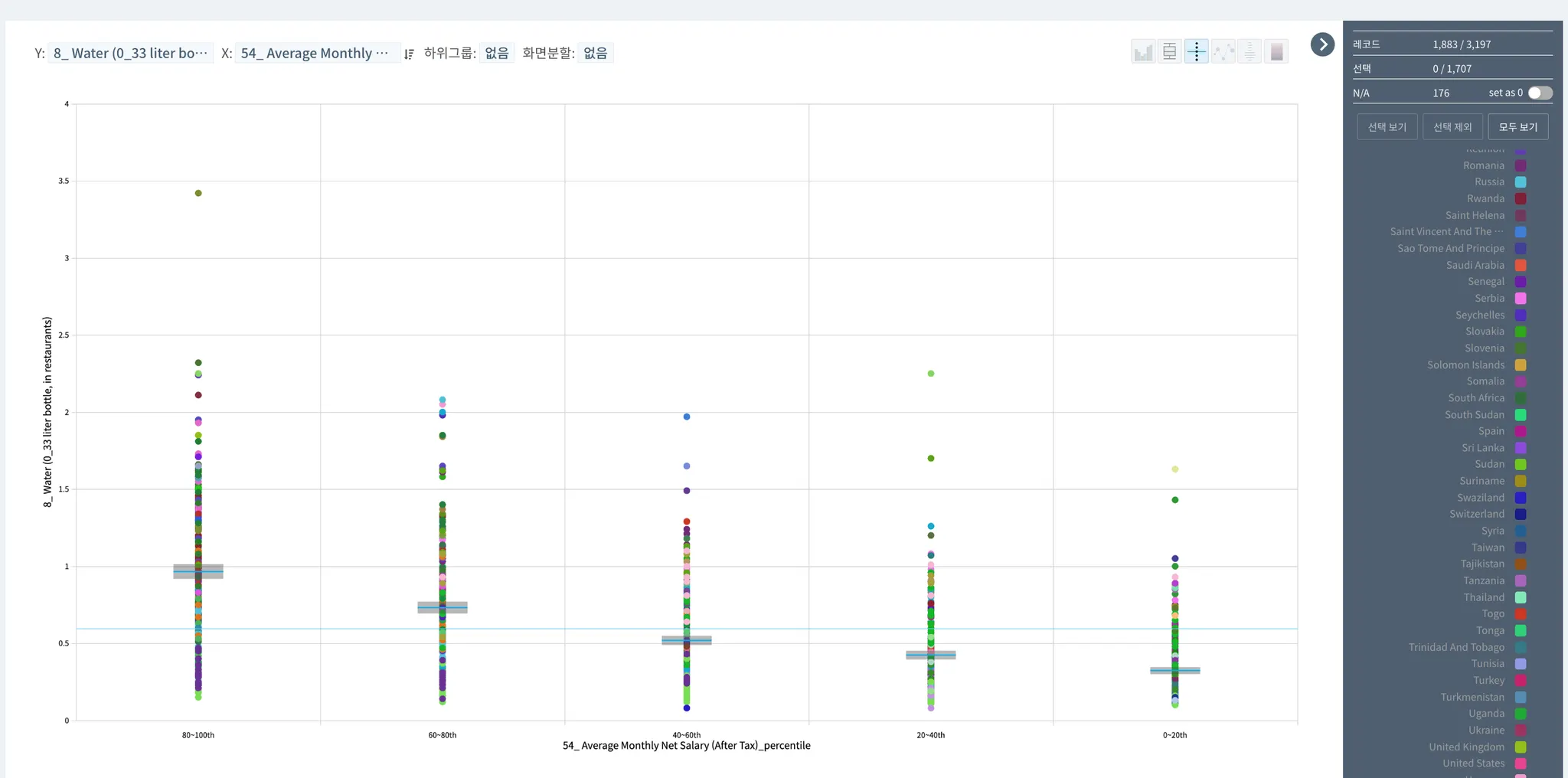
레스토랑에서 사 먹는 물 330 (0.58)
> 임금이 높을수록 분포가 넓음
> 임금은 낮은데 유난히 물이 비싼 국가는 다 남미 혹은 인근에 속한 국가였음
•
레스토랑에서 사 먹는 콜라 330 (0.53)
•
영화 (0.5)
•
중간 수준 레스토랑의 2명 금액 (0.5)
•
비싸지 않은 레스토랑 (0.5)
•
가솔린 (0.49)
•
청바지 (0.48)
•
일회용 대중교통 티켓 (0.47)
•
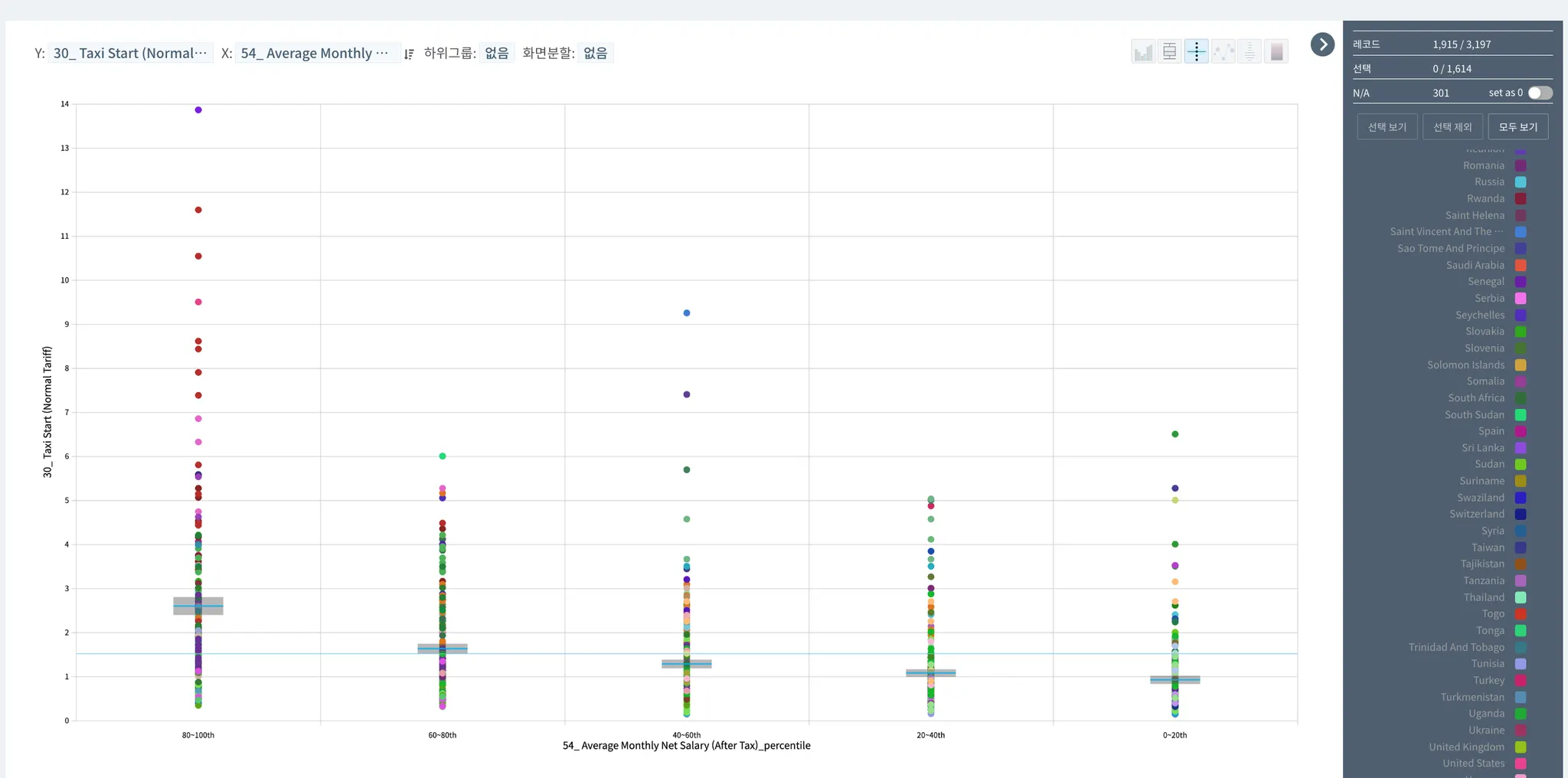
택시 기본 금액 (0.47)
> [80-100th] 퀴라소: 택시로만 이동할 수 있는 장소가 많아서 매우 비싼 듯
> [80-100th] 그 밖에 이탈리아 국가, 이어서 몰타 국가가 상위 차지.
> [40-60th] 세인트빈센트 그레나딘, 돈 많은 귀족이나 유명 스타들이 많이 방문하는 여행지
> 즉 관광객이 많은 경우에 택시비가 비싼 편인 것으로 보임(추측)
•
계란 (0.46)